
Pandas是机器学习中最常用的一个库了,我们基本上每天都会使用它。而pandas使用了一个“NumPy”作为后端,这个我们也都是知道的,但是最近 Pandas 2.0 的RC版已经最近发布了。这个版本主要包括bug修复、性能改进和增加Apache Arrow后端。当涉及到使用DF时,Arrow比Numpy提供了更多的优势。
PyArrow可以有效地处理内存中的数据结构。它可以提供一种标准化的方式来表示复杂的数据结构,特别是在大数据环境中的数据结构,并且使不同应用程序和系统之间的数据交换更容易。
在本文中,我们将做一个简单的介绍和评测,为什么pandas选择Arrow作为后端,以及如何在pandas 2.0中开始使用Arrow(它虽然不是默认选项)。

Pandas < 2.0和Pandas 2.0有什么不同呢?Pandas 2.0,不仅支持NumPy作为后端,还支持PyArrow。
建议新开启一个新虚拟环境作为测试,首先安装
pip install pandas==2.0.0rc0
pip install pyarrow
然后可以查看版本:
import pandas as pd
print(pd.__version__)
Arrow后端
因为不是默认,所以我们在使用Arrow时,还要显式的指定:
>>> pd.Series([5, 6, 7, 8], dtype='int64[pyarrow]')
0 5
1 6
2 7
3 8
dtype: int64[pyarrow]
可以看到,现在dtype参数已经是Arrow了。数据类型也变为了int64[pyarrow],而不是我们在使用Numpy时的int64。
我们还可以默认设置Arrow
import pandas as pd
pd.options.mode.dtype_backend = 'pyarrow'
这是RC版本,在未来中还很有可能发生变化,比如想使用PyArrow读取CSV,则必须使用下面的代码。
import pandas as pd
pd.options.mode.dtype_backend = 'pyarrow'
pd.read_csv("file_name.csv", engine='pyarrow', use_nullable_dtypes=True)
速度对比
根据官方的介绍我们都知道,使用Arrow主要就是提高了速度,那么我们来做一个简单的测试:
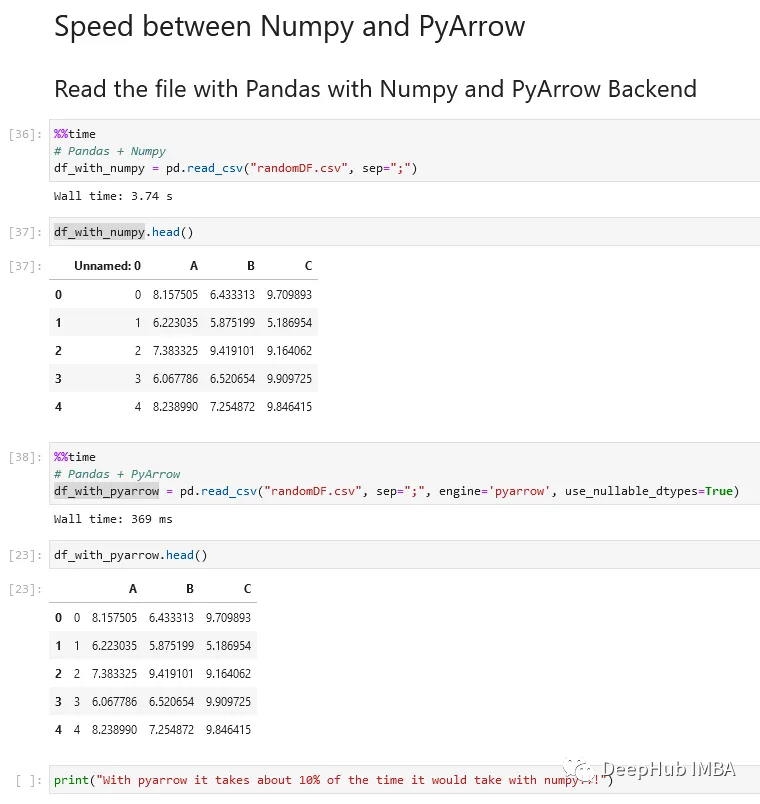
使用NumPy和PyArrow的读取相同的CSV文件,比较两者的差异。
%%time
# Pandas + Numpy
df_with_numpy = pd.read_csv("randomDF.csv", sep=";")
%%time
# Pandas + PyArrow
df_with_pyarrow = pd.read_csv("randomDF.csv", sep=";", engine='pyarrow', use_nullable_dtypes=True)
通过执行这几行代码,我们将看到PyArrow只需要NumPy大约10%的时间!
