
大语言模型(Large Language Models, LLMs)的部署是一项具有技术挑战性的工作。随着模型架构日益复杂,以及硬件需求不断提升,部署过程变得愈发复杂。业界已经发展出多种解决方案,使LLM的部署和扩展变得更加便捷。从适用于个人开发的轻量级本地部署工具,到面向企业级高性能生产环境的推理引擎,各类解决方案能够满足不同场景的需求。
本文将深入探讨十种主流LLM服务引擎和工具,系统分析它们在不同应用场景下的技术特点和优势。无论是在消费级硬件上进行模型实验的研究人员,还是在生产环境中部署大规模模型的工程团队,都能从中找到适合的技术方案。
1、WebLLM
WebLLM是一个基于浏览器的高性能LLM推理引擎,其核心特性是利用WebGPU进行硬件加速。这使得Llama 3等大规模模型能够直接在浏览器环境中运行,无需服务器端支持。该架构在保证AI交互实时性的同时,通过模块化设计确保了数据隐私和计算效率。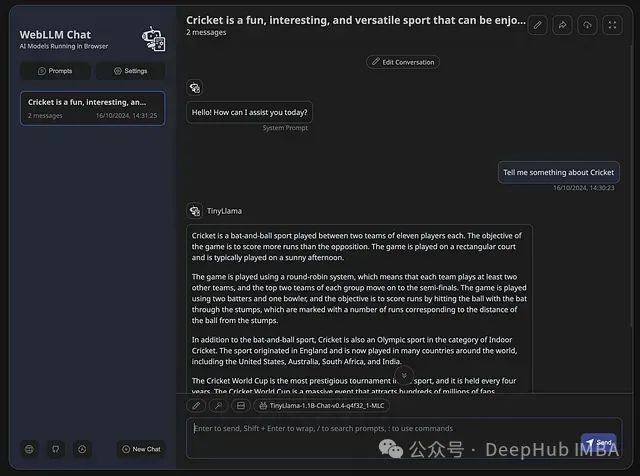
技术特性
- WebGPU加速计算:利用浏览器原生的WebGPU能力实现模型加速
- API兼容性:完整实现OpenAI API规范,支持无缝集成
- 实时数据流:支持流式响应和结构化JSON生成
- 模型适配:广泛支持Llama、Phi、Gemma等主流模型架构
- 自定义模型集成:通过MLC格式支持模型定制
- 并行计算优化:集成Web Worker和Service Worker提升性能
- 浏览器扩展性:支持Chrome扩展开发
技术优势分析
- 无服务器架构:消除了服务器部署和维护成本
- 端侧计算:通过客户端计算保障数据隐私
- 跨平台兼容:基于Web标准实现多平台支持
技术局限性
- 模型支持受限:仅支持适配浏览器环境的模型
- 计算能力约束:受限于客户端硬件性能
2、LM Studio
LM Studio是一个功能完备的本地化LLM运行环境,支持在本地设备上完全离线执行大语言模型。该框架适配多种硬件配置,并提供模型实验和配置功能。通过集成用户友好的对话界面和OpenAI兼容的本地服务器,LM Studio为开发者提供了灵活的模型集成和实验环境。
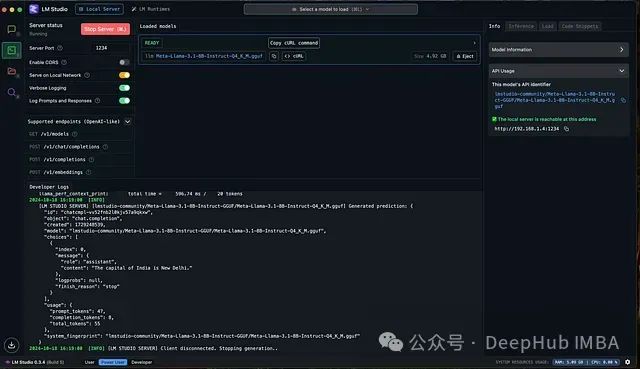
技术实现细节
LM Studio通过
llama.cpp
实现了在Mac、Windows和Linux平台上的模型执行。在搭载Apple Silicon的Mac设备上,还可以通过Apple的ML Compute框架(
_MLX_
)进行模型运行,充分利用了Apple芯片的AI加速能力。
核心功能架构
- 离线计算引擎:实现本地化模型执行,无需网络连接
- 结构化输出系统:支持规范化的JSON格式数据生成
- 多模型并行:支持多个模型的同时运行和任务并行处理
- 文档交互功能:通过内置UI实现本地文档的智能交互(v0.3新增)
- API兼容层:提供OpenAI兼容的本地服务接口
- 模型管理系统:集成Hugging Face生态,简化模型获取和管理流程
LM Studio技术优势
- 本地化推理:提供高速的设备端推理能力,完全离线的GUI操作界面
- 模型资源管理:与Hugging Face平台深度集成,实现高效的模型管理
- 双模交互接口:同时提供对话界面和本地API服务
- 计算资源调度:支持多模型的并行计算和资源调度
技术限制
- 部署范围受限:仅支持桌面环境,不适用于生产级部署
- 模型兼容性:部分模型架构需要额外适配
- 资源需求:大型模型运行需要较高的系统资源配置
- 性能依赖:计算性能受本地硬件条件限制
3、 Ollama
Ollama是一个开源的轻量级LLM服务框架,专注于本地推理能力的实现。其核心设计理念是通过本地化部署提升数据隐私保护和降低推理延迟。该框架为开发者和组织提供了完整的模型管理和推理服务能力,特别适合对数据安全性要求较高的应用场景。
核心技术特性
