
注意力机制
2023年,3月2号,新增SKNet代码 2023.3.10 新增 scSE代码 2023.3.11 新增 Non-Local Net 非局部神经网络 2023.3.13新增GCNet
1 SENet
SE注意力机制(Squeeze-and-Excitation Networks)
:是一种通道类型的注意力机制,就是在通道维度上增加注意力机制,主要内容是是squeeze和excitation.
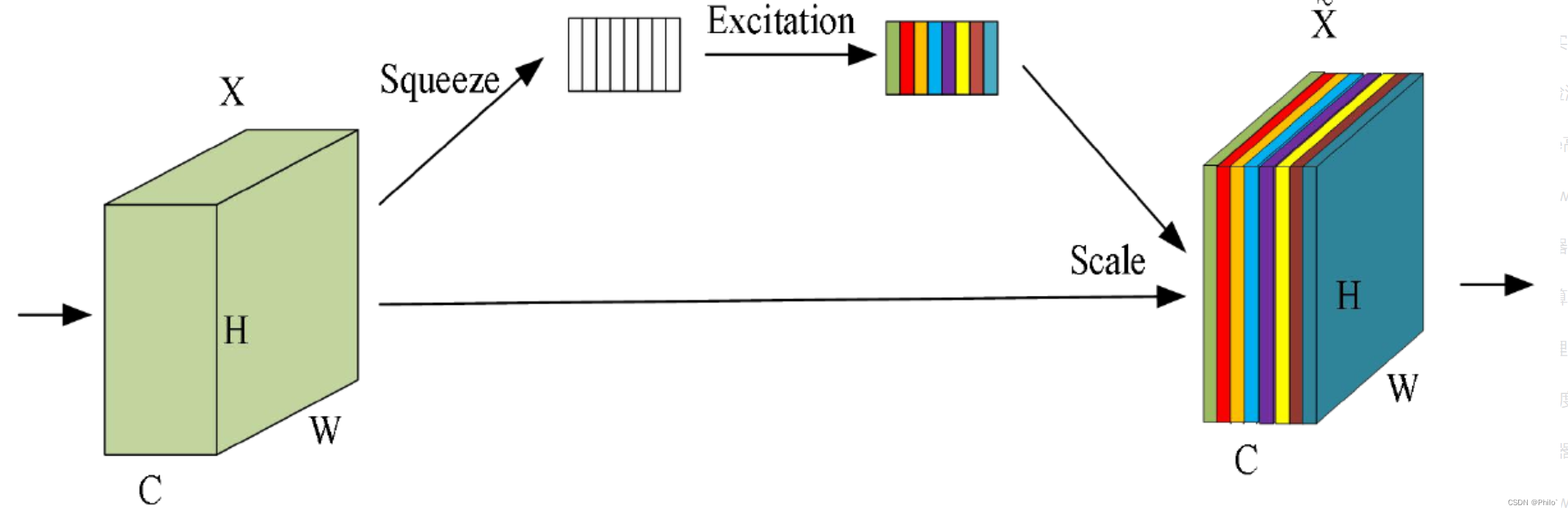
就是使用另外一个新的神经网络(两个Linear层),针对通道维度的数据进行学习,获取到特征图每个通道的重要程度,然后再和原始通道数据相乘即可。
具体参考Blog:
CNN中的注意力机制
小结:
- SENet的核心思想是通过全连接网络根据loss损失来自动学习特征权重,而不是直接根据特征通道的数值分配来判断,使有效的特征通道的权重大。
- 论文认为excitation操作中使用两个全连接层相比直接使用一个全连接层,它的好处在于,具有更多的非线性,可以更好地拟合通道间的复杂关联。
代码:
拆解步骤,forward代码写的比较细节
import torch
from torch import nn
from torchstat import stat # 查看网络参数# 定义SE注意力机制的类classse_block(nn.Module):# 初始化, in_channel代表输入特征图的通道数, ratio代表第一个全连接下降通道的倍数def__init__(self, in_channel, ratio=4):# 继承父类初始化方法super(se_block, self).__init__()# 属性分配# 全局平均池化,输出的特征图的宽高=1
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)# 第一个全连接层将特征图的通道数下降4倍
self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel//ratio, bias=False)# relu激活
self.relu = nn.ReLU()# 第二个全连接层恢复通道数
self.fc2 = nn.Linear(in_features=in_channel//ratio, out_features=in_channel, bias=False)# sigmoid激活函数,将权值归一化到0-1
self.sigmoid = nn.Sigmoid()# 前向传播defforward(self, inputs):# inputs 代表输入特征图# 获取输入特征图的shape
b, c, h, w = inputs.shape
# 全局平均池化 [b,c,h,w]==>[b,c,1,1]
x = self.avg_pool(inputs)# 维度调整 [b,c,1,1]==>[b,c]
x = x.view([b,c])# 第一个全连接下降通道 [b,c]==>[b,c//4] # 这里也是使用Linear层的原因,只是对Channel进行线性变换
x = self.fc1(x)
x = self.relu(x)# 第二个全连接上升通道 [b,c//4]==>[b,c] # 再通过Linear层恢复Channel数目
x = self.fc2(x)# 对通道权重归一化处理 # 将数值转化为(0,1)之间,体现不同通道之间重要程度
x = self.sigmoid(x)# 调整维度 [b,c]==>[b,c,1,1]
x = x.view([b,c,1,1])# 将输入特征图和通道权重相乘
outputs = x * inputs
return outputs
结果展示: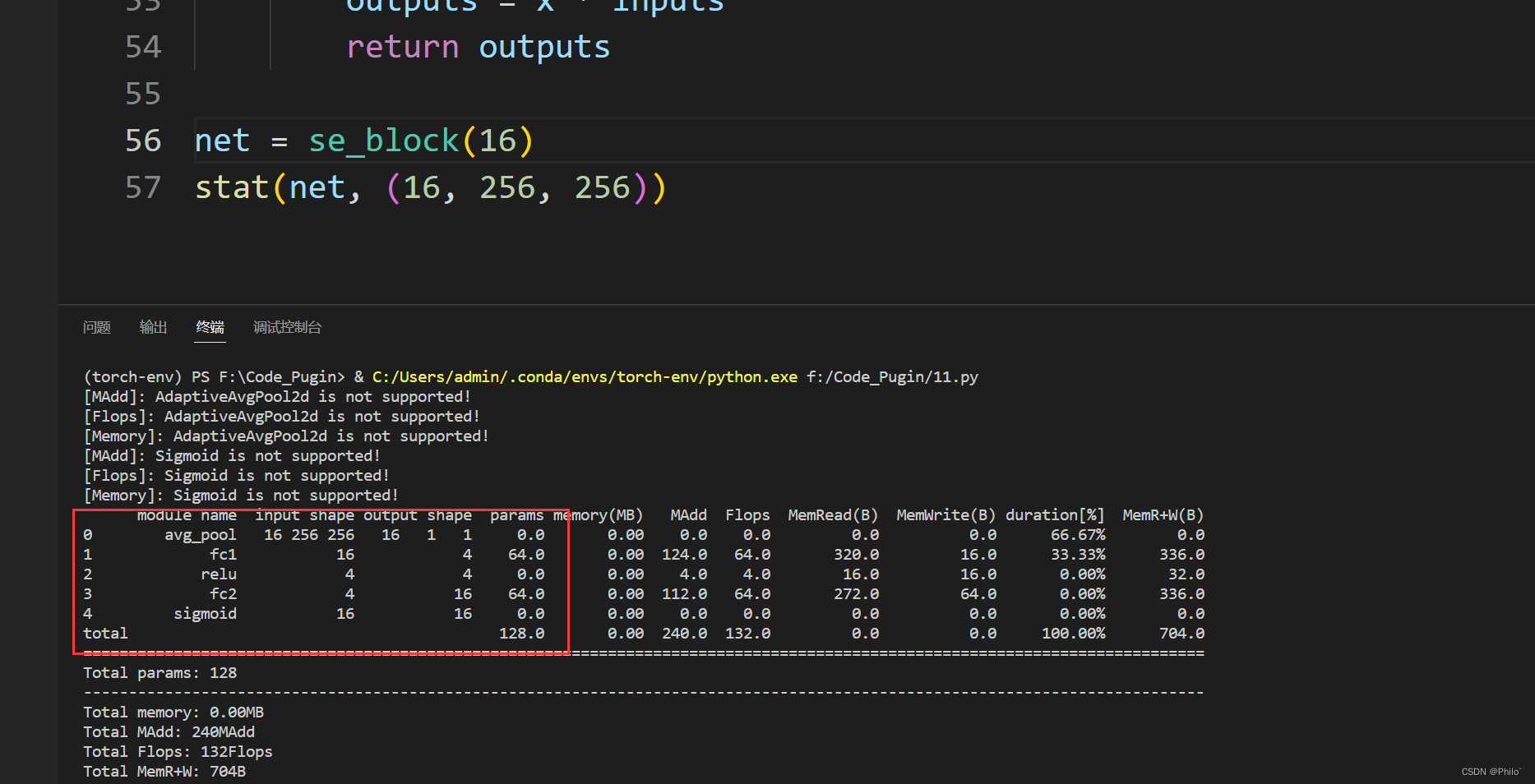
提示:
in_channel/ratio需要大于0,否则线性层输入是0维度,没有意义,可以根据自己需求调整ratio的大小。
2 ECANet
作者表明
SENet
中的降维会给通道注意力机制带来副作用,并且捕获所有通道之间的依存关系是效率不高的,而且是不必要的。
参考Blog:
CNN中的注意力机制
代码:
详细版本:在forward中,介绍了每一步的作用
import torch
