
实验目的
进一步理解关联规则算法(Apriori算法、FP-tree算法),利用weka实现数据集的挖掘处理,学会调整模型参数,读懂挖掘规则,解释规则的含义
实验要求
(1)随机选取数据集为对象,完成以下内容:(用两种方法:Apriori算法、FP-tree算法)
- 文件导入与编辑;
- 参数设置说明;
- 结果截图;
- 结果分析与对比。
(2)以下表,做关联规则挖掘
TID****ItemsT1{牛奶,面包}T2{面包,尿布,啤酒,鸡蛋}T3{牛奶,尿布,啤酒,可乐}T4{面包,牛奶,尿布,啤酒}T5{面包,牛奶,尿布,可乐}T6{牛奶,尿布,啤酒}T7{尿布,啤酒}T8{面包,牛奶,尿布}
- 文件生成与编辑;
- 参数设置说明;
- 结果截图;
- 结果分析。
supermarket数据实验过程
1. 文件导入与编辑
用“Explorer”打开“supermarket.arff”,如图1.1所示,打开的数据为离散型数据,可直接进行关联规则分析,切换到“Associate”选项卡进行分析。
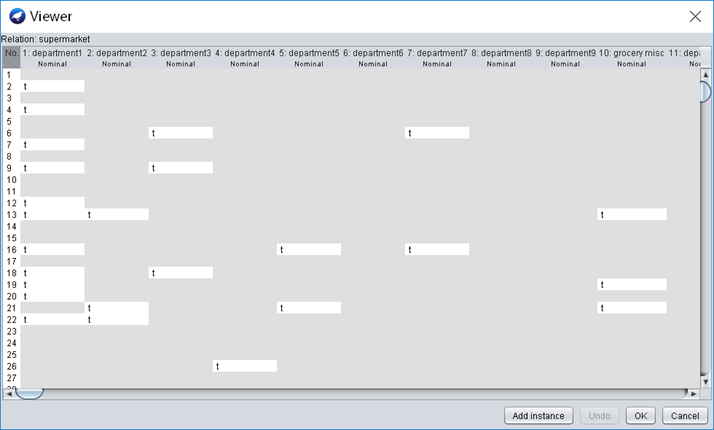
图1.1 supermarket数据集
2. 参数设置说明
2.1 参数说明
- car:如果设为真,则会挖掘类关联规则而不是全局关联规则。
- classindex:类属性索引。如果设置为-1,最后的属性被当作类属性。
- Delta:以此数值为迭代递减单位。不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。
- lowerBounfMinSupport:最小支持度下界
- merticType:度量类型,设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),平衡度(leverage),确信度(conviction)。
- MinMtric:度量的最小值
- numRules:要发现的规则数
- outputItemSets: 如果设置为真,会在结果中输出项集。
- removeAllMissingCols: 移除全部为缺失值的列。
- significanceLevel :重要程度。重要性测试(仅用于置信度)。
- upperBoundMinSupport: 最小支持度上界。 从这个值开始迭代减小最小支持度。
- verbose: 如果设置为真,则算法会以冗余模式运行。
2.2 参数设置
挖掘支持度在10%到100%之间,并且置信度超过0.9且置信度排在前10位的关联规则。
- “lowerBoundMinSupport”和“upperBoundMinSupport”分别设为0.1和1
- “metricType”设为confidence
- “minMetric”设为0.9
- “numRules”设为10
Apriori方法参数设置如下图2.2.1所示。
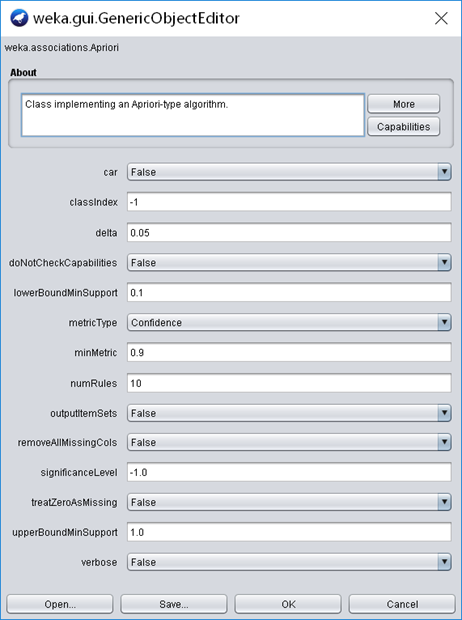
图2.2.1 Apriori方法参数设置图
FP-tree方法参数设置如下图2.2.2所示。
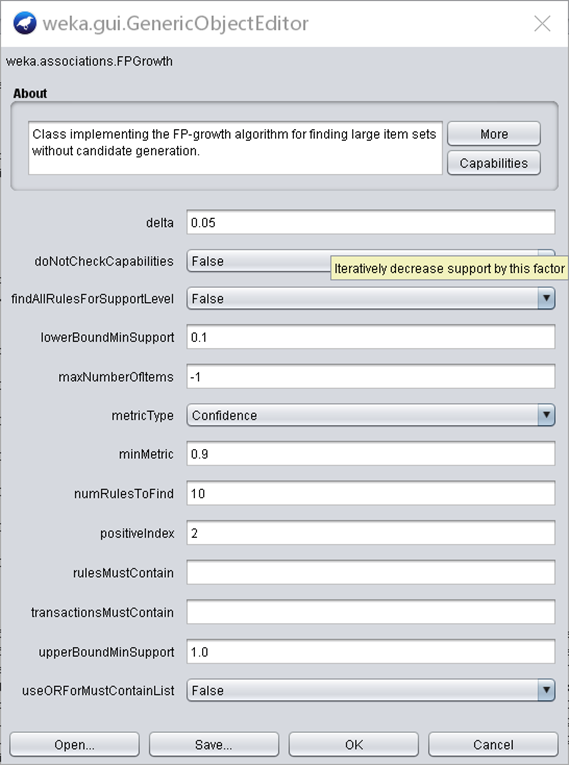
图2.2.2 FP-tree方法参数设置图
3. 结果截图
参数设定完成后单击start按钮,weka开始进行关联规则分析,Apriori算法结果如图3.1所示,FP-tree算法结果如图3.2所示。
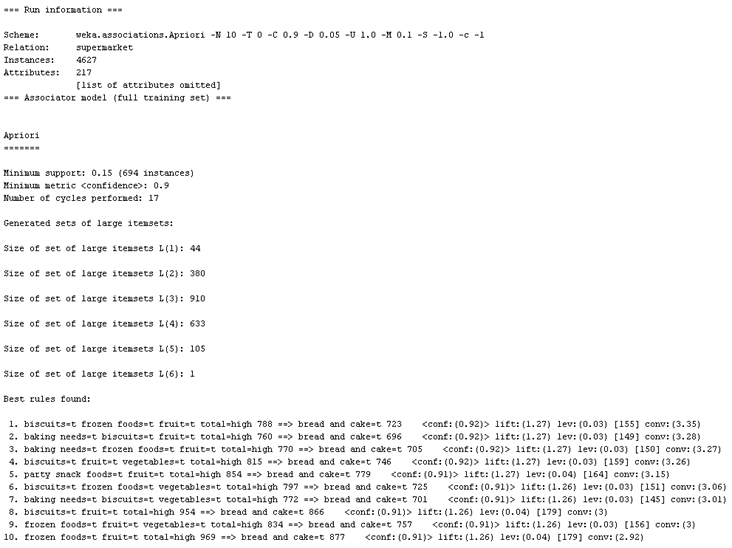
图3.1 Apriori方法结果

