
Deephub
更多文章请关注公众号:Deephub-IMBA

使用Automatic1111在本地PC上运行SDXL 1.0
这是我们部署Stable Diffusion的第三篇文章了,前两篇文章都详细介绍了Automatic1111的stable-diffusion-webui的安装,这次主要介绍如何使用SDXL 1.0模型。
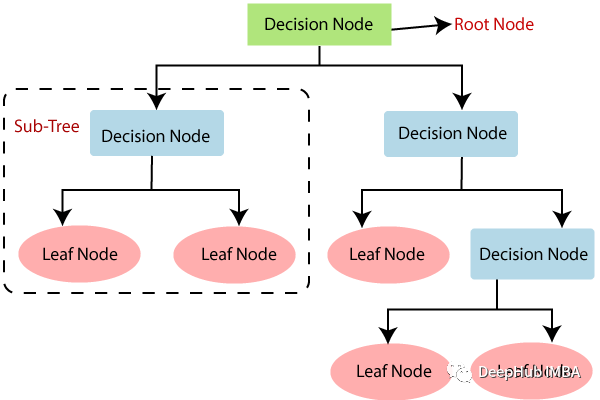
使用Python中从头开始构建决策树算法
决策树(Decision Tree)是一种常见的机器学习算法,被广泛应用于分类和回归任务中。并且再其之上的随机森林和提升树等算法一直是表格领域的最佳模型,所以本文将介绍理解其数学概念,并在Python中动手实现,这可以作为了解这类算法的基础知识。