from torch import nn
import math
from torchstat import stat # 查看网络参数# 定义ECANet的类classeca_block(nn.Module):# 初始化, in_channel代表特征图的输入通道数, b和gama代表公式中的两个系数def__init__(self, in_channel, b=1, gama=2):# 继承父类初始化super(eca_block, self).__init__()# 根据输入通道数自适应调整卷积核大小
kernel_size =int(abs((math.log(in_channel,2)+b)/gama))# 如果卷积核大小是奇数,就使用它if kernel_size %2:
kernel_size = kernel_size
# 如果卷积核大小是偶数,就把它变成奇数else:
kernel_size = kernel_size +1# 卷积时,为例保证卷积前后的size不变,需要0填充的数量
padding = kernel_size //2# 全局平均池化,输出的特征图的宽高=1
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)# 1D卷积,输入和输出通道数都=1,卷积核大小是自适应的# 这个1维卷积需要好好了解一下机制,这是改进SENet的重要不同点
self.conv = nn.Conv1d(in_channels=1, out_channels=1, kernel_size=kernel_size,
bias=False, padding=padding)# sigmoid激活函数,权值归一化
self.sigmoid = nn.Sigmoid()# 前向传播defforward(self, inputs):# 获得输入图像的shape
b, c, h, w = inputs.shape
# 全局平均池化 [b,c,h,w]==>[b,c,1,1]
x = self.avg_pool(inputs)# 维度调整,变成序列形式 [b,c,1,1]==>[b,1,c]
x = x.view([b,1,c])# 这是为了给一维卷积# 1D卷积 [b,1,c]==>[b,1,c]
x = self.conv(x)# 权值归一化
x = self.sigmoid(x)# 维度调整 [b,1,c]==>[b,c,1,1]
x = x.view([b,c,1,1])# 将输入特征图和通道权重相乘[b,c,h,w]*[b,c,1,1]==>[b,c,h,w]
outputs = x * inputs
return outputs
精简版:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchinfo import summary
import math
classEfficientChannelAttention(nn.Module):# Efficient Channel Attention moduledef__init__(self, c, b=1, gamma=2):super(EfficientChannelAttention, self).__init__()
t =int(abs((math.log(c,2)+ b)/ gamma))
k = t if t %2else t +1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1 = nn.Conv1d(1,1, kernel_size=k, padding=int(k/2), bias=False)
self.sigmoid = nn.Sigmoid()defforward(self, x):
x = self.avg_pool(x)# 这里可以对照上一版代码,理解每一个函数的作用
x = self.conv1(x.squeeze(-1).transpose(-1,-2)).transpose(-1,-2).unsqueeze(-1)
out = self.sigmoid(x)return out
效果展示: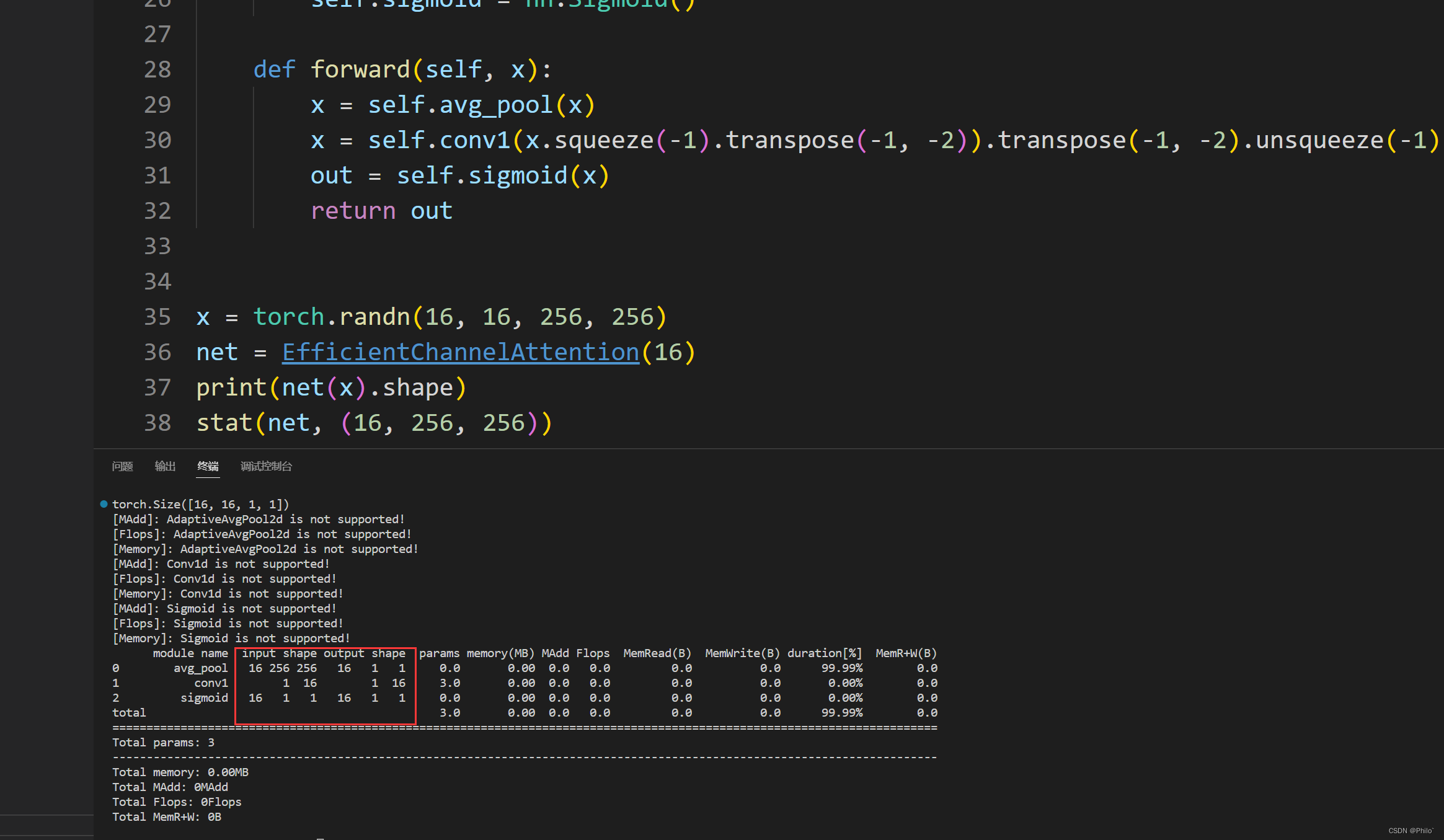
总结:
ECANet参数更少!
