GEO数据挖掘(一)基础介绍
GEO数据挖掘,火山图,热图,主成分分析
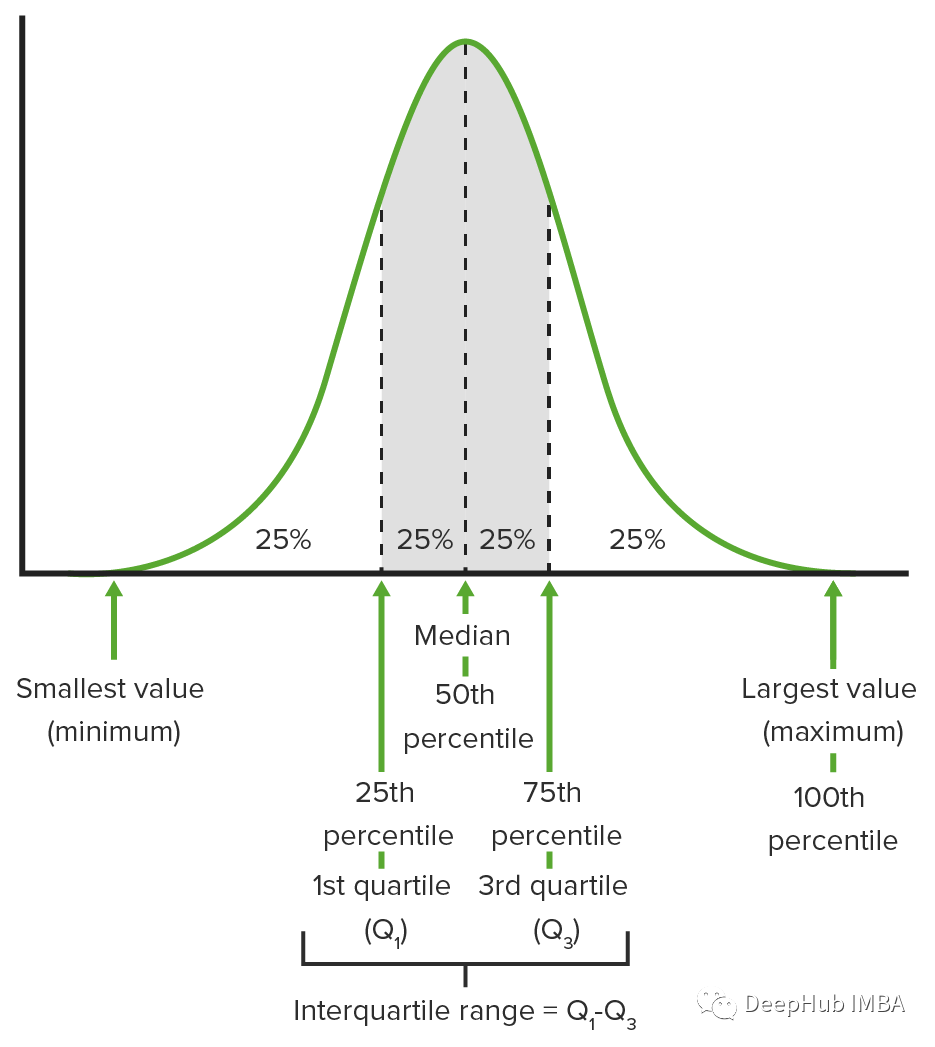
数据信息汇总的7种基本技术总结
数据汇总是一个将原始数据简化为其主要成分或特征的过程,使其更容易理解、可视化和分析。本文介绍总结数据的七种重要方法,有助于理解数据实质的内容。
统计分析——回归分析
在大数据分析中,回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
《数据挖掘基础》实验:Weka平台实现关联规则挖掘
Weka平台实现关联规则挖掘:进一步理解关联规则算法(Apriori算法、FP-tree算法),利用weka实现数据集的挖掘处理,学会调整模型参数,读懂挖掘规则,解释规则的含义
余弦相似度算法进行客户流失分类预测
余弦相似性是一种用于计算两个向量之间相似度的方法,常被用于文本分类和信息检索领域。
【2023年第十一届泰迪杯数据挖掘挑战赛】B题:产品订单的数据分析与需求预测 建模及python代码详解 问题二
在此任务中,首先,读取训练集和预测集数据,并将训练集中的日期列转换为日期类型,并将其设置为数据集的索引。接着,将数据按照一定的维度进行分组,并将每个组的时间序列进行了平稳性检验,若不平稳则进行一阶或者多阶差分,直到序列平稳。基于问题一的分析,建立数学模型,对附件预测数据(predict_sku1.c
第十一届“泰迪杯”数据挖掘挑战赛(B题:产品订单的数据分析与需求预测)
2. 基于上述分析,建立数学模型,对附件预测数据(predict_sku1.csv)中给出的产品,预测未来3月(即2019年1月、2月、3月)的月需求量,将预测结果按照表3的格式保存为文件result1.xlsx,与论文一起提交。(2) 产品所在区域对需求量的影响,以及不同区域的产品需求量有何特性;

参数与非参数检验:理解差异并正确使用
数据科学是一个快速发展的领域,它在很大程度上依赖于统计技术来分析和理解复杂的数据集。这个过程的一个关键部分是假设检验,它有助于确定从样本中获得的结果是否可以推广到总体。
第十一届泰迪杯B题:产品订单的数据分析与需求预测
2. 基于上述分析,建立数学模型,对附件预测数据(predict_sku1.csv)中给出的产品,预测未来3月(即2019年1月、2月、3月)的月需求量,将预测结果按照表3的格式保存为文件result1.xlsx,与论文一起提交。附件中的预测数据(predict_sku1.csv)提供了需要预测产品
