
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
近年来,Vision Transformer (ViT) 势头强劲。本文将解释论文《Do Vision Transformers See Like Convolutional Neural Networks?》 (Raghu et al., 2021) 由 Google Research 和 Google Brain 发表,并探讨传统CNN 和 Vision Transformer 之间的区别。
本文摘要
这篇论文有六个关于基于ResNet (He et al., 2016) 的 CNN 网络和 ViT 的核心观点:
- 与 CNN 相比,ViT 在浅层和深层获得的表征之间具有更多相似性
- 与 CNN 不同,ViT 从浅层获得全局表示,但从浅层获得的局部表示也很重要。
- ViT 中的跳过连接比 CNN (ResNet) 中的影响更大,并且显着影响表示的性能和相似性。
- ViT 比 ResNet 保留了更多的空间信息
- ViT可以用大量数据学习高质量的中间表示
- MLP-Mixer 的表示更接近 ViT 而不是 ResNet
本篇文章中,我将首先简要回顾 ResNet 和 ViT 的结构,它们是基于 CNN 的模型的代表性示例,然后仔细研究本文描述的获得的表示的差异。
ResNet 基础知识
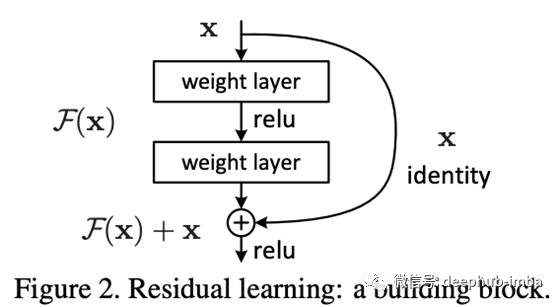
ResNet 是计算机视觉 (CV) 任务的流行模型。如下图 所示,ResNet 的加权传播侧使用跳过一层权重的残差连接进行求和。带有跳过连接的求和过程缓解了梯度消失等问题,并允许比以前的网络更深的层。
ViT基础知识
首先,让我们看一下 Vision Transformer (ViT) 中使用的Transformer 编码器。
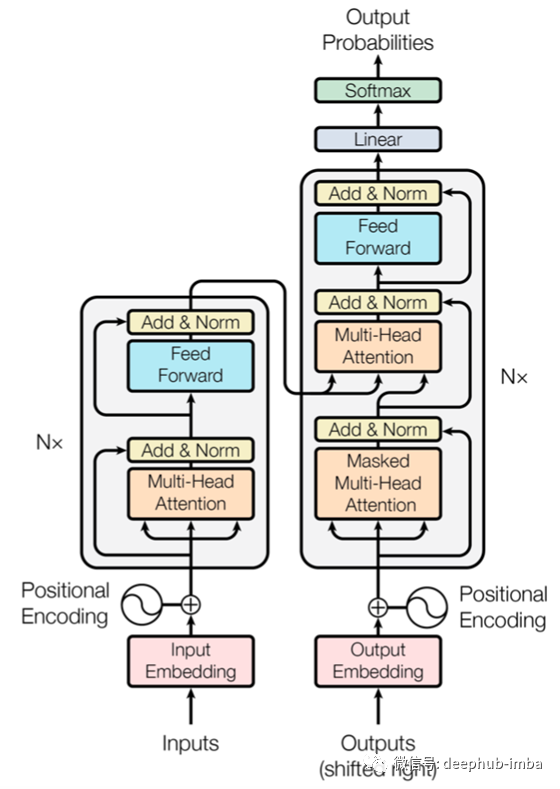
Transformer
Transformer 是论文“Attention Is All You Need”(Vaswani 等,2017)中提出的模型。它是使用一种称为自注意力(self-attention) 机制的模型,既不是 CNN 也不是 LSTM,并且使用的 Transformer 构建的模型以显著的优势,击败了提出时其他的方法。
注意下图中标记为Multi-Head Attention的部分是Transformer的核心部分,但它也像ResNet一样使用skip-joining。