3 CBAM
CBAM注意力机制是由通道注意力机制(channel)和空间注意力机制(spatial)组成。
先通道注意力,后空间注意力的顺序注意力模块!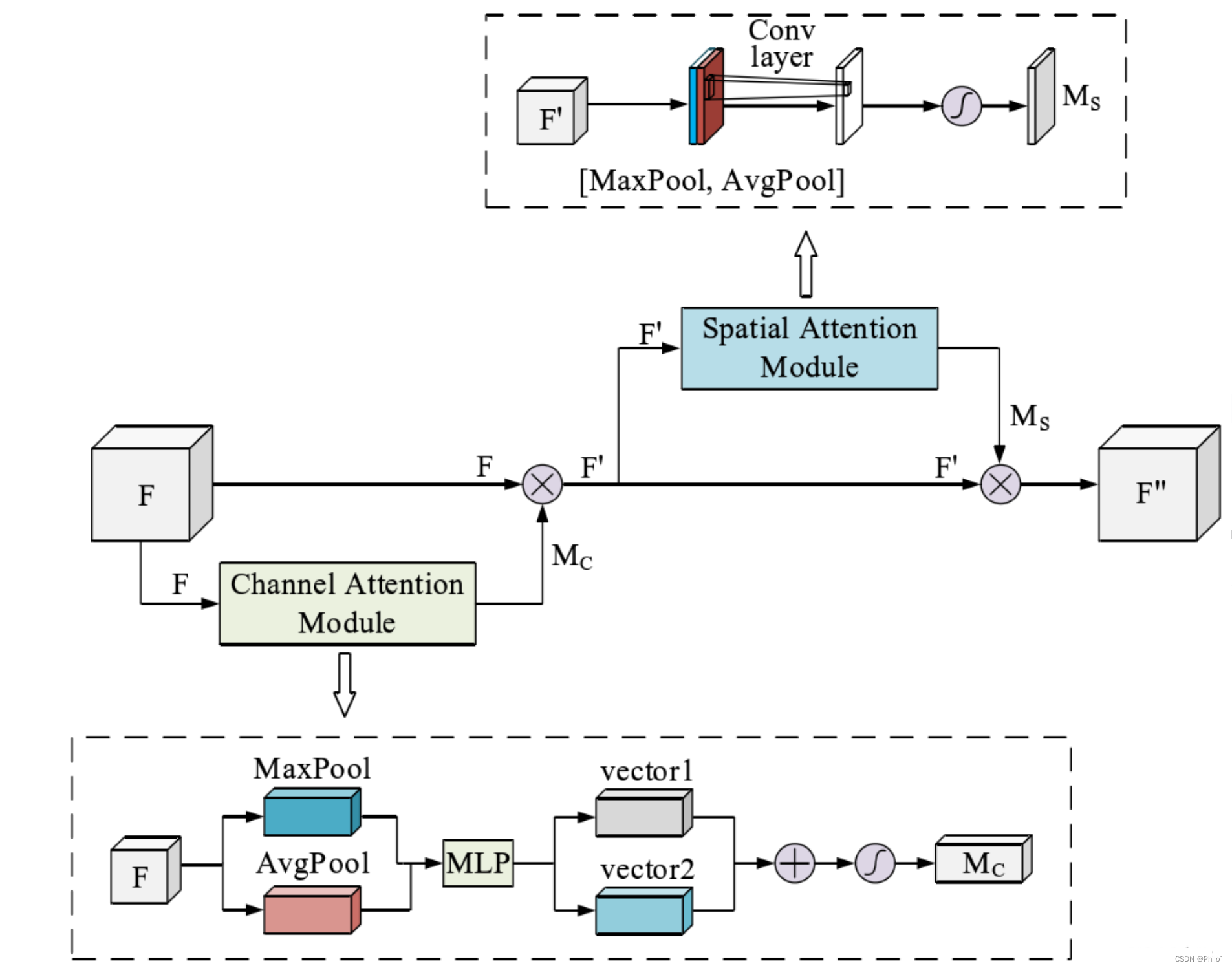
3.1 通道注意力
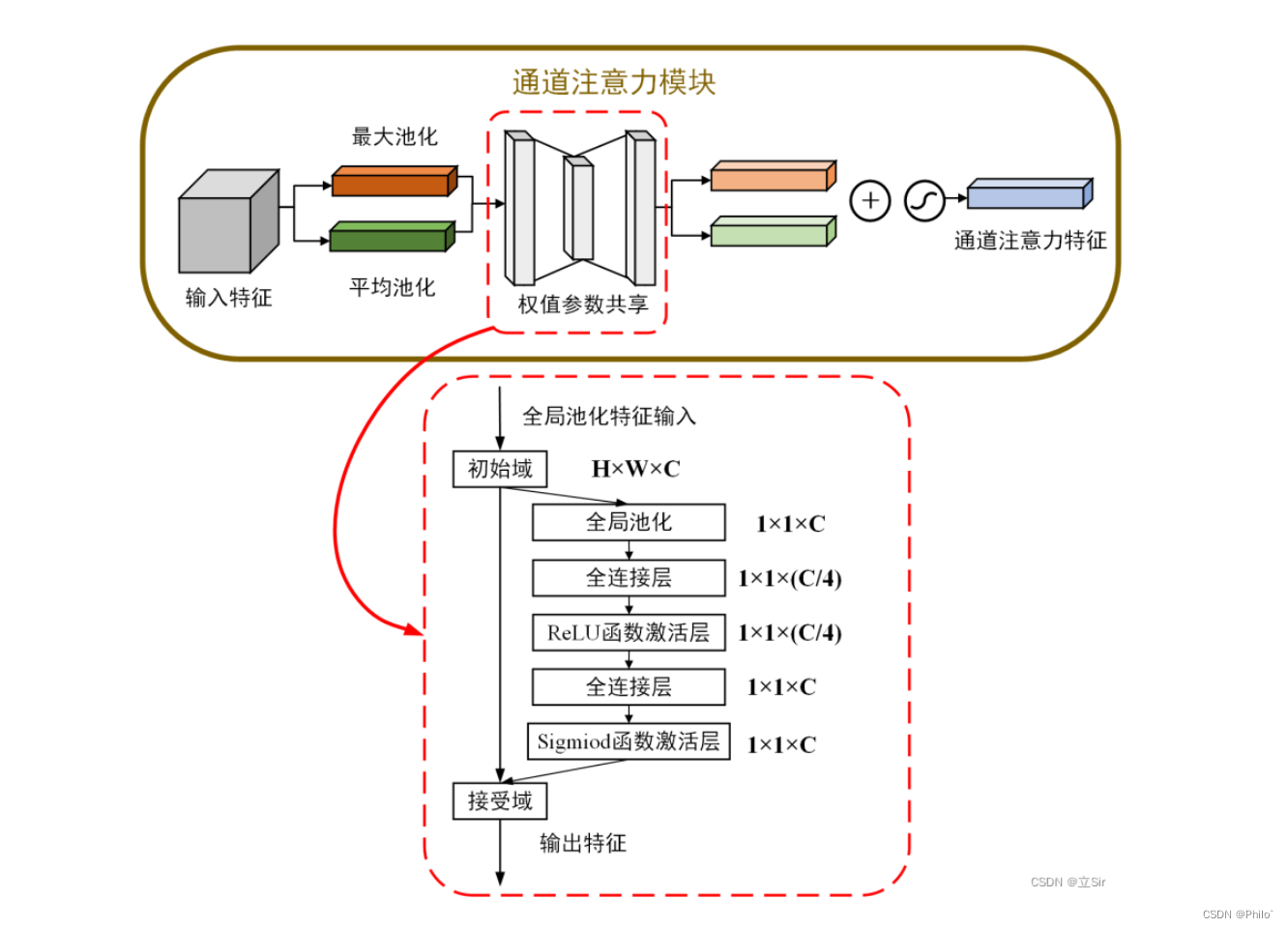
输入数据,对数据分别做最大池化操作和平均池化操作(输出都是batchchannel11),然后使用SENet的方法,针对channel进行先降维后升维操作,之后将输出的两个结果相加,再使用Sigmoid得到通道权重,再之后使用View函数恢复*(batchchannel1*1)**维度,和原始数据相乘得到通道注意力结果!