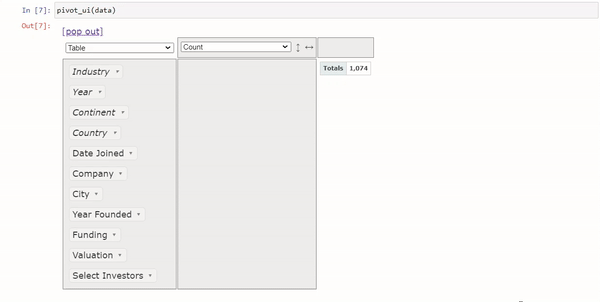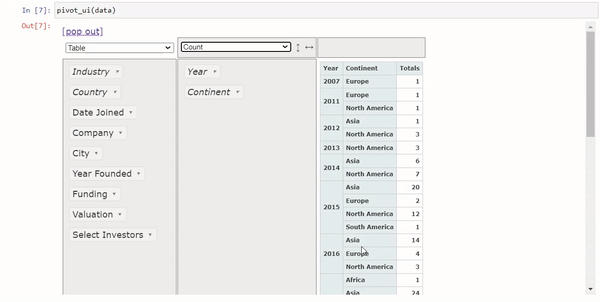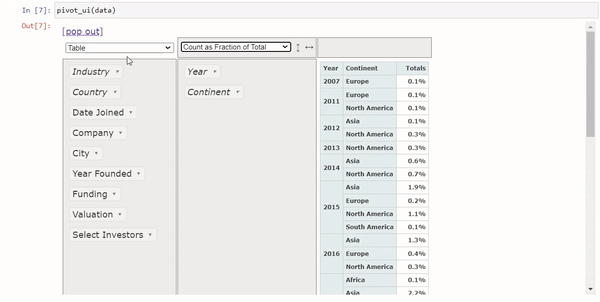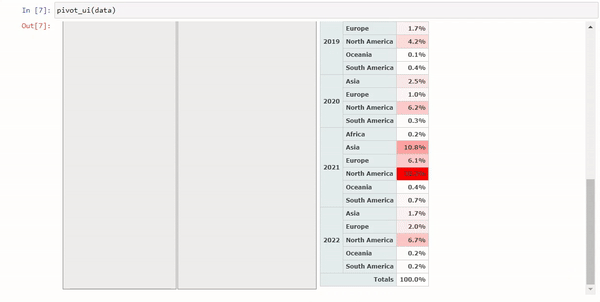
4个将Pandas换为交互式表格Python包
Pandas是我们日常处理表格数据最常用的包,但是对于数据分析来说,Pandas的DataFrame还不够直观,所以今天我们将介绍4个Python包,可以将Pandas的DataFrame转换交互式表格,让我们可以直接在上面进行数据分析的操作。
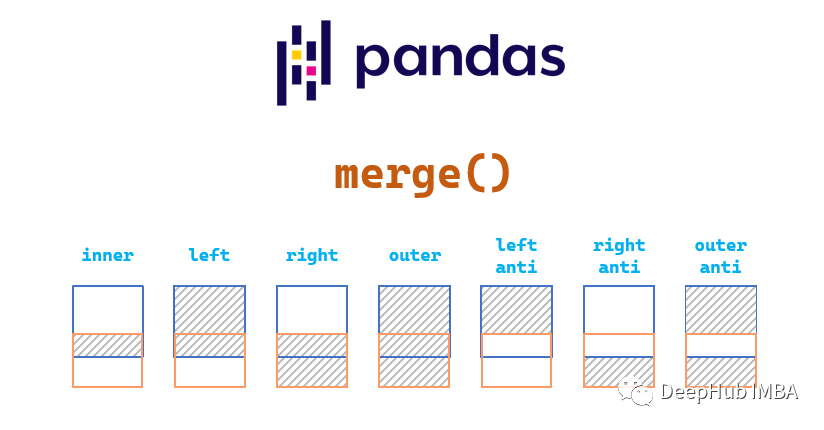
Pandas 的Merge函数详解
在日常工作中,我们可能会从多个数据集中获取数据,并且希望合并两个或多个不同的数据集。这时就可以使用Pandas包中的Merge函数。在本文中,我们将介绍用于合并数据的三个函数