- 本地推理引擎:实现高效的本地模型推理,优化延迟表现
- 模型生命周期管理:提供完整的模型加载、卸载和切换功能
- 服务接口设计:实现简洁的API架构,便于应用集成
- 多平台兼容性:支持主流操作系统,提供统一的运行环境
- 参数配置系统:支持灵活的模型参数调整和行为定制
技术优势
- 部署便捷性:简化的安装和配置流程
- 应用适配性:适合中小规模项目快速落地
- 模型生态支持:预置多种常用模型支持
- 接口集成性:提供命令行和API双重接入方式
- 配置灵活性:支持模型参数的实验和优化
技术局限
- 模型支持范围:受限于Ollama官方支持的模型
- 硬件依赖性:性能受限于本地计算资源
- 扩展性限制:相比专业推理引擎,在大规模应用场景下的扩展能力有限
部署示例
以下是Ollama的基本部署和使用流程:
# 启动Ollama推理服务
ollama serve
# 拉取指定模型
ollama pull granite-code:8b
# 查看已安装模型列表
ollama list
# 运行模型服务
ollama run granite-code:8b
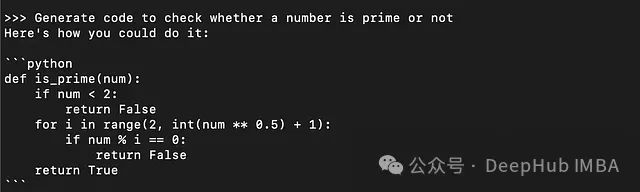
4、vLLM
vLLM(Virtual Large Language Model)是一个专注于高性能推理和服务的开源框架。其核心创新在于PagedAttention技术的应用,实现了高效的内存管理机制。通过连续批处理技术优化GPU利用率,并支持多种量化方法提升推理性能。该框架与OpenAI API兼容,并与Hugging Face生态系统实现了深度集成。

核心技术组件
- PagedAttention内存管理:优化注意力机制的内存使用效率
- 连续批处理系统:实现请求的动态批处理
- 量化加速引擎:支持多种精度的模型量化
- API适配层:提供OpenAI兼容的接口规范
- 分布式计算框架:支持张量并行和流水线并行的分布式推理
- CUDA优化:集成FlashAttention和FlashInfer等高性能CUDA核心
- 模型生态支持:全面支持主流开源模型,包括:- Transformer架构LLMs(如Llama)- 混合专家模型(如Mixtral)- 嵌入模型(如E5-Mistral)- 多模态LLMs(如Pixtral)
vLLM技术优势分析
vLLM框架在设计上充分考虑了生产环境的需求,具有显著的技术优势:
- 生产级性能表现:通过深度优化的推理引擎,实现了业界领先的吞吐量和响应速度
- 架构适应性:灵活支持多种模型架构,便于在不同应用场景中部署
- 开源生态优势:基于开源架构,支持社区贡献和持续优化
- 并发处理能力:优秀的多请求并发处理机制,保证服务稳定性
- 内存效率:通过优化的内存管理,支持在有限硬件资源上运行大规模模型
技术实现细节
以下是vLLM框架在实际应用中的典型实现示例,展示了其在多模态场景下的部署方法:
fromvllmimportLLM
fromvllm.sampling_paramsimportSamplingParams
# 初始化模型配置
model_name="mistralai/Pixtral-12B-2409"
max_img_per_msg=2
# 设置采样参数
sampling_params=SamplingParams(max_tokens=2048)
# 初始化LLM实例,配置关键参数
llm=LLM(
model=model_name,
tokenizer_mode="mistral", # 指定分词器模式
load_format="mistral", # 设置加载格式
config_format="mistral", # 配置文件格式
dtype="bfloat16", # 设置计算精度
max_model_len=8192, # 最大模型长度
gpu_memory_utilization=0.95, # GPU内存利用率