通道注意力代码:
#(1)通道注意力机制classchannel_attention(nn.Module):# 初始化, in_channel代表输入特征图的通道数, ratio代表第一个全连接的通道下降倍数def__init__(self, in_channel, ratio=4):# 继承父类初始化方法super(channel_attention, self).__init__()# 全局最大池化 [b,c,h,w]==>[b,c,1,1]
self.max_pool = nn.AdaptiveMaxPool2d(output_size=1)# 全局平均池化 [b,c,h,w]==>[b,c,1,1]
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)# 第一个全连接层, 通道数下降4倍
self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel//ratio, bias=False)# 第二个全连接层, 恢复通道数
self.fc2 = nn.Linear(in_features=in_channel//ratio, out_features=in_channel, bias=False)# relu激活函数
self.relu = nn.ReLU()# sigmoid激活函数
self.sigmoid = nn.Sigmoid()# 前向传播defforward(self, inputs):# 获取输入特征图的shape
b, c, h, w = inputs.shape
# 输入图像做全局最大池化 [b,c,h,w]==>[b,c,1,1]
max_pool = self.max_pool(inputs)# 输入图像的全局平均池化 [b,c,h,w]==>[b,c,1,1]
avg_pool = self.avg_pool(inputs)# 调整池化结果的维度 [b,c,1,1]==>[b,c]
max_pool = max_pool.view([b,c])
avg_pool = avg_pool.view([b,c])# 第一个全连接层下降通道数 [b,c]==>[b,c//4]
x_maxpool = self.fc1(max_pool)
x_avgpool = self.fc1(avg_pool)# 激活函数
x_maxpool = self.relu(x_maxpool)
x_avgpool = self.relu(x_avgpool)# 第二个全连接层恢复通道数 [b,c//4]==>[b,c]
x_maxpool = self.fc2(x_maxpool)
x_avgpool = self.fc2(x_avgpool)# 将这两种池化结果相加 [b,c]==>[b,c]
x = x_maxpool + x_avgpool
# sigmoid函数权值归一化
x = self.sigmoid(x)# 调整维度 [b,c]==>[b,c,1,1]
x = x.view([b,c,1,1])# 输入特征图和通道权重相乘 [b,c,h,w]
outputs = inputs * x
return outputs
3.2 空间注意力
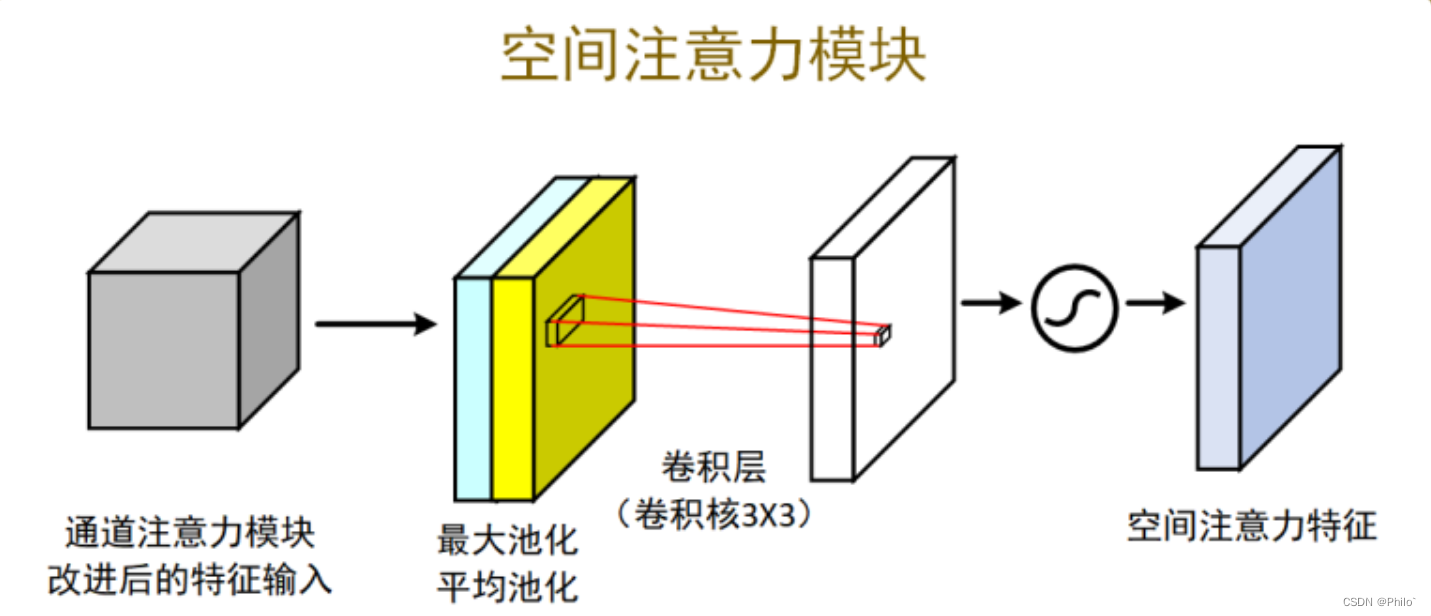
针对输入数据,分别选取数据中最大值所在的维度(batch1h*w),和按照维度进行数据平均操作(batch1hw),然后将两个数据做*通道连接(batch2h*w),使用卷积操作,将channel维度降为1,之后对结果取sigmoid,得到空间注意力权重,和原始数据相乘得到空间注意力结果。
代码:
#(2)空间注意力机制classspatial_attention(nn.Module):# 初始化,卷积核大小为7*7def__init__(self, kernel_size=7):# 继承父类初始化方法super(spatial_attention, self).__init__()# 为了保持卷积前后的特征图shape相同,卷积时需要padding
padding = kernel_size //2# 7*7卷积融合通道信息 [b,2,h,w]==>[b,1,h,w]
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=kernel_size,
padding=padding, bias=False)# sigmoid函数
self.sigmoid = nn.Sigmoid()# 前向传播defforward(self, inputs):# 在通道维度上最大池化 [b,1,h,w] keepdim保留原有深度# 返回值是在某维度的最大值和对应的索引
x_maxpool, _ = torch.max(inputs, dim=1, keepdim=True)# 在通道维度上平均池化 [b,1,h,w]
x_avgpool = torch.mean(inputs, dim=1, keepdim=True)# 池化后的结果在通道维度上堆叠 [b,2,h,w]
x = torch.cat([x_maxpool, x_avgpool], dim=1)# 卷积融合通道信息 [b,2,h,w]==>[b,1,h,w]
x = self.conv(x)# 空间权重归一化
x = self.sigmoid(x)# 输入特征图和空间权重相乘
outputs = inputs * x
return outputs
3.3 CBAM
将通道注意力模块和空间注意力模块顺序串联得到CBAM模块!
代码:
classcbam(nn.Module):# 初始化,in_channel和ratio=4代表通道注意力机制的输入通道数和第一个全连接下降的通道数# kernel_size代表空间注意力机制的卷积核大小def__init__(self, in_channel, ratio=4, kernel_size=7):# 继承父类初始化方法super(cbam, self).__init__()# 实例化通道注意力机制
self.channel_attention = channel_attention(in_channel=in_channel, ratio=ratio)# 实例化空间注意力机制