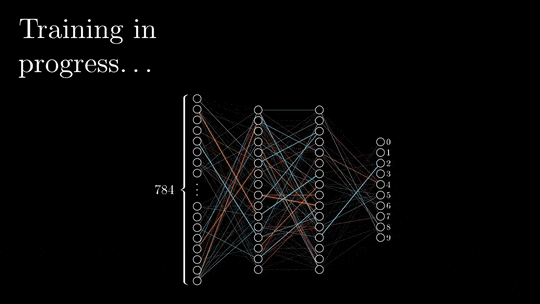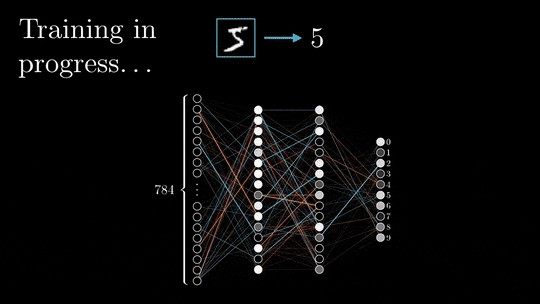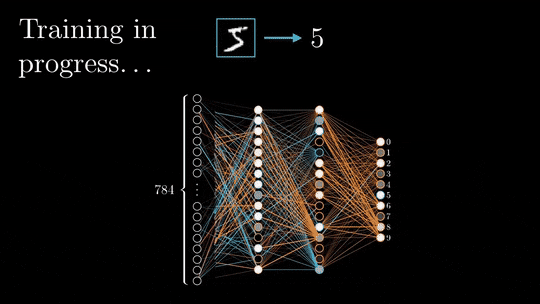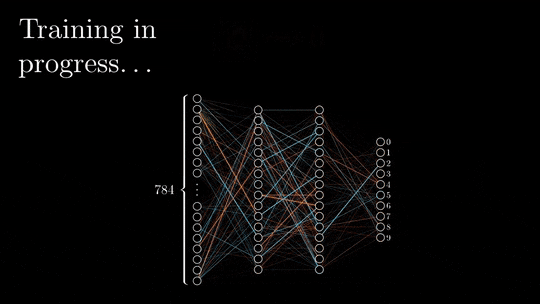
在消费级GPU调试LLM的三种方法:梯度检查点,LoRA和量化
LLM的问题就是权重参数太大,无法在我们本地消费级GPU上进行调试,所以我们将介绍3种在训练过程中减少内存消耗,节省大量时间的方法:梯度检查点,LoRA和量化。

使用 CausalPy 进行因果推理
这篇文章通过一个实际的例子简要介绍了因果推理,这个例子来自于《The Brave and True》一书,我们使用 CausalPy 来实现。