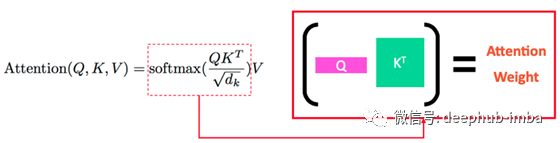
Transformer 中的注意力机制使用三个变量:Q(查询)、K(键)和 V(值)。简单地说,它计算一个 Query 令牌(令牌:类似单词的东西)和一个 Key 令牌的注意力权重并乘以与每个Key相关联的Value。简而言之,它计算 Query 令牌和 Key 令牌之间的关联(注意力权重),并将与每个 Key 关联的 Value 相乘。
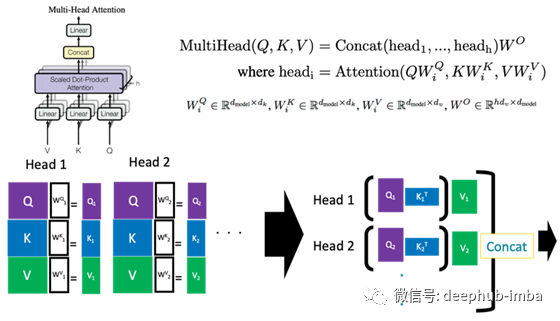
如果将Q, K, V计算定义为单头,则多头注意机制定义如下:上图中的(单头)注意机制使用了Q和K。然而,在多头注意机制中,每个头都有自己的投影矩阵W_i^Q、W_i^K和W_i^V,他们利用这些矩阵投影的特征值来计算注意力权重。
如果这个注意力机制中使用的Q、K、V是从同一个输入中计算出来的,则被称为Self-Attention。另一方面,Transformer 解码器的上部不是自注意力机制,因为它使用来自编码器的 Q 和来自解码器的 K 和 V 计算注意力。
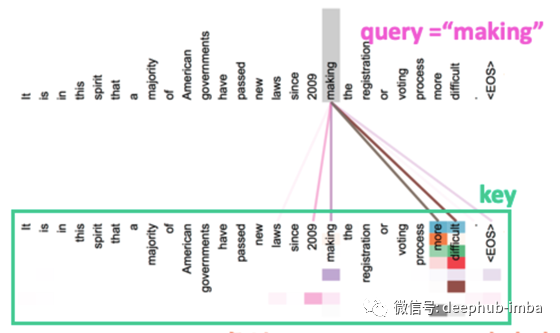
实际应用如下图所示。该图显示了使用单词“making”作为查询为每个 Key 令牌计算的注意力权重的可视化。Transformer 使用多头自注意力机制传播到后面的层,每个头学习不同的依赖关系。下图中的关键词用颜色表示,代表每个头部的注意力权重。
ViT
Vision Transformer (ViT) 是一种将 Transformer 应用于图像分类任务的模型,于 2020 年 10 月提出(Dosovitskiy et al. 2020)。模型架构几乎与原始 Transformer 相同,但有一点不同,允许将图像做为输入,就像自然语言处理一样。
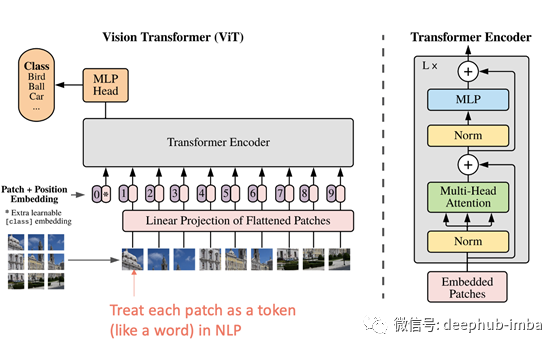
首先,ViT 将图像分成 N 个“patches ”,例如 16x16。由于patches 本身是 3D 数据(高 x 宽 x 通道数),它们不能由处理语言(2D)的转换器直接处理,因此需要将它们展平并进行线性投影转换为 2D 数据。所以每个patch都可以看作是一个可以输入到Transformer中的零令牌。
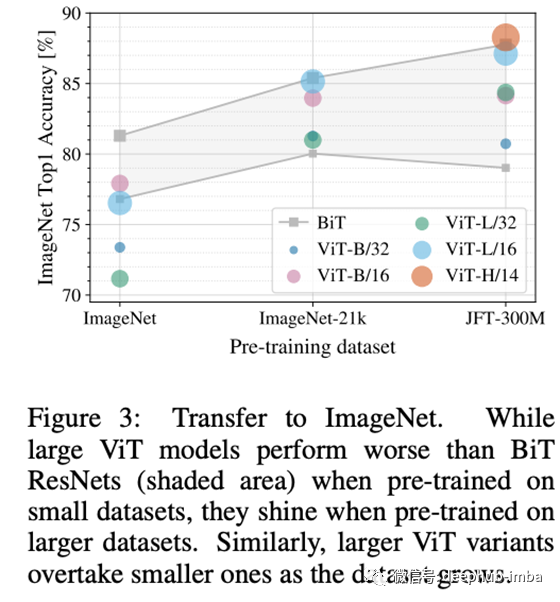