self.spatial_attention = spatial_attention(kernel_size=kernel_size)# 前向传播defforward(self, inputs):# 先将输入图像经过通道注意力机制
x = self.channel_attention(inputs)# 然后经过空间注意力机制
x = self.spatial_attention(x)return x
结果: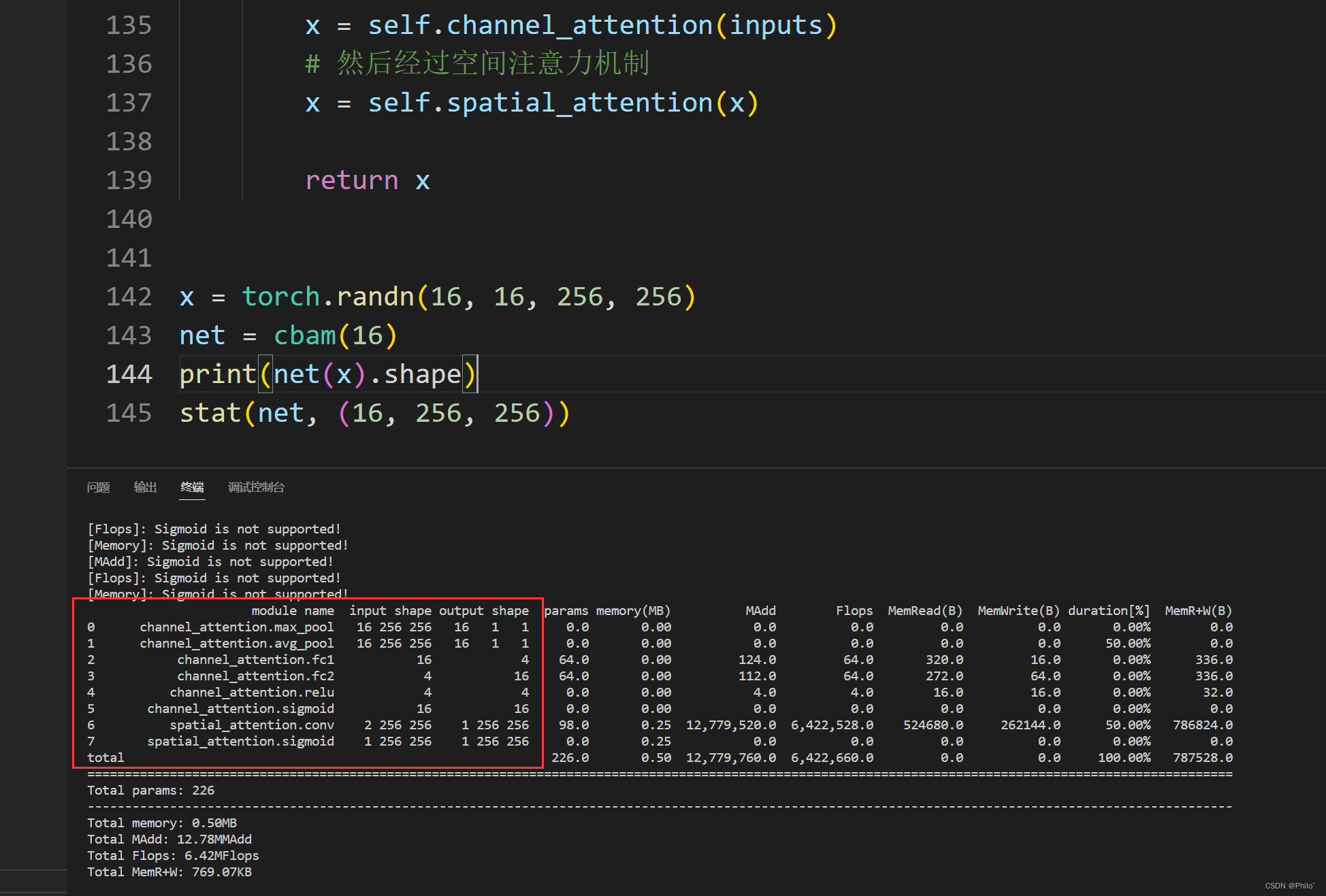
4 展示网络层具体信息
安装包
pip install torchstat
使用
from torchstat import stat
net = cbam(16)
stat(net,(16,256,256))# 不需要Batch维度
5 SKNet
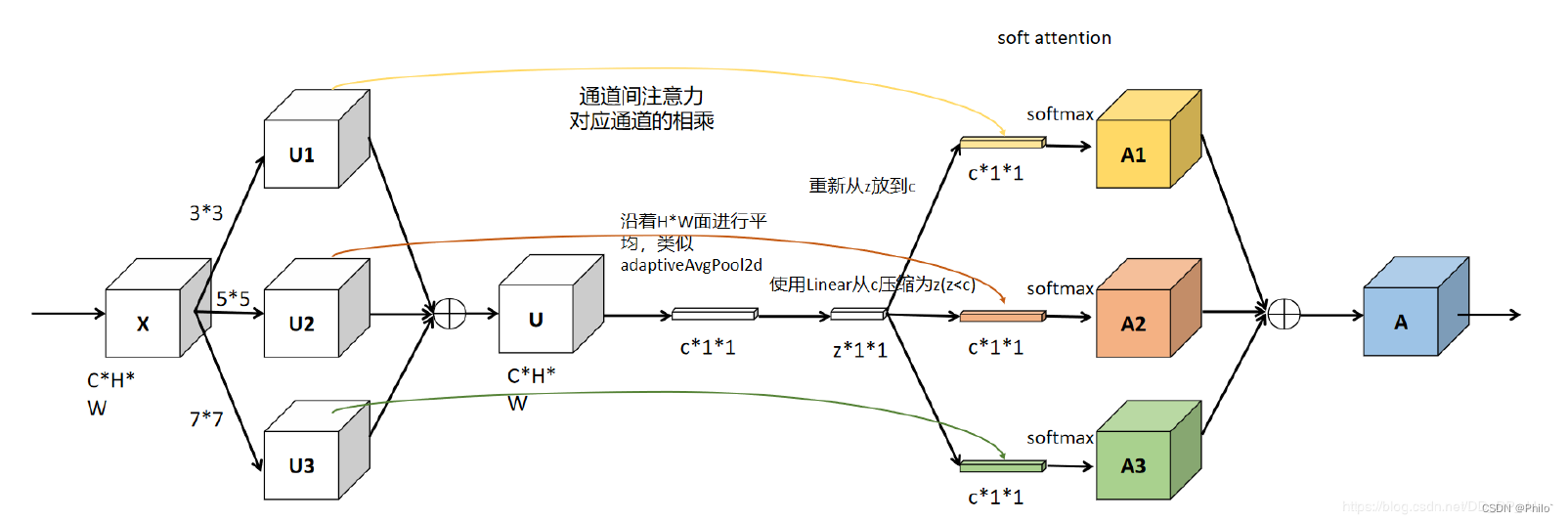
这是SENet的改进版,增加了多个分支,每个分支的感受野不同。
论文:https://arxiv.org/pdf/1903.06586
代码:
'''
Descripttion:
Result:
Author: Philo
Date: 2023-03-02 14:55:44
LastEditors: Philo
LastEditTime: 2023-03-02 16:01:03
'''import torch.nn as nn
import torch
classSKConv(nn.Module):def__init__(self, in_ch, M=3, G=1, r=4, stride=1, L=32)->None:super().__init__()""" Constructor
Args:
in_ch: input channel dimensionality.
M: the number of branchs.
G: num of convolution groups.
r: the radio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
d =max(int(in_ch/r), L)# 用来进行线性层的输出通道,当输入数据In_ch很大时,用L就有点丢失数据了。
self.M = M
self.in_ch = in_ch
self.convs = nn.ModuleList([])for i inrange(M):
self.convs.append(
nn.Sequential(
nn.Conv2d(in_ch, in_ch, kernel_size=3+i*2, stride=stride, padding =1+i, groups=G),
nn.BatchNorm2d(in_ch),
nn.ReLU(inplace=True)))# print("D:", d)
self.fc = nn.Linear(in_ch, d)
self.fcs = nn.ModuleList([])for i inrange(M):
self.fcs.append(nn.Linear(d, in_ch))
self.softmax = nn.Softmax(dim=1)defforward(self, x):for i, conv inenumerate(self.convs):# 第一部分,每个分支的数据进行相加,虽然这里使用的是torch.cat,但是后面又用了unsqueeze和sum进行升维和降维
fea = conv(x).clone().unsqueeze_(dim=1).clone()# 这里在1这个地方新增了一个维度 16*1*64*256*256if i ==0:
feas = fea
else:
feas = torch.cat([feas.clone(), fea], dim=1)# feas.shape batch*M*in_ch*W*H
fea_U = torch.sum(feas.clone(), dim=1)# batch*in_ch*H*W
fea_s = fea_U.clone().mean(-1).mean(-1)# Batch*in_ch
fea_z = self.fc(fea_s)# batch*in_ch-> batch*dfor i, fc inenumerate(self.fcs):# print(i, fea_z.shape)
vector = fc(fea_z).clone().unsqueeze_(dim=1)# batch*d->batch*in_ch->batch*1*in_ch# print(i, vector.shape)if i ==0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors.clone(), vector], dim=1)# 同样的相加操作 # batch*M*in_ch
attention_vectors = self.softmax(attention_vectors.clone())# 对每个分支的数据进行softmax操作
attention_vectors = attention_vectors.clone().unsqueeze(-1).unsqueeze(-1)# ->batch*M*in_ch*1*1
fea_v =(feas * attention_vectors).clone().sum(dim=1)# ->batch*in_ch*W*Hreturn fea_v
if __name__ =="__main__":
x = torch.randn(16,64,256,256)
sk = SKConv(in_ch=64, M=3, G=1, r=2)
out = sk(x)print(out.shape)# in_ch 数据输入维度,M为分指数,G为Conv2d层的组数,基本设置为1,r用来进行求线性层输出通道的。
结果: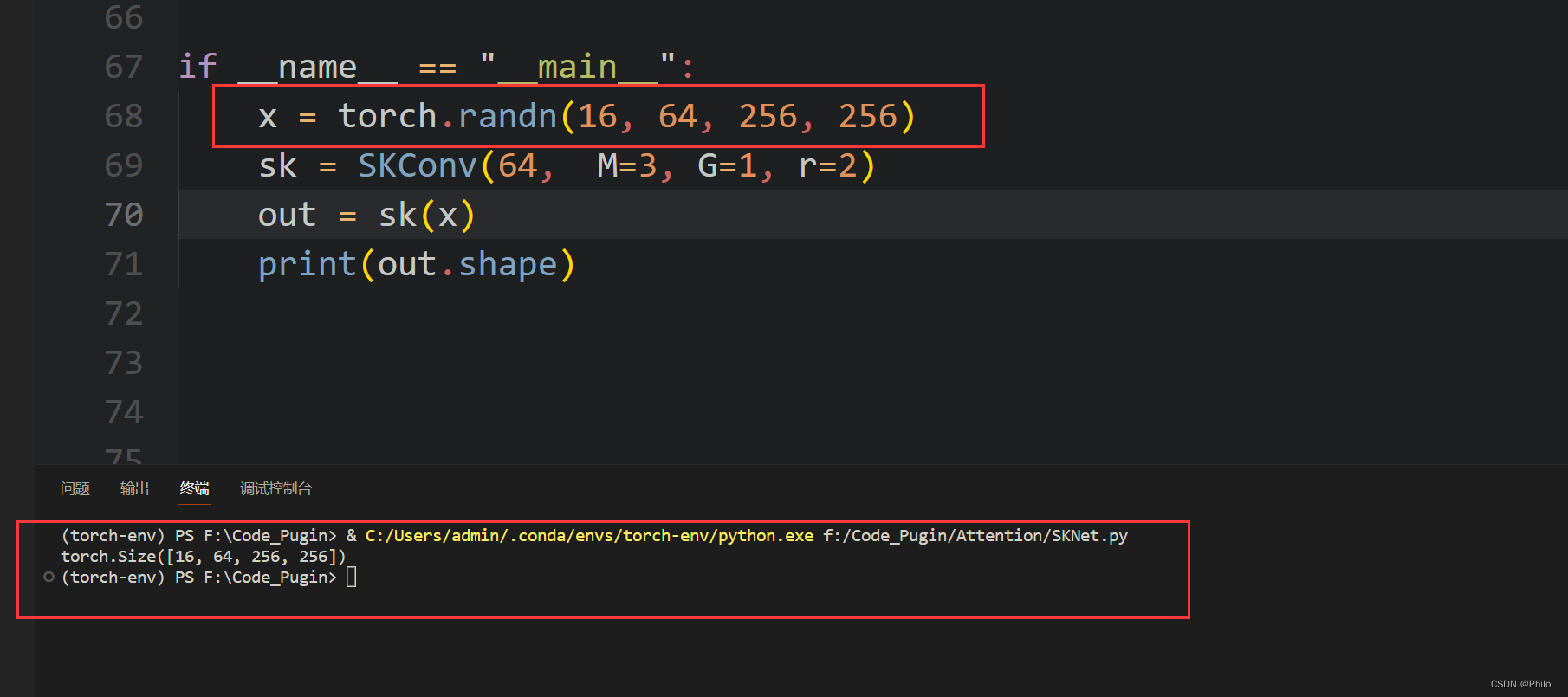
该注意力模块不改变输入数据的大小和维度!详细内容都已经在备注里啦,大家可以自己写一遍,走一遍代码!