limit_mm_per_prompt= {"image": max_img_per_msg}, # 多模态限制
)
# 设置图像处理参数
image_url="deephub.jpg"
# 构建多模态消息结构
messages= [
{
"role": "user",
"content": [
{"type": "text", "text": "Extract the company name conducting hackathon and then generate a catchy social media caption for the image. Output in JSON format."},
{"type": "image_url", "image_url": {"url": image_url}}
]
}
]
# 执行模型推理
res=llm.chat(messages=messages, sampling_params=sampling_params)
print(res[0].outputs[0].text)
HTTP服务部署
vLLM提供了完整的HTTP服务器实现,支持OpenAI的Completions和Chat API规范。对于Pixtral等视觉-语言模型,服务器完全兼容OpenAI Vision API标准。以下是部署流程:
# 启动服务器实例
vllm serve mistralai/Pixtral-12B-2409 --tokenizer_mode mistral --limit_mm_per_prompt'image=2'
# API调用示例
curl--location'http://localhost:8000/v1/chat/completions' \
--header'Content-Type: application/json' \
--data'{
"model": "mistralai/Pixtral-12B-2409",
"messages": [
{
"role": "user",
"content": [
{"type" : "text", "text": "Describe the content of this image in detail please."},
{"type": "image_url", "image_url": {"url": "https://s3.amazonaws.com/cms.ipressroom.com/338/files/201808/5b894ee1a138352221103195_A680%7Ejogging-edit/A680%7Ejogging-edit_hero.jpg"}}
]
}
]
}'
5、LightLLM
LightLLM是一个基于Python的高效推理框架,其设计融合了FasterTransformer、TGI、vLLM和FlashAttention等成熟开源实现的优势。该框架通过创新的系统架构优化了GPU利用率和内存管理,适用于开发和生产环境。
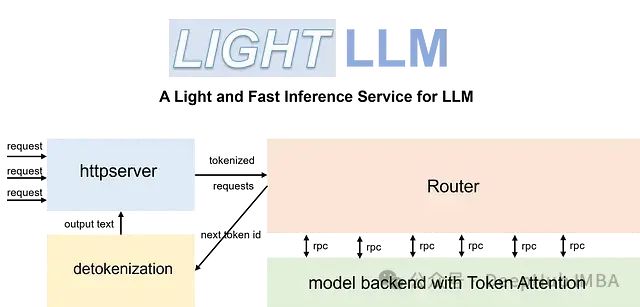
核心技术架构
LightLLM的架构设计基于以下关键技术组件:
- 异步协作处理系统:- 实现分词、模型推理和解码的异步执行- 显著提升GPU利用效率- 优化计算资源分配
- 注意力机制优化:- 实现Nopad(无填充)注意力操作- 高效处理长度差异显著的请求- 支持跨模型的注意力计算优化
- 动态批处理引擎:- 实现请求的动态调度系统- 优化计算资源使用效率- 支持灵活的批处理策略
- 内存管理系统:- 实现基于Token的KV缓存管理- 确保推理过程中的零内存浪费- 提供精细化的GPU内存管理
6、OpenLLM
OpenLLM是一个为大语言模型自托管设计的综合性平台,其核心优势在于简化了大规模语言模型的部署流程。系统实现了对Llama、Qwen、Mistral等主流开源模型的标准化支持,并提供了与OpenAI兼容的API接口。通过与Docker、Kubernetes和BentoCloud的深度集成,OpenLLM建立了一个完整的模型部署和管理生态系统。