另外,ViT采用先预训练再微调的策略。ViT 使用 JFT-300M(一个包含 3 亿张图像的数据集)进行预训练,然后在 ImageNet 等下游任务上进行微调。ViT 是第一个在 ImageNet 上实现 SotA 性能的纯 Transformer 模型,这使得 Transformer 应用于计算机视觉任务的研究激增。
但是训练 ViT 需要大量数据。Transformer 数据越少精度越低,数据越多精度越高,并且在 JFT-300M 上进行预训练时性能优于 CNN。
比较 ResNet 和 ViT
到目前为止,我们已经看到了 ResNet 和 ViT 的概述,它们都可以在图像识别任务中表现良好,但是它们之间有什么区别呢?在论文“Do Vision Transformers See Like Convolutional Neural Networks?”中,作者对其进行了研究。
1、与 CNN 相比,ViT 在浅层和深层获得的表征之间具有更多相似性
ViT 和 ResNet 之间的主要区别之一是初始层的大视野。
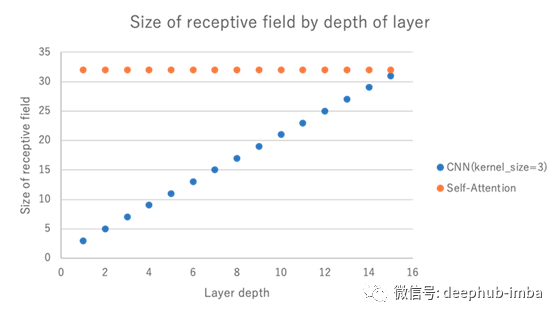
CNN(ResNet)只有一个固定大小的内核视野(大小为 3 或 7)。具体来说,CNNs 通过对内核周围的信息逐层反复“卷积”,逐渐扩大视野。相比之下,ViT 使用了一种自注意力机制,让模型即使在最底层也能拥有整个视野。当然视野也会因网络的结构而异。
下图展示了ViT的实际视野(自注意力机制的有效距离)。在浅层有一些像CNN这样具有局部视野的部分,但也有很多具有全局视野的头部。
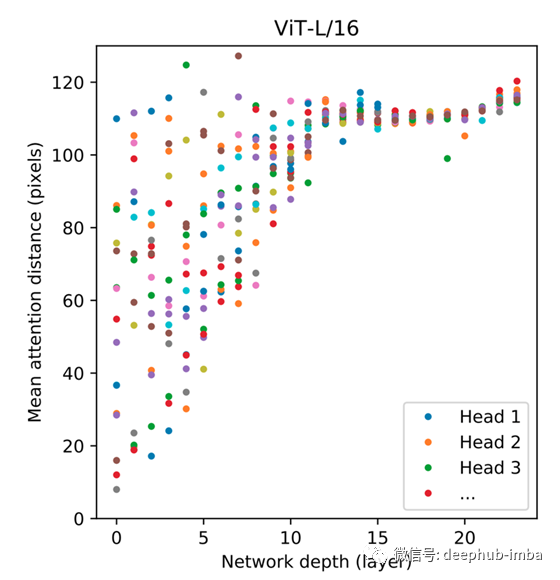
那么,ResNet和ViT在每一层深度获得的表示结构上有什么不同呢?为了找出答案,作者在下面的图中绘制了每一层获得的表示的相似度。
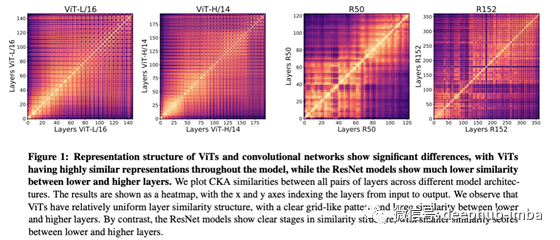
在上图中,他们用一个叫做CKA相似度的度量方法绘制了每一层得到表示的相似度(这里不会详细介绍CKA相似度的技术细节,如果你想了解更多请参阅原文)。图的对角线部分相似度肯定是高的,因为它与自身相似,但让我们看看图的其他部分。
首先,在ViT(左边两个)中,我们可以看到,不管层的深度如何,总体颜色都表明获得了相似的表示。另一方面,在CNN(右边两个)中,我们注意到在浅层和深层获得的表示之间没有相似之处。这可能是因为在ViT中,我们从一开始就得到了全局表示,而在CNN中,我们需要传播层来得到全局表示。
ViT和ResNet之间的相似性绘制在下面的图中