6 scSE
网络结构图: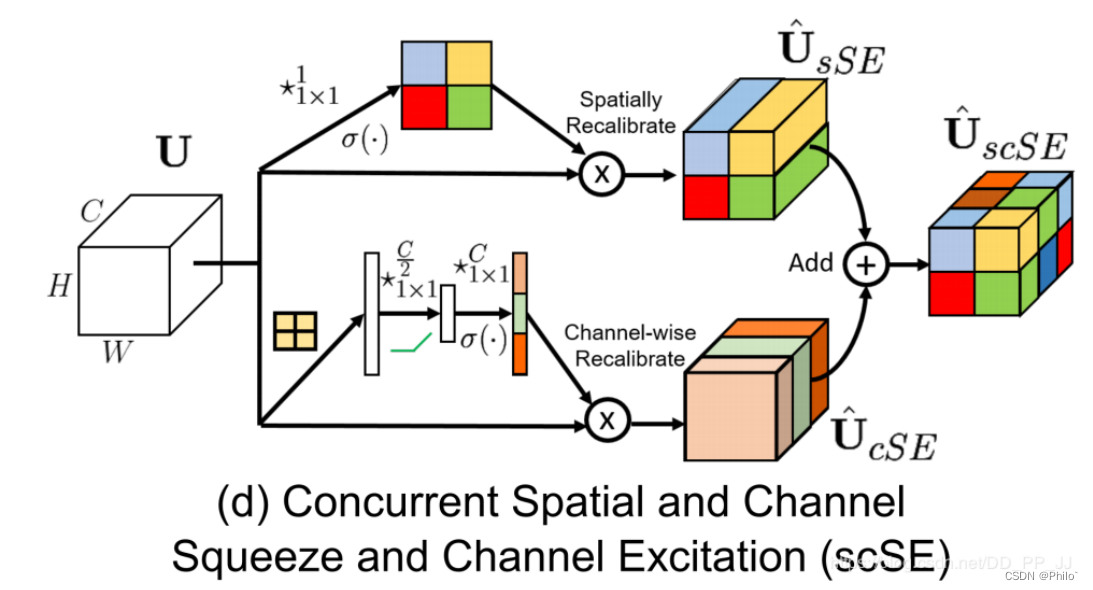
论文地址:http://arxiv.org/pdf/1803.02579v2
重点:
文章是2018年发出的,将两种注意力机制后的数据进行相加,在空间注意力中(Space Attention): 直接就是通过Conv2d(in_ch, 1,kernel_size=1, bias=False)得到一个b * 1 * h * w的数据,然后经过sigmoid进行数据处理,放大重点,缩小非重点,然后将数据与原始数据相乘就得到空间注意力的结果。
在通道注意力中: 需要得到b * ch * 1 * 1 的数据,先是使用一个自适应池化层得到b * ch * 1 * 1 的数据,然后对通道维度先降维在升维,之后使用sigmoid得到权重,和原始数据相乘,得到通道注意力结果。
代码:
'''
Descripttion:
Result:
Author: Philo
Date: 2023-03-07 19:16:52
LastEditors: Philo
LastEditTime: 2023-03-10 16:05:02
'''import torch
import torch.nn as nn
classsSE(nn.Module):# 空间(Space)注意力def__init__(self, in_ch)->None:super().__init__()
self.conv = nn.Conv2d(in_ch,1, kernel_size=1, bias=False)
self.norm = nn.Sigmoid()defforward(self, x):
q = self.conv(x)# b c h w -> b 1 h w
q = self.norm(q)# b 1 h wreturn x*q # 广播机制 classcSE(nn.Module):# 通道(channel)注意力def__init__(self, in_ch)->None:super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)# b c 1 1
self.Conv_Squeeze = nn.Conv2d(in_ch, in_ch//2, kernel_size=1, bias=False)
self.Conv_Excitation = nn.Conv2d(in_ch//2, in_ch, kernel_size=1, bias=False)
self.norm = nn.Sigmoid()defforward(self, x):
z = self.avgpool(x)# b c 1 1
z = self.Conv_Squeeze(z)# b c//2 1 1
z = self.Conv_Excitation(z)# b c 1 1
z = self.norm(z)# b c 1 1return x*z.expand_as(x)# 扩展classscSE(nn.Module):def__init__(self, in_ch)->None:super().__init__()
self.cSE = cSE(in_ch)
self.sSE = sSE(in_ch)defforward(self, x):
c_out = self.cSE(x)
s_out = self.sSE(x)return c_out + s_out
x = torch.randn(4,16,4,4)
net = scSE(16)print(net(x).shape)
结果: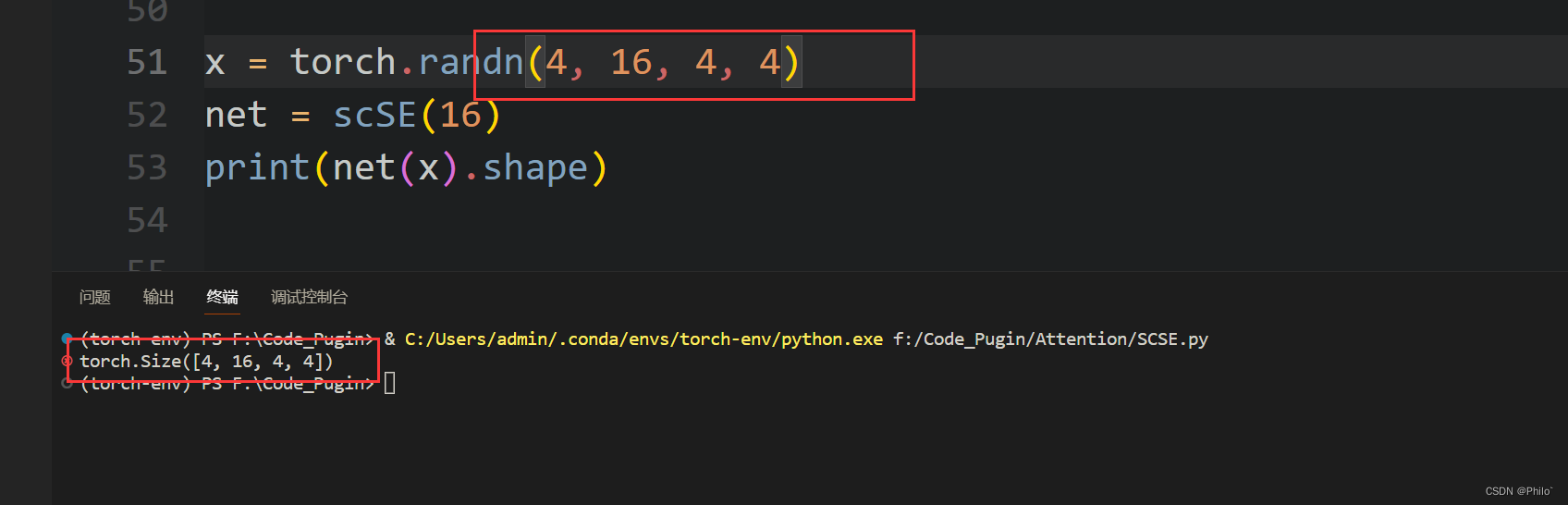
该注意力模块不改变输入数据的大小和维度!代码实现也较为简单,大家可以自己走一遍!