系统架构设计
OpenLLM的系统架构基于以下几个核心层次:
- 模型服务层- 实现单命令模型部署功能- 提供标准化的模型加载和初始化流程- 支持模型运行时的动态配置
- API兼容层- 实现OpenAI API规范- 提供统一的接口调用标准- 支持多种开发框架的集成需求
- 部署管理层- 集成容器化部署支持- 实现Kubernetes编排能力- 提供云平台部署接口
- 交互界面层- 实现Web化的交互界面- 提供模型调试和测试功能- 支持实时对话能力
技术实现示例
以下代码展示了OpenLLM的基本部署和使用流程:
fromlangchain_community.llmsimportOpenLLM
# 初始化LLM服务实例
llm=OpenLLM(server_url='http://localhost:3000')
# 执行模型推理
result=llm.invoke("Which is the largest mammal in the world?")
部署流程
# 通过包管理器安装
pip install openllm
# 启动本地服务
openllm serve llama3.1:8b-4bit
系统将自动在
http://localhost:3000/chat
地址提供Web交互界面。
7. HuggingFace TGI
HuggingFace Text Generation Inference (TGI)是一个专为大规模文本生成任务优化的推理框架。该框架在设计时特别关注了推理性能和资源效率,通过深度优化实现了低延迟的文本生成能力。TGI与Hugging Face的模型生态系统紧密集成,为开发者提供了完整的模型部署解决方案。
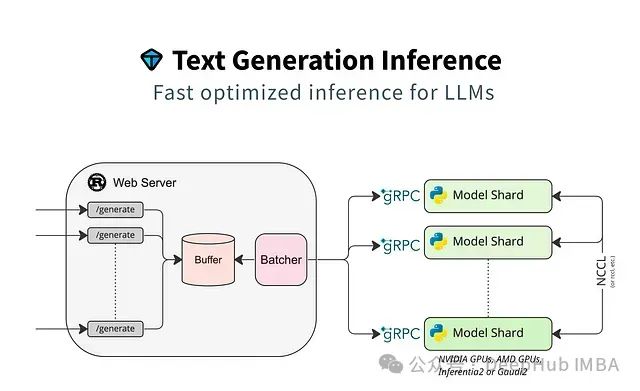
核心技术组件
- 推理引擎优化- 专门针对大规模文本生成任务进行优化- 实现低延迟的推理处理- 支持高并发请求处理
- 模型支持系统- 支持Hugging Face模型库中的主流模型- 包括GPT、BERT等架构- 提供自定义模型支持能力
- 资源调度系统- 实现GPU资源的高效调度- 支持多模型并行服务- 提供自动扩缩容能力
- 可观测性支持- 集成Open Telemetry分布式追踪- 提供Prometheus指标支持- 实现完整的监控体系
模型部署示例
以下代码展示了使用transformers部署TGI服务的过程:
importtransformers
importtorch
# 配置模型参数
model_id="meta-llama/Meta-Llama-3.1-70B-Instruct"
# 初始化推理管道
pipeline=transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto", # 自动设备映射
)
# 构建对话消息
messages= [
{"role": "system", "content": "You are a wise sage who answers all questions with ancient wisdom."},
{"role": "user", "content": "What is the meaning of life?"},
]
# 执行推理
outputs=pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
8、GPT4ALL
GPT4ALL是Nomic开发的一个综合性框架,它既包含了模型系列,也提供了完整的本地训练和部署生态系统。该框架的核心设计理念是实现高效的本地设备推理,同时确保数据隐私安全。系统通过集成Nomic的嵌入模型技术,实现了本地文档的智能交互能力。