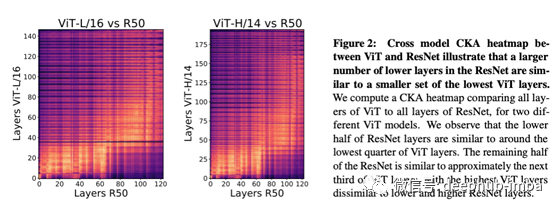
我们可以看到,ViT的第1层到第40层和ResNet的第1层到第70层之间的相似性很高。所以ResNet需要70层才能获得表示,而ViT需要40层就能获得了。这意味着获取浅层表示的方法是非常不同的。此外,ViT的深层与ResNet的深层相似度较低。因此,ViT和ResNet在图像的抽象表示上有很大的不同。
顺便说一下,一些研究的动机是由于自注意力图的相似性,ViT 没有从深化中受益(Zhou et al., 2021])。本研究侧重于头部之间的高度多样性,并提出了一种称为 Re-Attention 的机制,该机制引入了一个学习参数来混合不同头部之间的特征。他们使用它(DeepViT)取得了很好的效果。
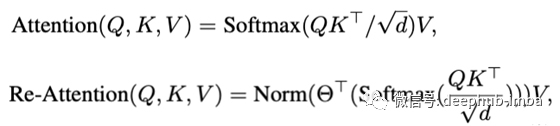
2、与cnn不同,ViT从浅层获得全局表示,但从浅层获得的局部表示也很重要
下图显示了使用JFT-300M预训练(3亿张图片)和ImageNet微调(130万张图片)后,预训练和ImageNet微调后的自注意力机制的有效距离(5000个数据的自注意力距离的平均值)
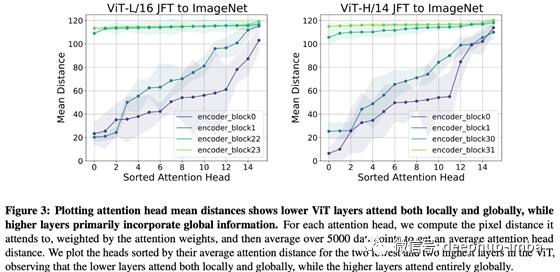
在浅层 (encoder_block0, 1) 中,我们可以看到模型同时获得局部和全局表示,而在深层 (encoder_block22, 23, 30, 31) 中,所有表示都有全局视图。
正如我们在描述中看到的,训练 ViT 需要大量的数据(例如 JFT-300M),如果数据不足准确率就会下降。下图显示了这种情况。
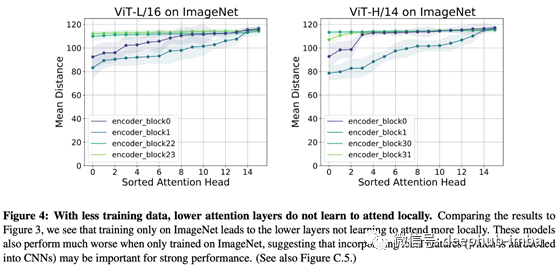
如果我们比较图 3 和图 4 可以看到,当数据集很小时,我们无法在浅层中获得局部表示。从这个结果和“ViT在数据小的时候不能达到准确率”这一事实,我们可以看出,用足够的数据训练的ViT得到的“局部表征”对准确率有显着的影响。
但是数据量和获得的表示之间是什么关系呢?下图说明了这一点。
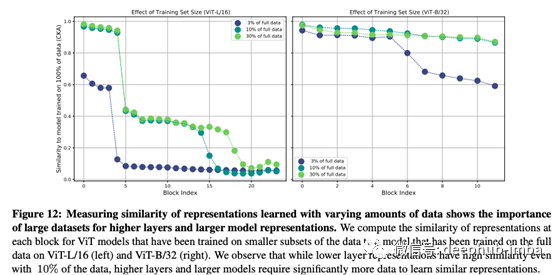
对于浅层表示,大约有 10% 的数据与使用所有数据获得的表示的相似度类似。对于深层表示即使有 30% 的数据相似度也低于 0.2。由此我们可以说有助于准确性的深层表示只能通过大量数据来学习。前面提到局部表示很重要,但似乎可以在深层获得的全局表示也很重要。