7 Non-Local Net
结构图: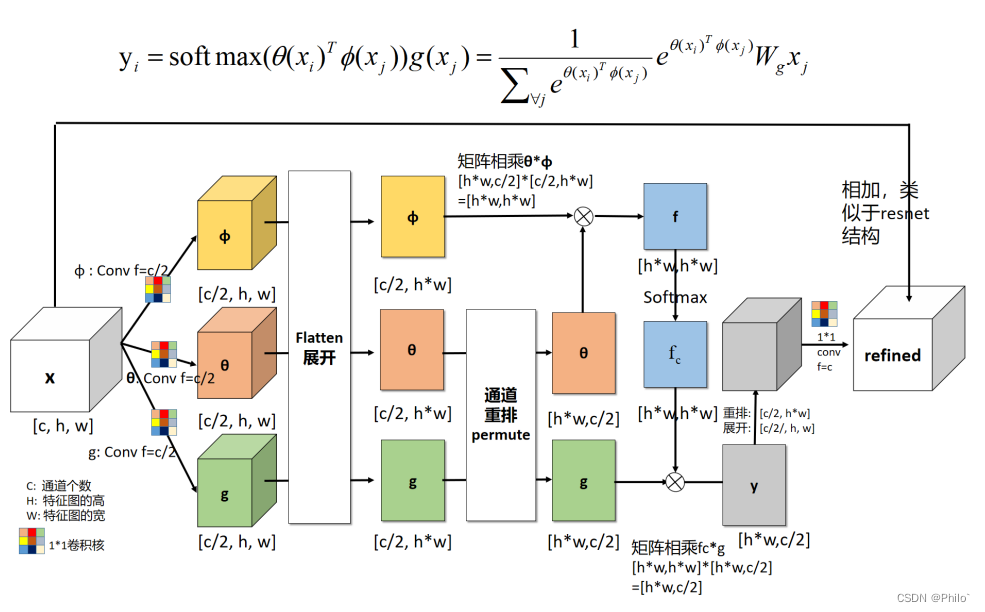
论文地址:https://arxiv.org/pdf/1711.07971
讲解:
整体流程就是公式上写的那样,对一个数据进行三个不同的变化,首先使用一个1*1的卷积层和维度变换得到
θ
\theta
θ, 使用一个1*1的卷积层通过x得到
φ
\varphi
φ ,将这两个数据进行举证乘法,得到f,然后对f进行softmax得到数据权重,将数据和g相乘,得到最后的结果,不过数据维度和通道数不一样,因此使用一个1*1的卷积层和view函数进行数据恢复,最后将得到数据和原始的x进行相加(类似于残差连接的一样),就得到最后的结果了。
代码:
'''
Descripttion:
Result:
Author: Philo
Date: 2023-03-10 16:50:42
LastEditors: Philo
LastEditTime: 2023-03-11 16:41:50
'''import torch
from torch import nn
from torch.nn import functional as F
classNonLocalBlockND(nn.Module):def__init__(self, in_channels, inter_channels=None, dimension=2, sub_sample=True, bn_layer=True)->None:super().__init__()"""
in_channels: 输入通道
inter_channels: 中间数据通道
dimension: 输入数据的维度
sub_sample: 是否进行最大池化 一般是True
bn_layer: 一般是True
"""assert dimension in[1,2,3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels isNone:
self.inter_channels = self.in_channels //2if self.inter_channels ==0:
self.inter_channels =1if dimension ==3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1,2,2))
bn = nn.BatchNorm3d
elif dimension ==2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2,2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1)if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels, kernel_size=1),bn(self.in_channels))
nn.init.constant_(self.W[1].weight,0)# 使用 0 对 参数进行赋初值
nn.init.constant_(self.W[1].bias,0)# 使用 0 对参数进行赋初值else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels, kernel_size=1)
nn.init.constant_(self.W.weight,0)
nn.init.constant_(self.W.bias,0)
self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1)
self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1)if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)defforward(self, x):
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels,-1)# b c w*h 这里还经过了maxpool的操作,maxpool:w_out = (w-k_size+2*pad)/k_size + 1print(g_x.shape,"self.g后的数据")
g_x = g_x.permute(0,2,1)#维度变化 b wh c
theta_x = self.theta(x).view(batch_size, self.inter_channels,-1)# b c w*h 这里没有经过maxpool操作print(theta_x.shape,"self.theta后的数据")
theta_x = theta_x.permute(0,2,1)# b wh c
phi_x = self.phi(x).view(batch_size, self.inter_channels,-1)# b c w*h 这里经过了maxpoolprint(phi_x.shape,"self.phi_x后的数据")
f = torch.matmul(theta_x, phi_x)# 1024*8 矩阵乘 8*256 = 1024*256 print(f.shape)
f_div_C = F.softmax(f, dim=-1)# 对 最后一维做softmax
y = torch.matmul(f_div_C, g_x)# 1024*256 * 256*8 = 1024*8print(y.shape,"g_x和y矩阵乘后的结果")
y = y.permute(0,2,1).contiguous()# 这里的contiguous类似与clone 否则后期对y修改数据,也会对原始数据进行修改 # 得到 batch_size*8*1024
y = y.view(batch_size, self.inter_channels,*x.size()[2:])# *x.size()[2:] 这个花里胡哨的,就是获取x的h 和 w; 再将数据恢复到原始格式
W_y = self.W(y)# 这里将b inter_ch w h -> b in_ch w h
z = W_y + x # 进行残差连接return z
x = torch.randn(16,16,32,32)
net = NonLocalBlockND(in_channels=16)print(net(x).shape)
结果: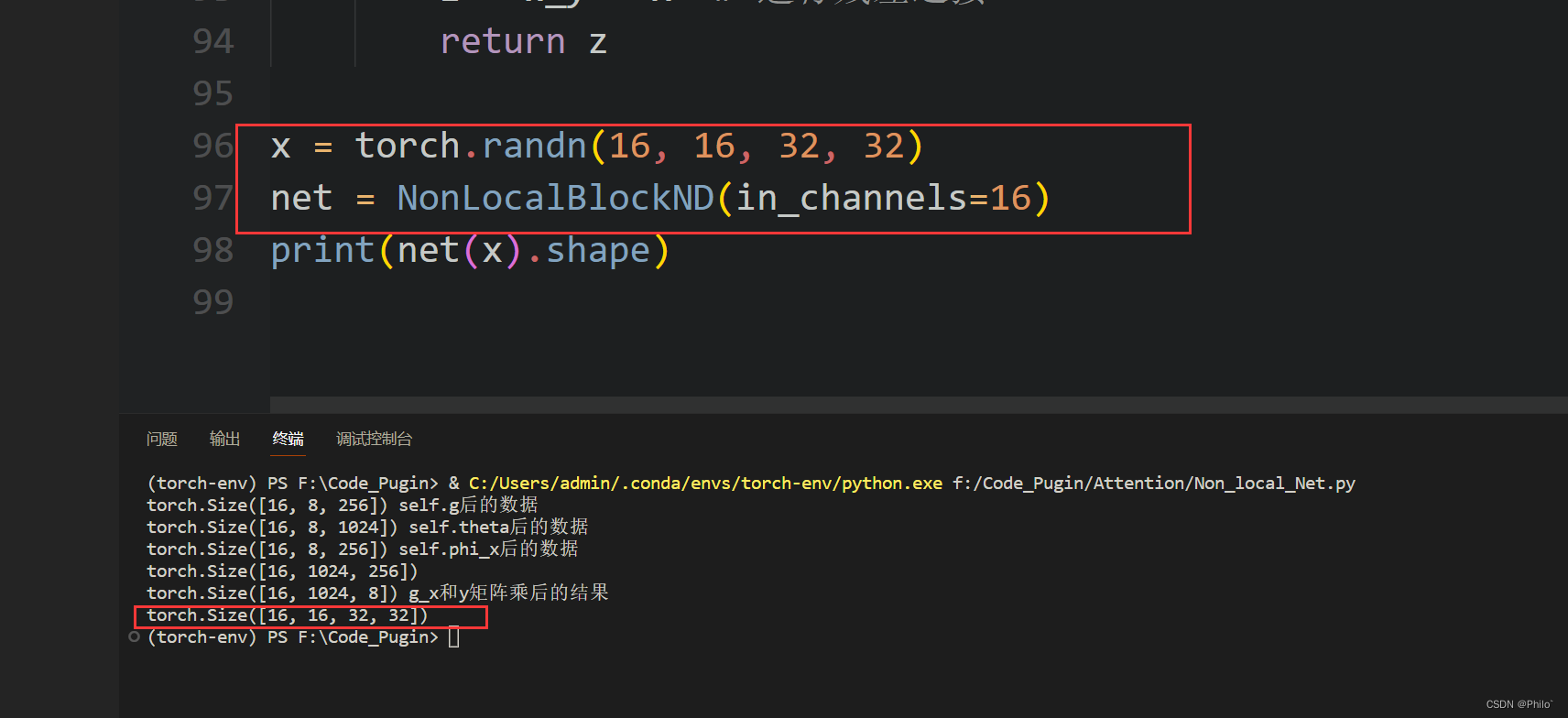
数据的中间输出也打印出来了,建议大家跟着写一遍 加深理解!
