
最近这段时间在玩一个叫OmniGen的生成模型,有点意思,跟大家分享一下。

下面,我就先说一下模型的功能特点,然后是安装配置过程,然后说一下如何使用。最后会分享一个配置好的离线运行包。

这样的新娘白送要不要?这是以寡姐和美队为原型生成的图片!
功能特点
OmniGen 是一个统一的图像生成模型,可以执行各种任务,包括但不限于文本生成图像、基于主体驱动的图像生成、身份保持的图像生成,以及基于图像条件的生成。
我觉得他最厉害的地方是,可以一句话把多张图片中的特定人物合成到一张全新的图片中,堪称傻瓜式一键P图神器。完成所有操作只需要一个模型,也是它的一大特色。
下面用官方的几个实例来展示一下这个项目的功能特点。
文生图
通过文字描述直接生成图片,这是所有AI模型必备的功能,他自然也可以。

提示词:
A curly-haired woman in a red shirt is drinking tea.一个穿着红色衬衫的卷发女人正在喝茶。
先不说图片好不好,指令遵循能力还不错。女人对的,卷发对的,茶杯对的,红色衬衫对的。

Asian woman with tied hair in a suit 穿西装的绑头发的亚洲女人
出图效果还可以,就是它默认的人种,不是很中国。
图生图
文生图是常规功能,下面看下它强大的图生图功能。
✨ 给人物换动作和场景

The woman in
<|image_1|> waves her hand happily in the crowd
通过指定图片,然后使用不同的描述,就可以生成同一个人在不同场景中不同动作的照片了。
✨ 把多人照片中特定的人抠出来生成新图
A man in a black shirt is reading a book. The man is the right man in
<|image_1|>.
把两个玩游戏的网瘾少年变成爱看书的好青年,顺便帮他们换上黑色的衣服。
这个过程就是把人抠出来,保持脸部特征的同时,改变他们行为,背景,服装等,同时要保持自然。
✨ 把两张照片中的人合在一起

Two woman are raising fried chicken legs in a bar. A woman is
<|image_1|>. Another woman is
<|image_2|>.
可以从图片中抽取某个人,同时也可以把两个不同图片中的人合在一起。
这个DEMO看起来相当🐂🍺啊,应该是抽卡抽了很久才抽到效果这么好的。
✨ 从多人中挑选两个人生成新图

A man and a short-haired woman with a wrinkled face are standing in front of a bookshelf in a library. The man is the man in the middle of
<|image_1|>, and the woman is oldest woman in
<|image_2|>
这个例子很好的展示了这个项目的实例。单纯通过描述,就可以把特定的人选出来,然后拼到一起。
✨ 根据图片规律进行推理生成

According to the following examples, generate an output for the input.
Input:
<|image_1|>
Output:
<|image_2|>
Input:
<|image_3|>
Output:
模型能正确理解黄左到黄右的变化,然后在给出红左的时候,可以自动生成红右。也就是说模型能够做基于图片的推理,这特性也是有点强啊。
除了上面的例子外,还有很多例子。比如:
✨ 删除图片中的物体
✨ 直接通过人物姿态或者深度图生成不同的人
✨ 生成骨骼图,通过骨骼图和描述生成新图
✨ 根据提示标注物体
考虑到文章篇幅,不展开说了。
反正相比以往的A绘画模型,这个模型是有点新东西的。它主要简化了很多步骤,把各种操作都放在一个模型里面了。你只要给出描述,它就直接帮你完成。
P图神器啊!
介绍就说这些,下面来说下安装配置。这里的安装配置是指,直接获取源代码进行安装,配置,运行。有一定门槛,如果觉得难,可以直接拉到文末,获取制作好的离线软件包。
安装
这个软件项目的配置还是算比较简单,并没有遇到太多坑。主要是基础的软件硬件要先准备好。
- 硬件上需要英伟达大显存的独立显卡
- 操作系统是Windows11
- 用到的软件有git, miniconda
只要硬件到位,其他就很好解决。我自己配置时候用的是RTX3060 12G,推荐3090或者4090这种大显存的显卡。有A系列H系列的,就不用我说了...
使用
下面以我提供的离线软件包,做一个使用演示。
软件是一个7z格式的压缩包,需要先解压,解压之后如下。
点击run.bat直接启动,电脑默认不显示.bat后缀,不影响使用。
然后弹出一个黑色窗口,开始加载模型。
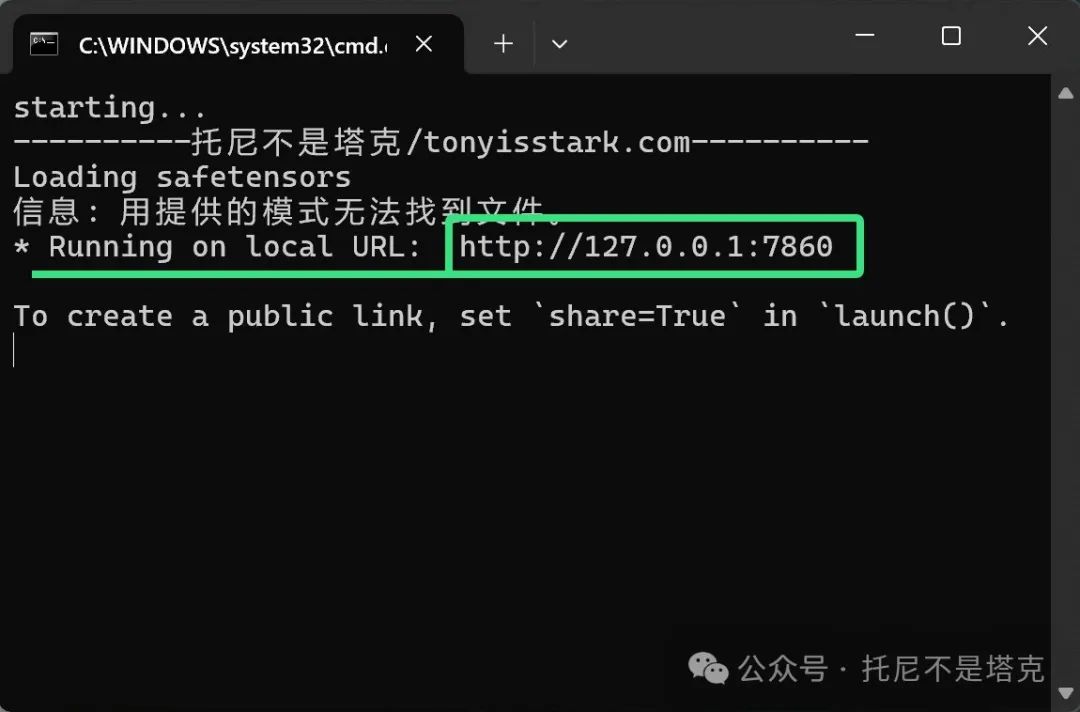
启动的时候会直接把模型读入到内存。由于模型较大,所以需要一些时间。具体的时间和你硬盘的读写速度高度相关。另外确保电脑有足够的内存。推荐是32GB起步!
启动完成之后,一般会自动打开浏览器。如果没有,可以手动打开,复制上面的http网址。
打开之后,界面如下:

1️⃣ 用于输入文字
2️⃣用于上传图片作为输入
3️⃣生成结果显示区域。
提示词的构成如下:
A man and a short-haired woman with a wrinkled face are standing in front of a bookshelf in a library. The man is the man in the middle of
<|image_1|>, and the woman is oldest woman in
<|image_2|>
重点关注:
<|image_2|>
这个内容代表的是下面的第二张图片。目前总共可以上传三张图片。
也就是:
<|image_1|>
<|image_2|>
<|image_3|>
在需要引用图片内容的区域插入这个标识就好了。
在下方还有一些参数:

✨高度宽度,指的是生成图片的尺寸,1024x1024效果会比较好,高清!
✨引导强度,指的是你的文字描述和参考图片对结果控制力的强弱,越大越强!
✨ 迭代步数, 在生成图像时,可以调整步数来控制细节质量,通常在 20-50 步之间效果最佳。
✨种子, 用于控制随机生成过程的初始值。设置相同的种子值可以确保多次生成结果一致,便于复现特定图像效果。
✨最大输入尺寸,这个应该是用来限制输入图片的最大的尺寸的。
✨seprate_cfg_inter , 勾选这个可以降低显存需求,一般勾上。
✨模型卸载到CPU,进一步减低显存需求,但是速度会明显变慢,显存够不要勾。
✨将输入图像尺寸用作输出,自动调整输出图像大小与输入图像大小相同。对于编辑和控制任务,它可以确保输出图像与输入图像具有相同的大小,从而获得更好的性能
设置好文字内容,图片,参数之后,点击生成图片(generate Image),界面上和命令界面都会显示进度。

处理过程大概需要几分钟时间!
图生图12G显存不太够用,会使用共享GPU,就会慢很多,但是不会炸,只是慢而已。
最好是用24G+的显卡!
生成之后,可以在界面上看到效果。
另外,勾选保持图片的话,会自动把图片保存到outputs文件夹里面(推荐勾选)
手头没有图片,不知道如何填写提示词的可以拉到网页下面。有一个example列表,只要点击其中任意一项,会根据选择内容自动填充提示词,图片,参数。然后直接点击生成图片就可以了。
然后可以在这个基础上修改提示词,切换图片,调整参数,再生成新的图片。
介绍,安装,使用,全部讲完了。
这个项目除了手部处理一般,生成时间略长之外,还是有很大的可玩性!
保持人物脸部特征不变,改变背景,改变动作,这个肯定有人会需要!
人物特征保持方面不是每次都100%像,但是如果你给他一张高质量的图片,它也能还给你一张。基于这个特性也可以进行“参考创造”。
把不同人很自然的人拼在一起,这个应该也会有很多应用场景。
下载
直接获取软件:点击下载
版权归原作者 牛马尼格 所有, 如有侵权,请联系我们删除。