虽然这里没有具体说明,但实验很可能是用JFT-300M进行的,所以即使我们说总数据的3%,仍然有大约10M的数据量(大约是ImageNet的10倍)。在我看来30%的数据(100M)就足以得到浅层应该得到的局部表征,如果数据多,就有可能得到全局表征中重要的东西。
3、ViT 中的跳过连接比 CNN (ResNet) 中的影响更大,并且显着影响表示的性能和相似性
接下来,我们来看看跳过连接和习得表达式的相似度之间的关系。如下图所示。

在如图所示的实验中,我们计算当第i层的跳过连接被消除时获得的表示的相似度。将此图与图 1 (CKA相似度部分那张图)的左侧(ViT)进行比较,可以看到在消除跳过连接的第 i 层之后,获取的表示的相似趋势发生了剧烈变化。换句话说,跳过链接对表示传播有显着影响,当它被消除时层的相似性会发生显着变化。另外就是在中间层消除跳过连接时,准确率下降了大约 4%。
接下来,我们来看看跳过连接在信息传播中是如何发挥作用的。请看下图。
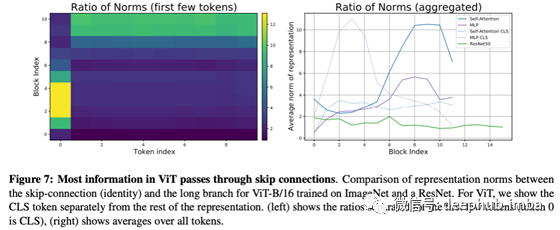
在图中,比率越大通过跳过加入传播的信息就越多;左边的图显示类的令牌是通过在初始层中的跳过连接传播的,而图像是通过自注意和多层网络传播的,这种趋势在更深层次上发生了逆转。
右图显示了与 ResNet 的比较。绿线是 ResNet,而 ViT 的值更大,表明通过跳跃连接点的信息传播起主要作用。
虽然论文中没有具体提到,但由于skip-joining在信息传播中起主要作用这一事实可能导致在图8(上上图)中消除中间层的跳过链接时准确率显着下降。
4、ViT比ResNet保留更多的空间信息
接下来,让我们比较ViT和ResNet保留了多少位置信息。请看下图。
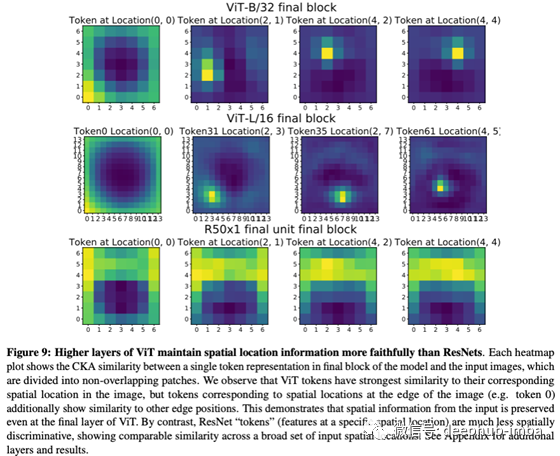
作者通过绘制输入图像的一个patch与最后一层feature map在某一位置的CKA相似性来测试ViT和ResNet是否保留了位置信息。如果保留了位置信息,那么只有在feature map中与该位置对应的位置上与输入图像的patch在某个位置上的相似度才应该较高。
首先,让我们看一下ViT(上、中)。正如预期的那样在最后一层对应位置的相似性很高。这意味着ViT在传播表示的同时保留位置信息。接下来,让我们看看ResNet(底部一行)。在这种情况下,不相关位置的相似性较高,说明它不保留位置信息。
这种趋势上的差异可能是由于网络结构的不同造成的。请看下图(该图摘自Wang et al., 2021年)。