我们再看看其他的测试,比如读取parquet 文件,求和、平均等:
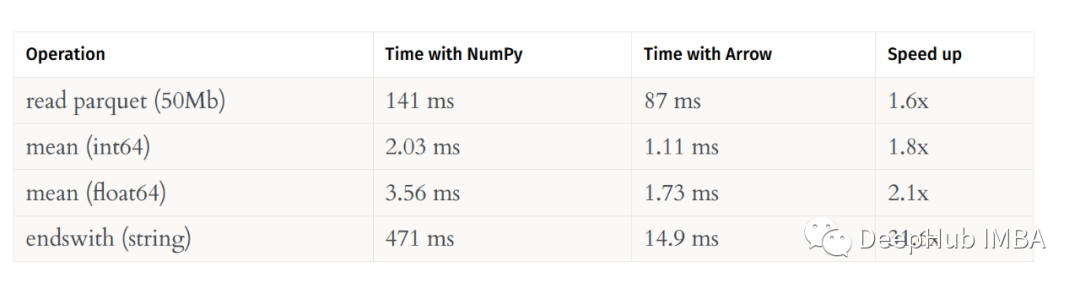
以上测试结果来自这里:https://datapythonista.me/blog/pandas-20-and-the-arrow-revolution-part-i
可以看到Arrow总是更快。并且在处理字符串的情况下,差异更大,这也很好理解,因为NumPy实际上并不是为处理字符串而设计的(虽然它可以支持字符串)。
Pandas 2.0的一些优点
1、速度
这个应该不必多说了,借助Arrow的优势,上面看到已经快了很多
2、缺失值
pandas表示缺失值的方法是将数字转换为浮点数,并使用NaN作为缺失值。
>>> pd.Series([5, 6, 7, None])
0 5
1 6
2 7
3 NaN
dtype: float64
这并不是最好的解决方案,因为NaN也是带有类型的,比如Int的NaN和float64的NaN在某些方面还是不一样的。而Arrow可以处理缺失的值,让我们看看同样的例子,但现在使用Arrow支持的类型。
pd.Series([5, 6, 7, None], dtype='int64[pyarrow]')
0 5
1 6
2 7
3 <NA>
dtype: int64[pyarrow]
3、互操作性
就像CSV文件可以用pandas读取或在Excel中打开一样,Arrow也可以通过R、Spark和Polars等不同程序访问。
这样做的好处是,在这些程序之间共享数据是简单、快速和高效的内存。
4、Copy-on-Write
这是一种内存优化技术,用于提高处理大型数据集时的性能并减少内存使用。
工作原理大致如下:你复制pandas对象时,如DataFrame或Series,不是立即创建数据的新副本,pandas将创建对原始数据的引用,并推迟创建新副本,直到你以某种方式修改数据。
这意味着如果有相同数据的多个副本,它们都可以引用相同的内存,直到对其中一个进行更改。这种方式可以显著减少内存使用并提高性能,因为不需要对数据进行不必要的复制。
5、更好的索引、更快的访问和计算
索引现在可以是NumPy数字类型,Pandas 2.0允许索引保存为任何NumPy数字类型的dtype,包括int8, int16, int32, int64, uint8, uint16, uint32, uint64, float32,和float64。在2.0以前只支持int64、uint64和float64类型。
这样的话也可以节省内存空间提高计算效率。
总结
虽然Pandas 2.0的正式版还没有发布,在pandas 2.0中加入Arrow后端标志着该库的一个重大进步。通过Arrow实现提供了更快、更高效的内存操作,pandas现在可以更好地处理复杂而广泛的数据集。
正式版还没有发布,所以本文的内容也可能与发布的正式版有所出入。我们这里也只是做了一个简单的评测,等待正式版发布以后我们再做更详细的对比和介绍。