图3.2 FP-tree方法结果
将Apriori方法中参数outputItemSets设置为TRUE,部分运行结果如图3.3所示。

图3.3 一频繁项目集
4. 结果分析
从图3.1,3.2中看出,挖掘出的前十条强关联规则中最大的置信度为0.92,其中一条是:biscuits=t frozen foods=t fruit=t total=high ==> bread and cake=t,图3.1显示一、二、三、四、五、六级频繁项目集在最小支持度为0.1的情况下分别有44,380,910,633,105,1个。
观察图3.3可以看到,相比较于图3.1,结果图中展示出了各级频繁项目集的详细信息。观察图3.1和3.2两种挖掘算法的结果图,可以看出两个算法在数据集以及设置参数一样的情况下,挖掘出的关联规则是相同的。
在运行过程中可以观察到在用Apriori算法挖掘关联规则时,程序右下方的小鸟动了3-4次,而FP-Tree算法挖掘时,小鸟只动了1次。小鸟动的次数直观的体现出程序的运行时间,由此可见在用Apriori做关联规则挖掘时要比FP-Tree算法多耗费2-3倍的时间。但又由图3.1,图3.3可以看出,Apriori挖掘出的结果信息可根据需求得到更详细的信息。
表格数据实验过程
1. 文件生成与编辑
将已给数据集进行处理,如图1.1所示,并将该数据集写入到csv文件中。
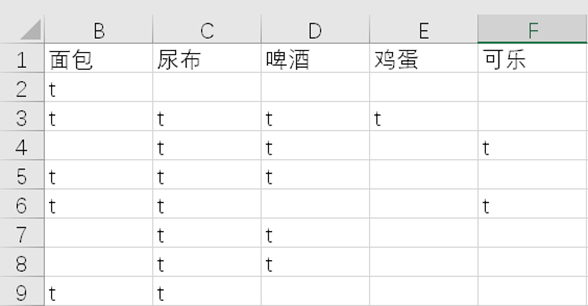
图1.1 处理后的数据集
用weka的open file导入处理后的数据集,如图1.2所示。