8 GCNet
结构: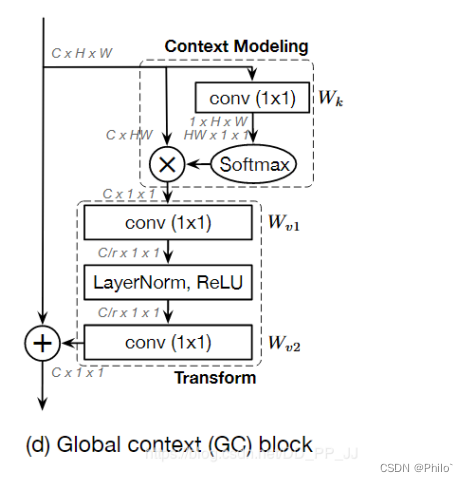
论文地址:https://arxiv.org/abs/1904.11492
重点:
该模型是环节Non-Loca Net计算量过大的情况,代码实现的时候,有不同的组合,一种是支路与主路的Multial操作,一种是如图所示的Add操作,具体选择可以参考代码
代码:
'''
Descripttion:
Result:
Author: Philo
Date: 2023-03-11 17:55:19
LastEditors: Philo
LastEditTime: 2023-03-13 20:25:19
'''import torch
import torch.nn as nn
classGlobalContextBlock(nn.Module):def__init__(self, inplanes, ratio, pooling_type="att", fusion_types=('channel_mul'))->None:super().__init__()
valid_fusion_types =['channel_add','channel_mul']assert pooling_type in['avg','att']# assert all([f in valid_fusion_types for f in fusion_types])assertlen(fusion_types)>0,'at least one fusion should be used'
self.inplanes = inplanes
self.ratio = ratio
self.planes =int(inplanes*ratio)
self.pooling_type = pooling_type
self.fusion_type = fusion_types
if pooling_type =='att':
self.conv_mask = nn.Conv2d(inplanes,1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)if'channel_add'in fusion_types:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes,1,1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:
self.channel_add_conv =Noneif'channel_mul'in fusion_types:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes,1,1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:
self.channel_mul_conv =Nonedefspatial_pool(self, x):
batch, channel, height, width = x.size()if self.pooling_type =='att':# 这里其实就是空间注意力 最后得到一个b c 1 1的权重
input_x = x
input_x = input_x.view(batch, channel, height*width)# -> b c h*w
input_x = input_x.unsqueeze(1)# -> b 1 c hw
context_mask = self.conv_mask(x)# b 1 h w
context_mask = context_mask.view(batch,1, height*width)# b 1 hw
context_mask = self.softmax(context_mask)# b 1 hw
context_mask = context_mask.unsqueeze(-1)# b 1 hw 1
context = torch.matmul(input_x, context_mask)# b(1 c hw * 1 hw 1) -> b 1 c 1
context = context.view(batch, channel,1,1)# b c 1 1else:
context = self.avg_pool(x)# b c 1 1return context
defforward(self, x):
context = self.spatial_pool(x)
out = x
if self.channel_mul_conv isnotNone:
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))# 将权重进行放大缩小
out = out * channel_mul_term # 与x进行相乘if self.channel_add_conv isnotNone:
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out
if __name__ =="__main__":input= torch.randn(16,64,32,32)
net = GlobalContextBlock(64, ratio=1/16)
out = net(input)print(out.shape)
结果: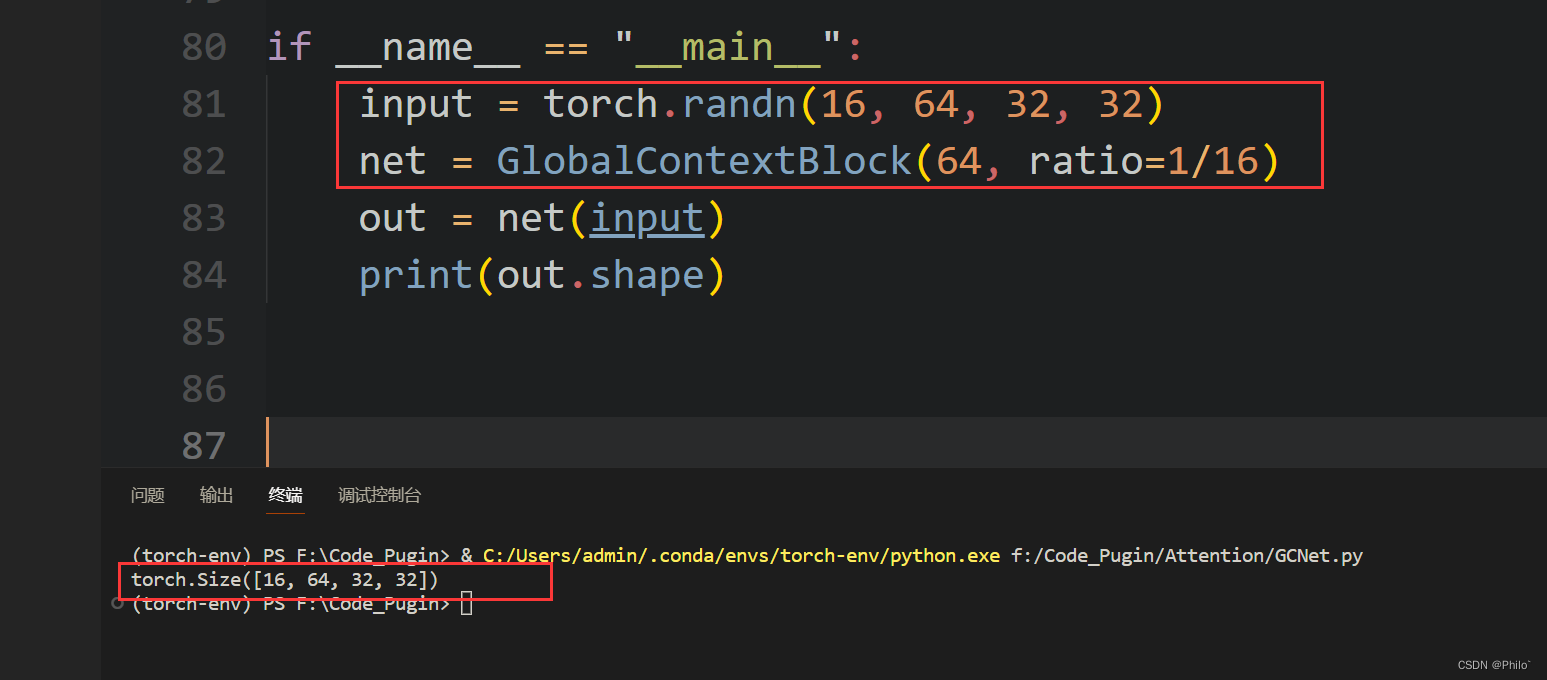
建议自己在纸上或者是打断点走一遍代码!
9 注意力机制后期学习到再持续更新!!
参考博客:
CNN注意力机制
ECANet
版权归原作者 Philo` 所有, 如有侵权,请联系我们删除。