
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
神经网络训练超参数调整不仅需要大量的训练时间,还需要很大的人力成本。Population Based Training(PBT)是一个很好的自动化调整的方法,但是他的最大问题是决策机制关注短期的性能改进,在大轮次训练时效果不好。
为了解决这个问题,DeepMind的一个研究团队提出了Faster Improvement Rate PBT (FIRE PBT),这是一种新的性能优于PBT方法,并与ImageNet基准上通过传统手工超参数调优训练的网络的性能相匹配。

在 PBT 中,一群worker同时用他们自己的超参数训练他们各自的神经网络。在此过程中,每个worker都会定期将其评估(“适应度”)与其他人进行比较。如果一个worker的适应度低于它的worker,它将经历一个exploit-and-explore过程——在exploit步骤中丢弃自己的状态并复制表现更好的worker的神经网络权重和超参数,并对复制的超参数进行变异然后继续训练。
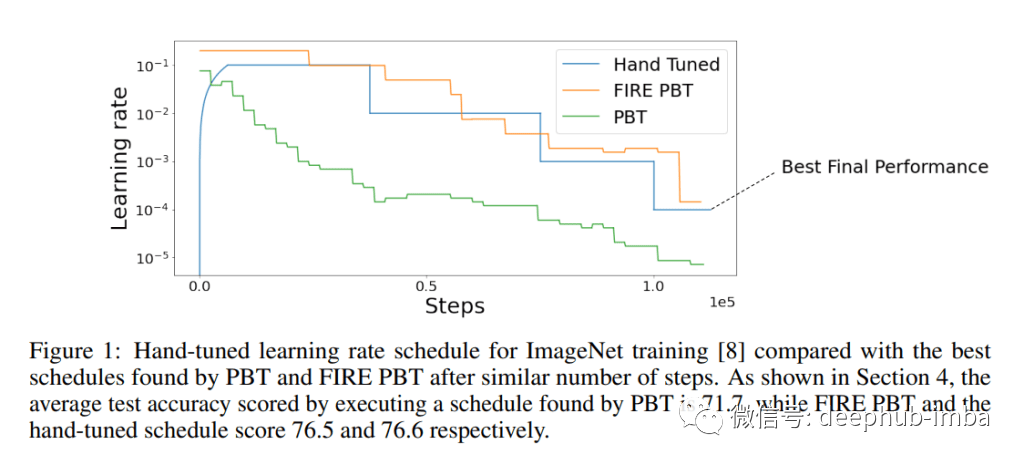
与以往的顺序超参数优化方法不同,PBT利用并行训练来加快训练过程。在神经网络训练的同时,对超参数进行了优化,从而获得了更好的性能。
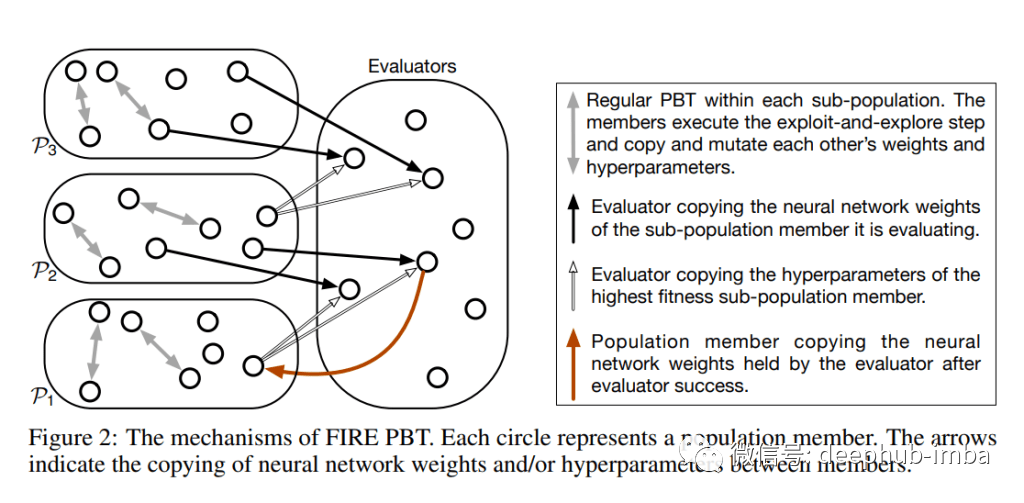