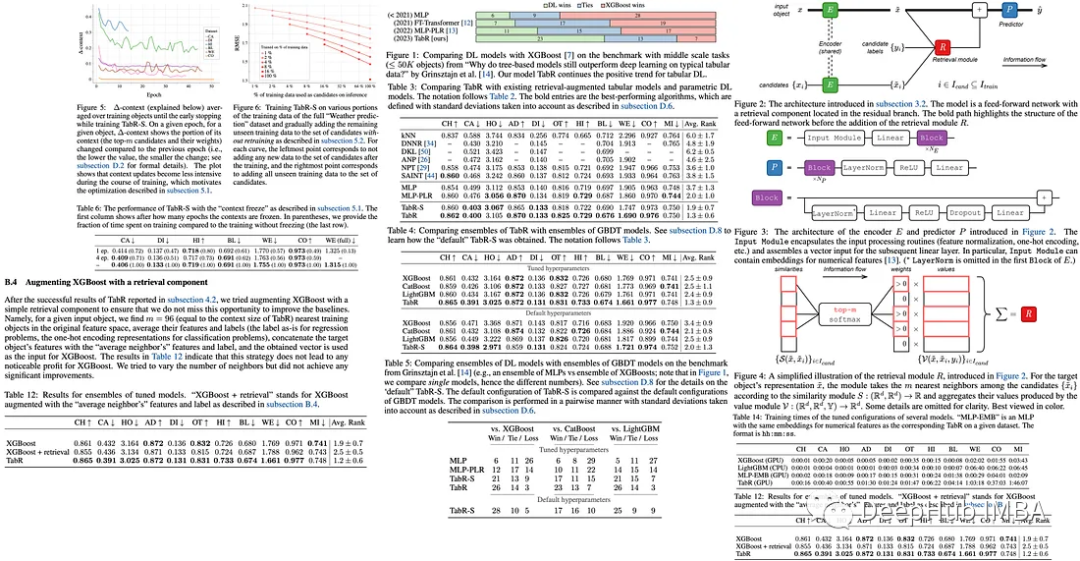
TabR:检索增强能否让深度学习在表格数据上超过梯度增强模型?
这是一篇7月新发布的论文,他提出了使用自然语言处理的检索增强*Retrieval Augmented*技术,目的是让深度学习在表格数据上超过梯度增强模型。

10个简单但很有用的Python装饰器
装饰器是Python中一个非常强大和常用的特性,它可以用于许多不同的情况,例如缓存、日志记录、权限控制等。

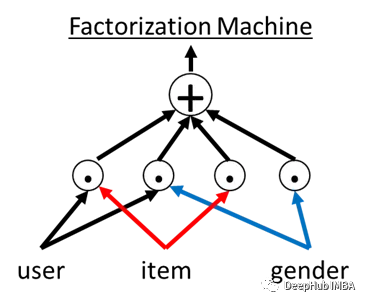
因子分解机介绍和PyTorch代码实现
因子分解机(Factorization Machines,简称FM)是一种用于解决推荐系统、回归和分类等机器学习任务的模型
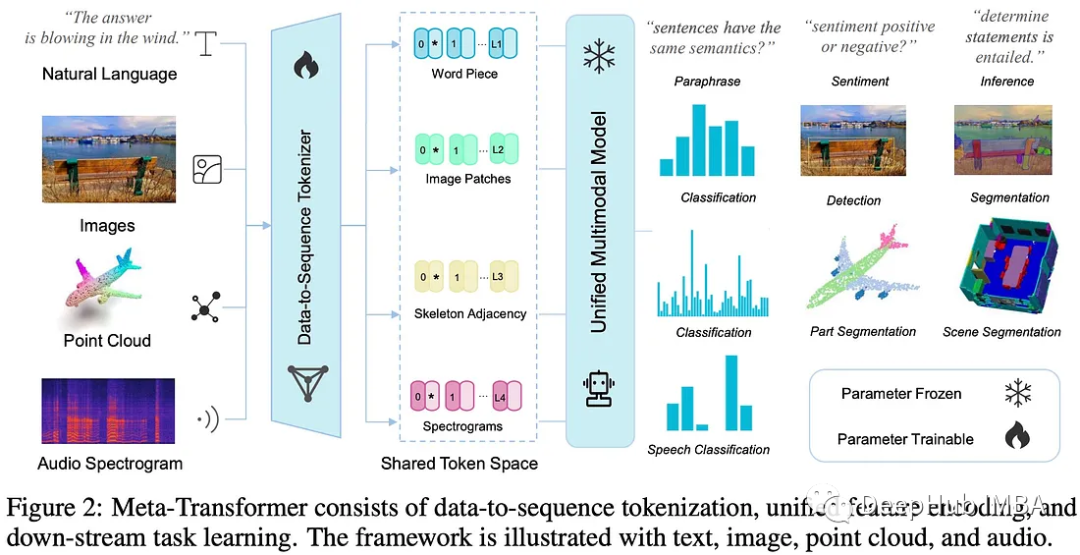
Meta-Transformer 多模态学习的统一框架