【第十一届“泰迪杯”数据挖掘挑战赛】B题产品订单的数据分析与需求预测“解题思路“”以及“代码分享”
此题我们需要分析:不同大品类2015到2018年需求量分析、不同细分品类2015到2018年需求量分析从而得出不同点与共同点。首先需要对日期进行判断月初、月中、月末区间,打上标签,再根据标签进行分组(注意:数据中2018的12月没有月末区间数据)先对每天的需求量进行统计,再进行对数据季节打标签处理,
【数据分析实战】基于python对酒店预订需求进行分析
在本文中,我们基于python对酒店预订需求进行分析,并从多种角度对其展开了探索性的工作。
数据分析实战<一>脑电(EEG)分析
脑电EEG
2023年泰迪杯数据挖掘挑战赛B题--产品订单数据分析与需求预测(1.数据处理)
本题相对来说比较适合新手,包括针对数据的预处理,数据分析,特征提取以及模型训练等多个步骤,完整的做下来是可以学到很多东西的。
通过 Colab 下载 Google Driver 上的大文件到内网服务器
快速下载 Google Drive 上的大文件
SPSS:主成分分析确定不同指标权重
SPSS实现主成分分析确定指标权重
52_Pandas处理日期和时间列(字符串转换、日期提取等)
将解释如何操作表示 pandas.DataFrame 的日期和时间(日期和时间)的列。字符串与 datetime64[ns] 类型的相互转换,将日期和时间提取为数字的方法等。以下内容进行说明。
探究大语言模型(LLM):让ChatGPT火爆的背后
ChatGPT作为一款大型的语言模型,其多层次、多粒度的设计和预训练+微调的模型训练方式使得其在自然语言处理领域具有非常高的应用价值和前景。随着技术的不断进步,ChatGPT等大型语言模型的应用将不断扩大和普及。
二分类及多分类ROC和PR曲线绘制
二分类及多分类ROC曲线的绘制二分类及多分类PR曲线的绘制
R语言-dnorm-pnorm-qnorm-rnorm的区别
R语言 dnorm, pnorm, qnorm, rnorm的区别前言dnorm, pnorm, qnorm, rnorm 是R语言中常用的正态分布函数. norm 指的是正态分布(也可以叫高斯分布(normal distribution)), R语言中也有其他不同的分布操作也都类似. p q d
【数据分析实战】基于python对Airbnb房源进行数据分析
在本文中,我们基于Airbnb房源进行了数据分析,并从多种角度对其展开了探索性的工作,这对于养成数据分析习惯有很大的帮助。