上面提到PBT的一个缺点是:它是一个贪婪的过程倾向短期的奖励,这可能会导致后来的训练表现下降。为了解决这个问题,FIRE PBT将worker分为两个主要群体:population members 和 evaluators.。群成员被进一步划分为多个不相交的子群(p1,p2,…pn)。群成员内部运行常规的PBT所以子群p1是贪婪的,而所有其他子群都是与之平等并设置了不同的行为。当worker群体进行超参数训练时鼓励他们产生具有高适应度值的神经网络权值。
在评估中,该团队将FIRE PBT与PBT和随机超参数搜索(RS)在图像分类任务和强化学习(RL)任务上进行了比较。
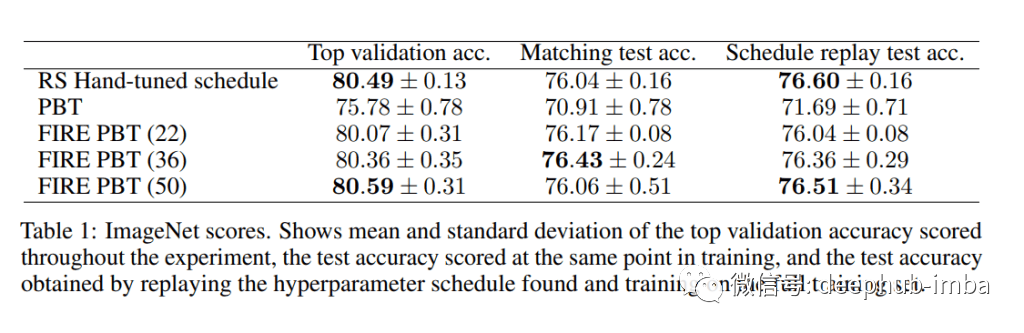
在图像分类任务中,FIRE PBT显著优于PBT,取得了与手动调整相当的结果。研究人员还观察到,FIRE PBT在不影响长期性能的情况下迅速达到了高精确度。
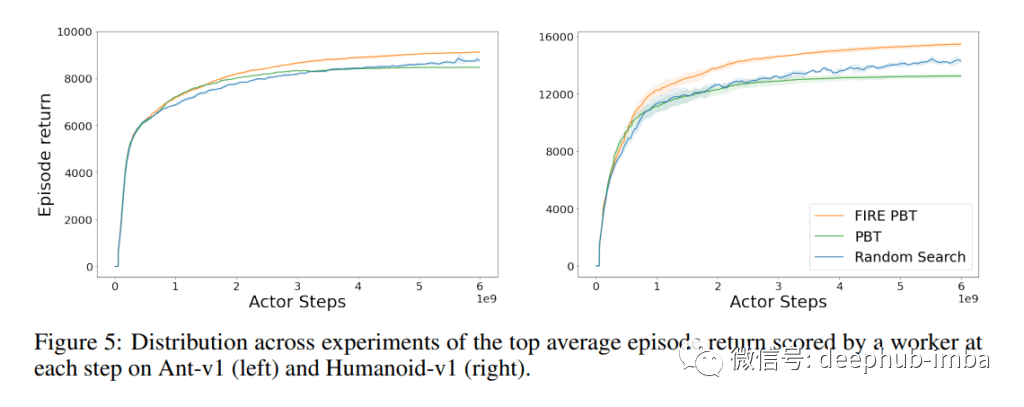
在强化学习任务中,FIRE PBT比PBT和RS表现出更快的学习和更高的成绩。
FIRE PBT可以找到与手工调优调度性能相匹配并且优于静态调度的合理超参数调度,该方法是一种改进速度更快、长期性能更好的有效方法。
论文axiv:2109.13800
喜欢就关注一下吧:
点个 在看 你最好看!********** **********