Meta-Transformer是一个用于多模态学习的新框架,用来处理和关联来自多种模态的信息
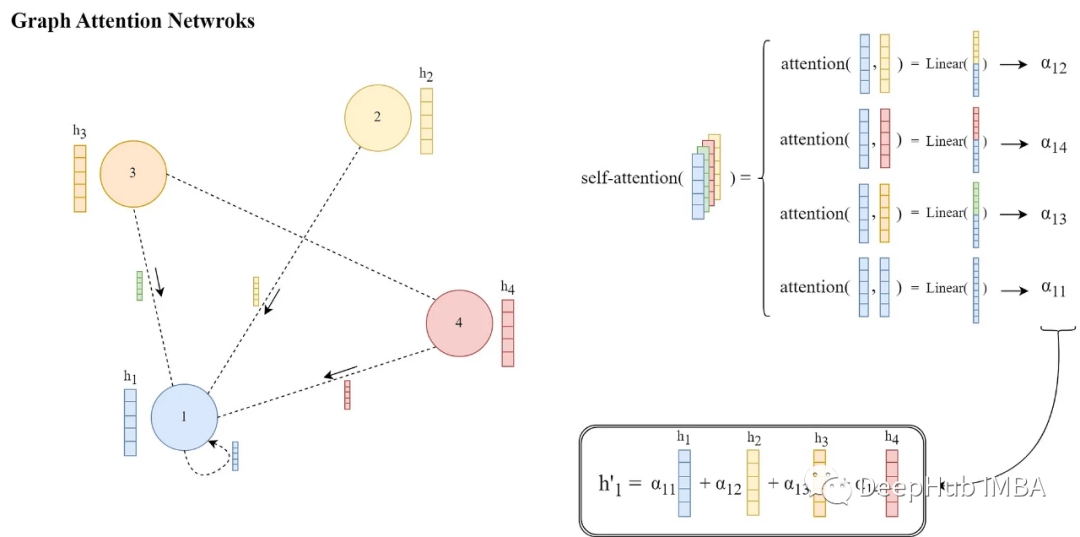
图注意力网络论文详解和PyTorch实现
图注意力网络(GAT)[1]是一类特殊的gnn,主要的改进是消息传递的方式。他们引入了一种可学习的注意力机制,通过在每个源节点和目标节点之间分配权重,
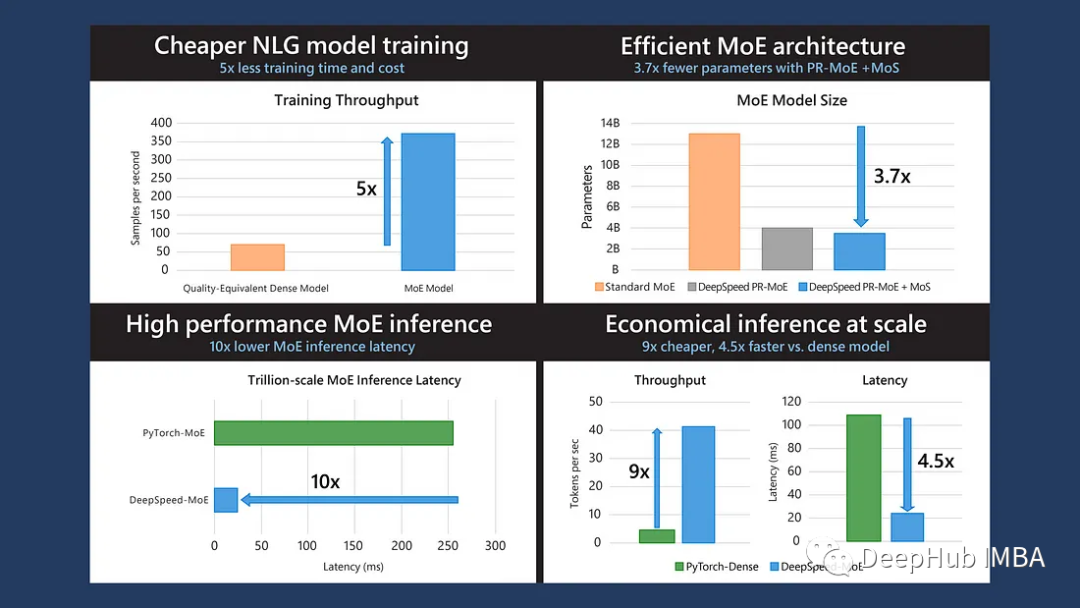
DeepSpeed-MoE:训练更大及更复杂的混合专家网络
这是微软发布在**2022 ICML**的论文,MoE可以降低训练成本,但是快速的MoE模型推理仍然是一个未解决的问题。所以论文提出了一个端到端的MoE训练和推理解决方案DeepSpeed-MoE:它包括新颖的MoE架构设计和模型压缩技术,可将MoE模型大小减少3.7倍;