图1.2 打开处理后的数据集
看到数据集的文字部分是乱码的。打开weka安装目录,找到RunWeka.ini配置文件,找到fileEncoding=Cp1252,改成fileEncoding=Cp936(图1.3),点击保存关闭,再重新打开weka即可。
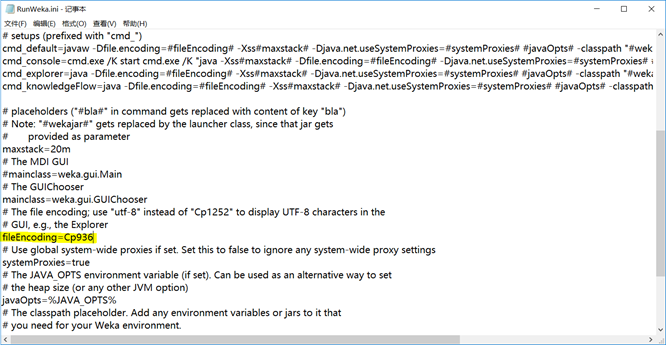
图1.3 修改配置文件
重新打开weka,并导入数据,如图1.4所示,可看到中文显示正常。

图1.4 重新的打开数据集
2. 参数设置说明
设置最小支持度下界为0.4,最小置信度为0.6,挖掘规则数为10。
Apriori方法参数设置如图2.1所示。
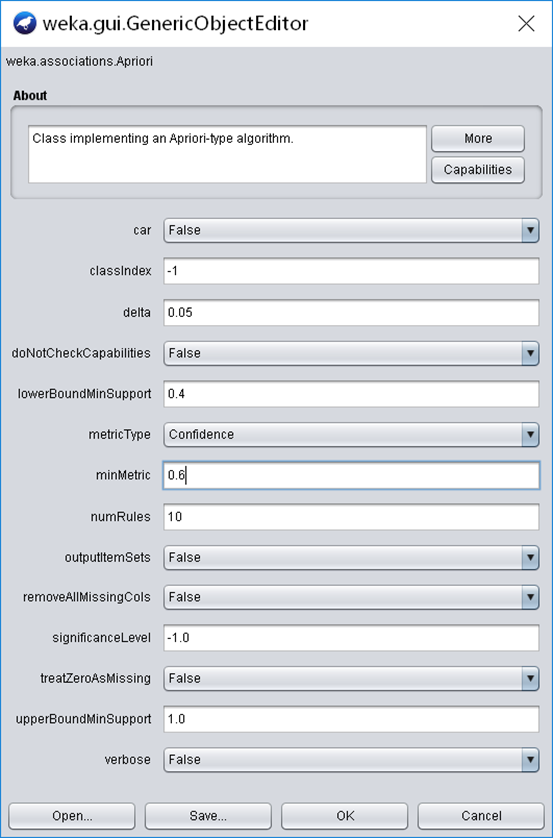
图2.1 Apriori方法参数设置
FP-tree方法参数设置如图2.2所示。
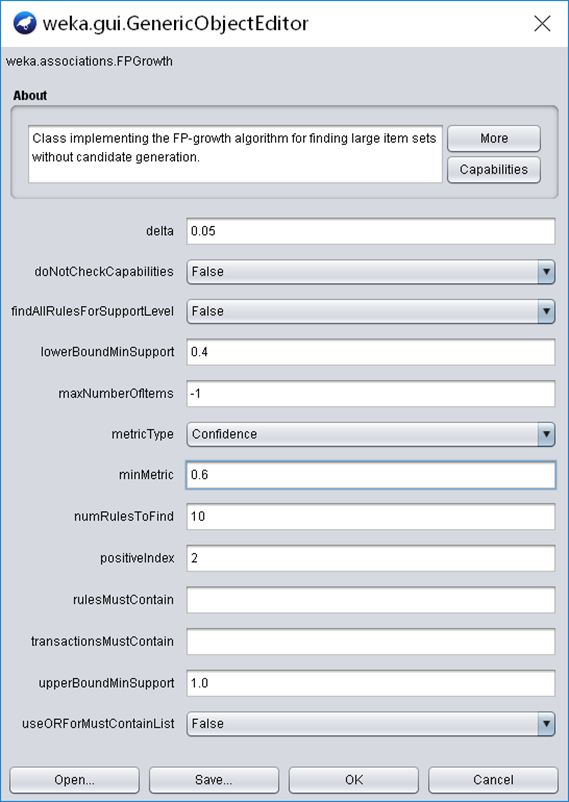
图2.2 FP-tree参数设置
3. 结果截图
参数设定完成后单击start按钮,weka开始进行关联规则分析,Apriori算法结果如图3.1所示,FP-tree算法结果如图3.2所示。

图3.1 Apriori方法结果

图3.2 FP-tree方法结果
4. 结果分析
观察图3.1,可以看到用Apriori算法挖掘出一、二、三级频繁项目集分别为4,5,2个,没有生成四级频繁项目集。挖掘出两条置信度最大为1的强关联规则,分别为:啤酒 -> 尿布;牛奶,啤酒 -> 尿布。
观察图3.2,可以看到用FP-tree算法挖掘出7条强关联规则,其中有一条置信度最大为1的强关联规则为:啤酒 -> 尿布。
版权归原作者 lazyn 所有, 如有侵权,请联系我们删除。