技术架构特点
- 本地计算引擎- 支持CPU和GPU的本地推理能力- 实现完全离线的模型执行- 优化的资源调度机制
- 数据安全机制- 全本地化的数据处理流程- 端到端的隐私保护设计- 安全的文档交互系统
- 文档处理系统- 支持PDF、TXT等多种格式- 实现文档信息的智能提取- 本地化的文档索引机制
开发接口实现
以下代码展示了GPT4ALL的Python SDK使用方法:
fromgpt4allimportGPT4All
# 初始化模型(自动下载并加载4.66GB的LLM)
model=GPT4All("Meta-Llama-3-8B-Instruct.Q4_0.gguf")
# 创建对话会话
withmodel.chat_session():
# 执行模型推理,设置最大token数
response=model.generate(
"How does transfer learning work in image classification?",
max_tokens=512
)
9、llama.cpp
llama.cpp是一个高度优化的C/C++实现,专注于本地LLM推理性能的优化。该框架与GGML库深度集成,为多个LLM工具和应用提供了基础运行时支持。系统通过多种优化技术,实现了在不同硬件平台上的高效运行。
核心技术特性
- 计算优化系统- 无外部依赖的独立实现- 针对ARM和x86架构的特定优化- 支持Apple Silicon原生加速
- 量化处理引擎- 支持1.5位到8位的整数量化- 灵活的精度配置选项- 内存使用优化机制
- 多语言绑定支持- 提供Python、Go、Node.js等语言接口- 统一的API设计- 跨平台兼容性支持
部署实现示例
fromllama_cppimportLlama
# 初始化模型实例
llm=Llama(model_path="./path/model.gguf")
# 执行模型推理
output=llm(
"What is artificial intelligence?",
max_tokens=100, # 控制生成长度
stop=["\n"], # 设置停止条件
echo=True # 在输出中包含输入提示
)
# 获取生成结果
response=output["choices"][0]["text"].strip()
10、Triton Inference Server与TensorRT-LLM
NVIDIA的Triton Inference Server配合TensorRT-LLM,构建了一个完整的企业级模型部署方案。该系统通过深度优化,实现了LLM在生产环境中的高性能服务能力。
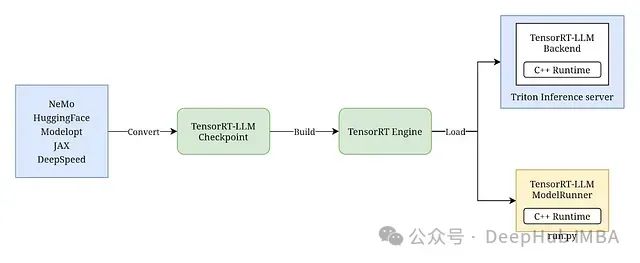
系统核心组件
- 模型优化引擎- TensorRT-LLM模型编译优化- 针对推理性能的专项优化- 高效的计算图优化
- 内存管理系统- 分页注意力机制- 高效的KV缓存实现- 优化的内存分配策略
- 请求调度系统- 动态批处理机制- 智能的负载均衡- 资源动态分配
- 监控与度量系统- 详细的GPU使用监控- 服务性能指标采集- 系统资源使用追踪
技术优势
- 性能优化- 显著提升推理速度- 优化的响应延迟- 高效的资源利用
- 扩展能力- 多GPU横向扩展- 节点间负载均衡- 集群化部署支持
技术总结
大语言模型服务部署方案的选择需要综合考虑以下关键因素:
- 部署场景:从个人开发环境到企业级生产系统,选择合适的部署方案。
- 性能需求:根据延迟、吞吐量等指标选择最适合的技术框架。
- 资源约束:考虑硬件资源限制,选择合适的优化策略。
- 开发难度:评估团队技术能力,选择适合的实现方案。
- 维护成本:考虑长期运维和升级的技术投入。
通过深入理解各个框架的技术特点和适用场景,开发团队可以根据具体需求选择最适合的部署方案,实现大语言模型的高效服务。
作者:Gautam Chutani