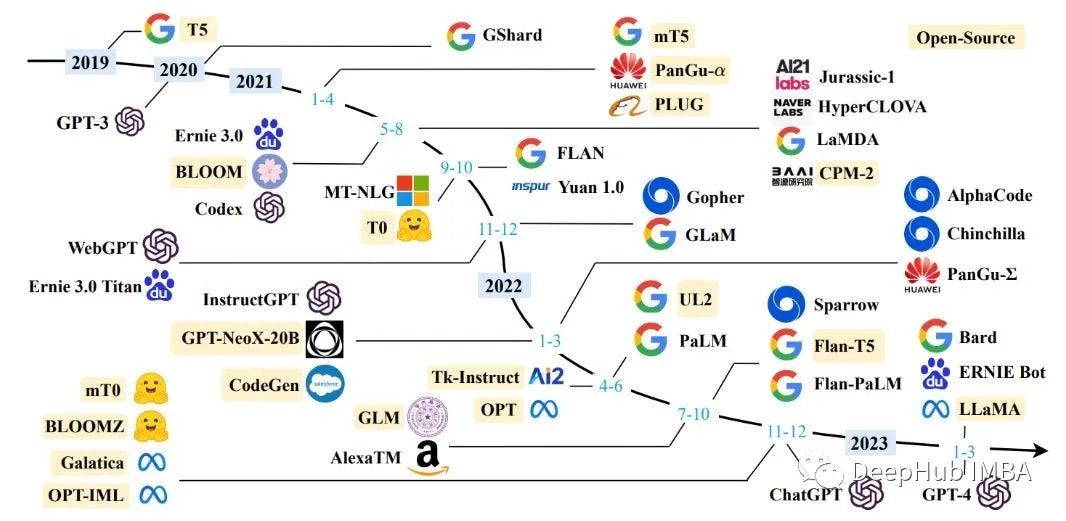
2023年发布的25个开源大型语言模型总结
本文总结了当前可用的开源llm的全部(几乎全部)列表,以及有关其许可选项和源代码存储库的信息,希望对你有所帮助

Python 3.11的10个使代码更加高效的新特性
在本文中我们将介绍Python 3.11新特性,通过代码示例演示这些技巧如何提高生产力并优化代码。
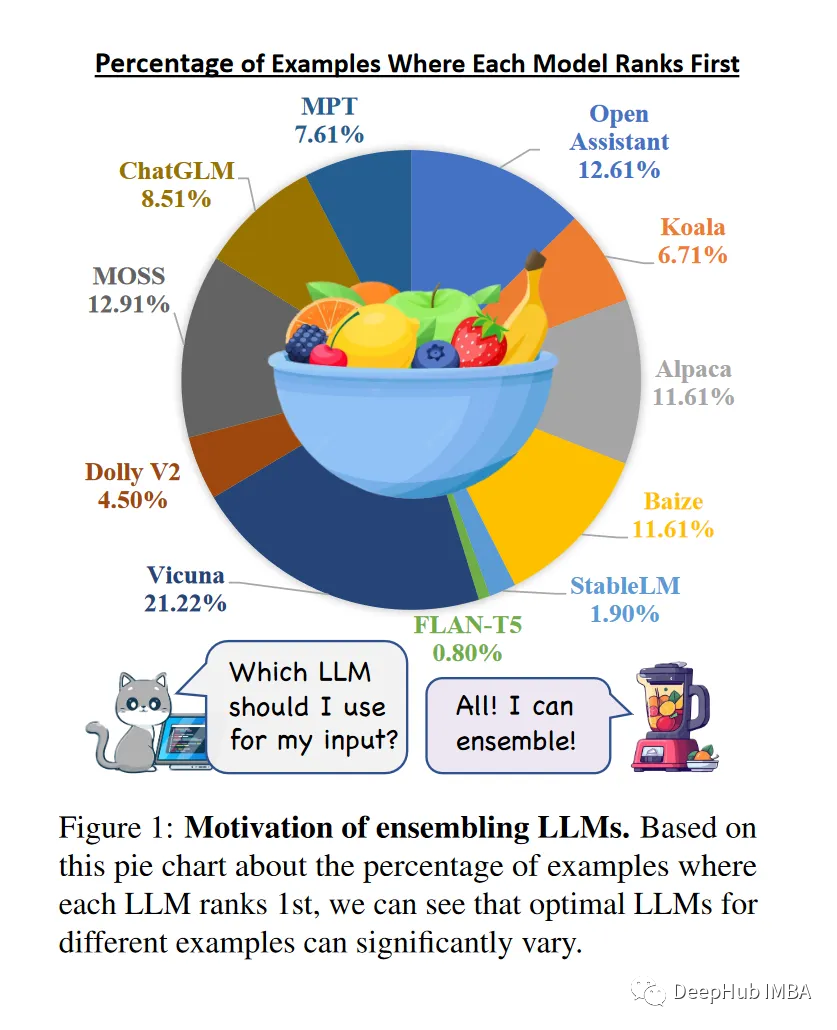
LLM-Blender:大语言模型也可以进行集成学习
LLM-Blender是一个集成框架,可以通过利用多个开源大型语言模型(llm)的不同优势来获得始终如一的卓越性能。
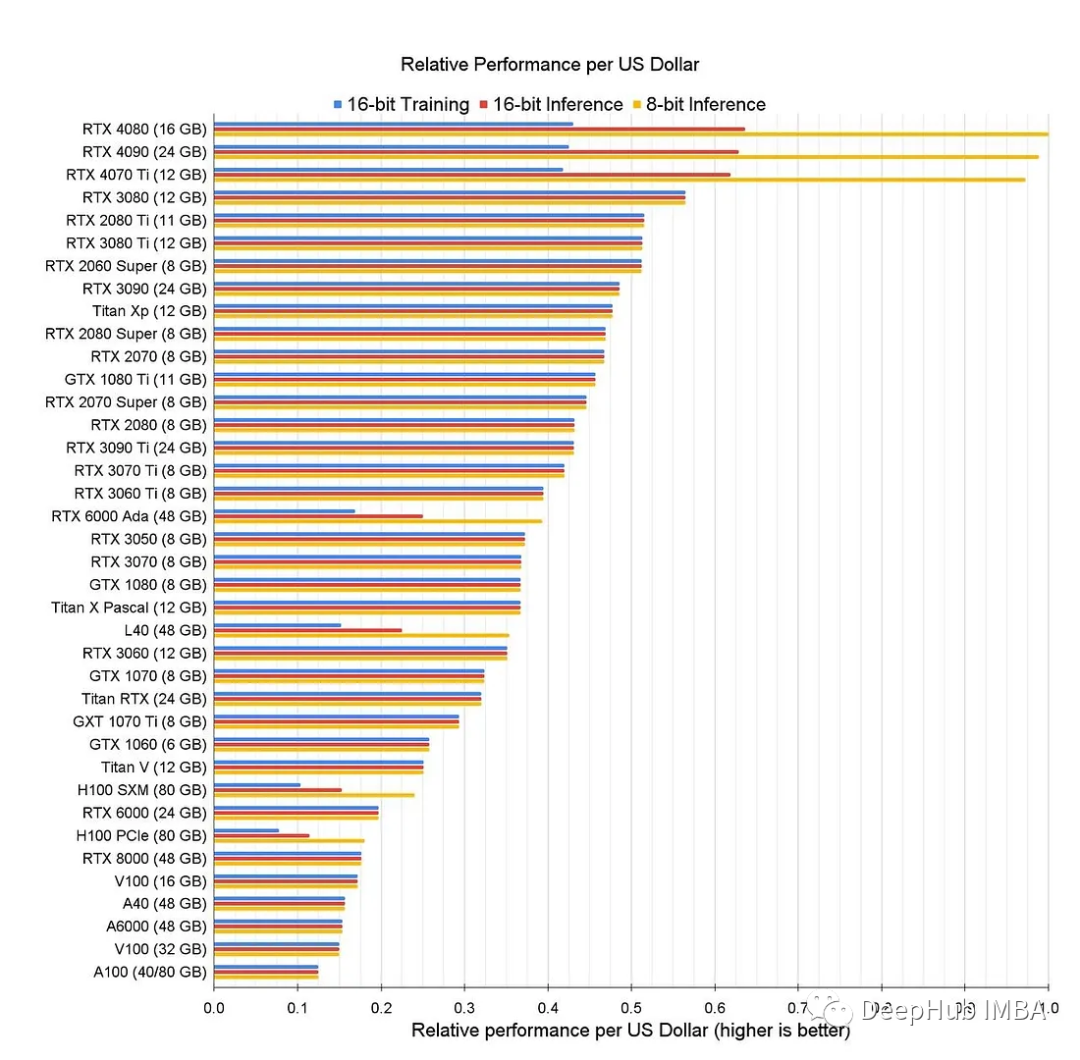
Stable Diffusion在各种显卡上的加速方式测试,最高可以提速211.2%
