加载预训练模型遇到transformers的问题
问题1: urllib.error.URLError: urlopen error [SSL: CERTIFICATE_VERIFY_FAILED]这是由于ssl验证的问题,在.py 文件的开头导入ssl包,创建默认验证:import sslssl._create_default_https_con
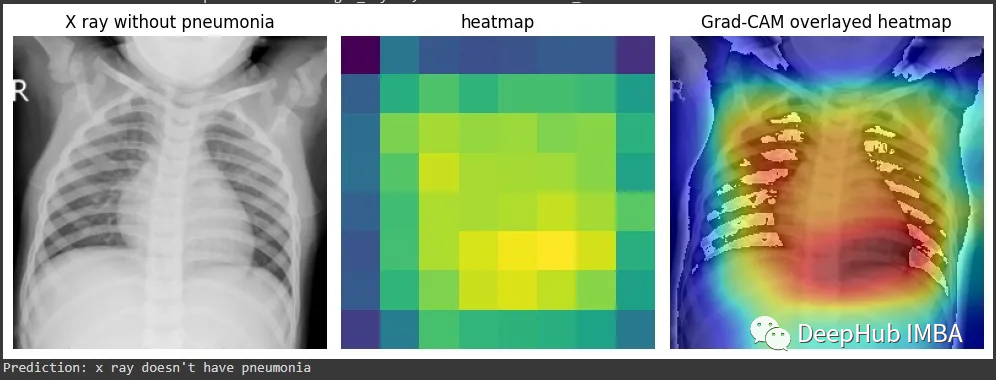
Grad-CAM的详细介绍和Pytorch代码实现
Grad-CAM (Gradient-weighted Class Activation Mapping) 是一种可视化深度神经网络中哪些部分对于预测结果贡献最大的技术。它能够定位到特定的图像区域,从而使得神经网络的决策过程更加可解释和可视化。
DenseNet代码复现+超详细注释(PyTorch)
DenseNet代码复现(PyTorch),每一行都有超详细注释,新手小白都能看懂,亲测可运行
亲测有效解决torch.cuda.is_available()返回False的问题(分析+多种方案),点进不亏
文章目录解决torch.cuda.is_available()返回False出现返回False的原因问题1:版本不匹配问题2:错下成了cpu版本的(小编正是这种问题)解决方案方案一方案二解决torch.cuda.is_available()返回False出现返回False的原因问题1:版本不匹配电脑
解决方案:炼丹师养成计划 Pytorch如何进行断点续训——DFGAN断点续训实操
在实际运行当中,我们经常需要每100轮epoch或者每50轮epoch要保存训练好的参数,以防不测,这样下次可以直接加载该轮epoch的参数接着训练,就不用重头开始。下面我们来介绍Pytorch断点续训原理以及DFGAN20版本和22版本断点续训实操**。
Pytorch+PyG实现GraphSAGE
本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现),理论与实践相结合,如GCN、GAT、GraphSAGE等经典图网络,每一个代码实例都附带有完整的代码。
清华源conda安装PyTorch的GPU版本总是下载CPU版本安装包怎么办
如下图,我用的python是3.8版本,想要下载pytorch的cuda=11.7版本的GPU环境,但是输入以下命令之后总是显示下载cpu版本的安装包。再输入torch.cuda.is_available()敲回车,若显示Ture,说明pytorch的GPU版本环境创建成功!然后把下载到本地的压缩包
对 ChatGLM-6B 做 LoRA Fine-tuning
ChatGLM-6B 是一个支持中英双语的对话语言模型,基于 GLM (General Language Model)。它只有 62 亿个参数,量化后最低 (INT4 量化) 只需要 6GB 的显存,完全可以部署到消费级显卡上。在实际使用这个模型一段时间以后,我们发现模型的对话表现能力确实非常不错。
PyTorch 深度学习实战 | 基于生成式对抗网络生成动漫人物
生成式对抗网络(Generative Adversarial Network, GAN)是近些年计算机视觉领域非常常见的一类方法,其强大的从已有数据集中生成新数据的能力令人惊叹,甚至连人眼都无法进行分辨。本文将会介绍基于最原始的DCGAN的动漫人物生成任务,通过定义生成器和判别器,并让这两个网络在参
Pytroch进行模型权重初始化
Pytroch常见的模型参数初始化方法有apply和model.modules()。Pytroch会自动给模型进行初始化,当需要自己定义模型初始化时才需要这两个方法。
Pytorch 深度学习注意力机制的解析与代码实现
深度学习Attention注意力机制的解析及其Pytorch代码实现
踩雷日记:Pytorch mmcv-full简易安装
因为mmcv-full版本与pytorch和cuda版本不匹配,导致mmcv-full安装失败。提示:安装mmcv-full前,先把mmcv卸掉例如:以上就是今天要讲的内容,本文简单介绍了mmcv-full的安装,希望对你有所帮助。
带你一文透彻学习【PyTorch深度学习实践】分篇——线性模型 & 梯度下降
鉴于PyTorch深度学习实践系列文章,篇幅较长,有粉丝朋友反馈说不便阅读。因此这里将会分篇发布,以便于大家阅读。本次发布的是 “基础 模型&算法 回顾”章节中的线性模型、Gradient Descent(梯度下降)。
PyTorch之F.pad的使用与报错记录
这一函数用于实现对高维tensor的形状补齐操作。模式中,padding的数量不得超出原始tensor对应维度的大小。常见的错误主要是因为padding的数量超过了对应模式的要求。模式中,padding的数量必须小于对应维度的大小。对于padding并没有限制。
TensorRT(C++)部署 Pytorch模型
众所周知,python训练pytorch模型得到.pt模型。但在实际项目应用中,特别是嵌入式端部署时,受限于语言、硬件算力等因素,往往需要优化部署,而tensorRT是最常用的一种方式。本文以yolov5的部署为例,说明模型部署在x86架构上的电脑端的流程。(部署在Arm架构的嵌入式端的流程类似)。
3d稀疏卷积——spconv源码剖析(一)
和对应上图的Hash_in,和Hash_out。对于是下标,key_ in表示value在中的位置。现在的input一共两个元素P1和P2,P1在的(2, 1)位置,P2在的(3,2)的位置,并且是YX顺序。这里只记录一下p1的位置 ,先不管p1代表的数字把这个命名为。input hash tabe
ChatGLM-6B 类似ChatGPT功能型对话大模型 部署实践
ChatGLM(alpha内测版:QAGLM)是一个初具问答和对话功能的中英双语模型,当前仅针对中文优化,多轮和逻辑能力相对有限,但其仍在持续迭代进化过程中,敬请期待模型涌现新能力。中英双语对话 GLM 模型:ChatGLM-6B,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量
全局平均池化/全局最大池化Pytorch实现:
全局池化与普通池化的区别在于“局部区域”和“全局”:普通池化根据滑动窗口以及步长以逐步计算局部区域的方式进行;而全局池化是分别对每个通道的所有元素进行计算,谓之全局池化。大大降低计算的参数量;没有需要学习的参数,可以更好的避免过拟合;更能体现输入的全局信息;拿一个简单的网络验证参数量下降(此处只计算
Jetson AGX Orin上部署YOLOv5_v5.0+TensorRT8
Jetson AGX Orin上部署YOLOv5_v5.0+TensorRT8
pytorch深度学习一机多显卡训练设置,流程
pytorch深度学习一机多显卡训练设置,流程