在本文中,我们将介绍这些加速方法的原理和性能测试结果,并提供对不同显卡的成本效益总结,我们的目标时在并在2秒内生成高质量的图像。

使用QLoRa微调Llama 2
上篇文章我们介绍了Llama 2的量化和部署,本篇文章将介绍使用PEFT库和QLoRa方法对Llama 27b预训练模型进行微调。我们将使用自定义数据集来构建情感分析模型。
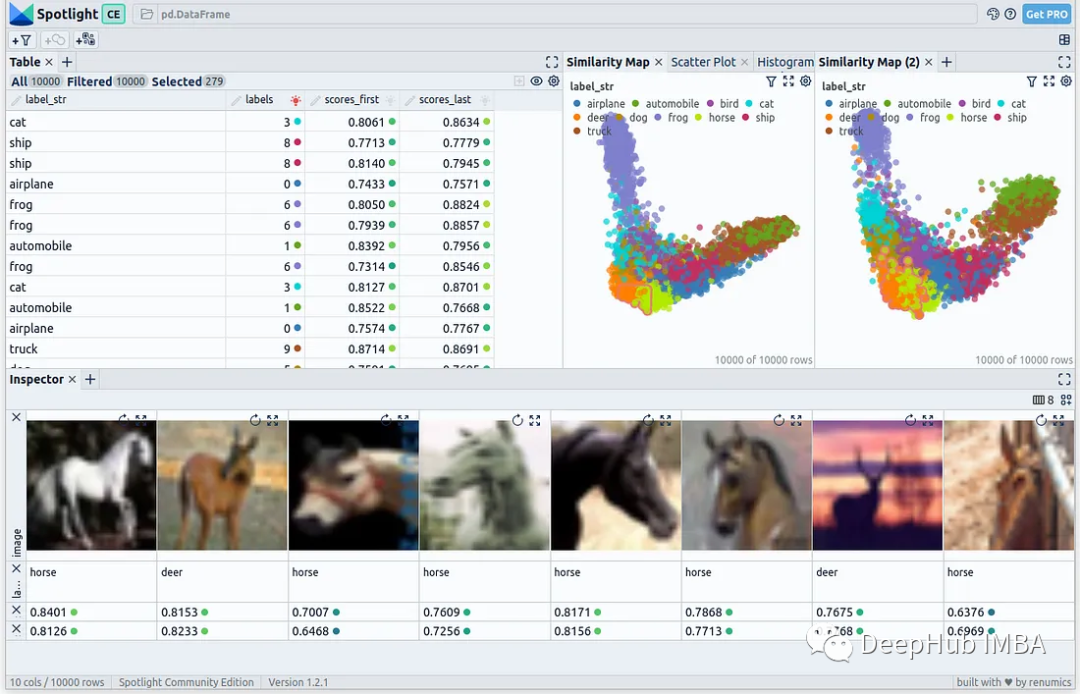
使用Cleanlab、PCA和Procrustes可视化ViT微调
在本文中,我们将介绍如何创建这样一个动画,主要包括:微调、创建嵌入、异常值检测、PCA、Procrustes、创建动画。

使用GGML和LangChain在CPU上运行量化的llama2
在本文,我们将紧跟趋势介绍如何在本地CPU推理上运行量化版本的开源Llama 2。