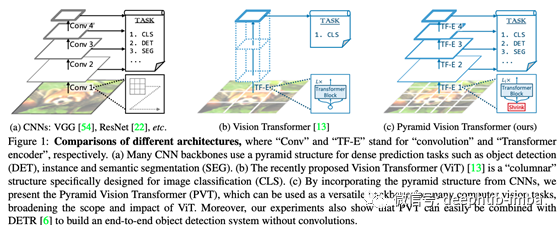
ResNet和其他基于cnn的图像分类网络以降低的分辨率传播表示。例如,ResNet有五个阶段,每个阶段的分辨率减半,所以最终的feature map大小是1/32 * 1/32(左图)。另一方面,ViT首先标记为16x16大小,这降低了该区域的分辨率,但它会以该分辨率传播到最后一层。因此ViT比ResNet更有可能保留位置信息。但是首先,图像分类任务不需要位置信息来进行分类决策,所以不能说因为位置信息被保留了ViT就比ResNet更有优势。
此外,在最近的研究中,在Vision Transformer的相关研究中经常使用ResNet等逐步降低分辨率的策略。例如右上方的Pyramid Vision Transformer。Transformer系统使用自注意力,占用的内存大小与图像大小的四次方成比例增加。这使得处理大分辨率变得困难,但通过使用逐渐降低分辨率的策略,如在CNN系统中,可以在节省内存的同时在第一层处理高分辨率的信息。
5、ViT可以学习具有大量数据的高质量中间表示
接下来,让我们看看中间层表示的质量。下图显示了这个实验。
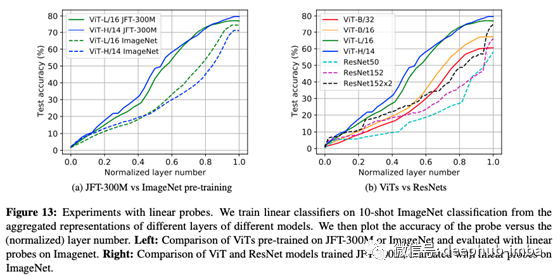
在这个实验中,作者试图查看他们是否可以使用中间层的表示来用线性模型进行分类。简单模型(如线性模型)的精度越高,层得到的表示就越好。
首先,让我们看看数据集的大小和获得的表示之间的关系(左图)。在这里,我们比较了ImageNet(虚线)和JFT-300M(实线)上的实验结果,ImageNet包含130万张图片,JFT-300M包含3亿张图片。在JFT-300M上训练的表示更好因为JFT-300M是一个庞大的数据集。接下来是包括ResNet在内的模型的比较可以看出,模型越大表示效果越好。
附注:在右图中,基于resnet的模型的精度在接近最后一层时突然增加。这是为什么呢?
Frosst 及其同事的一项研究提供了一个提示(Frosst 等人,2019 年)。他们将带有temperature term的 Soft Nearest Neighbor Loss 引入 ResNet 的中间层并研究其行为。Soft Nearest Neighbor Loss 按类别表示特征的纠缠状态。Soft Nearest Neighbor Loss 值大表示按类的特征是交织在一起的,而小值表示按类的特征是分开的。
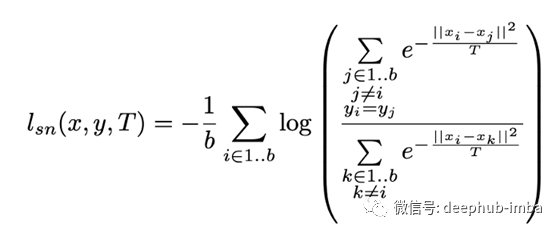
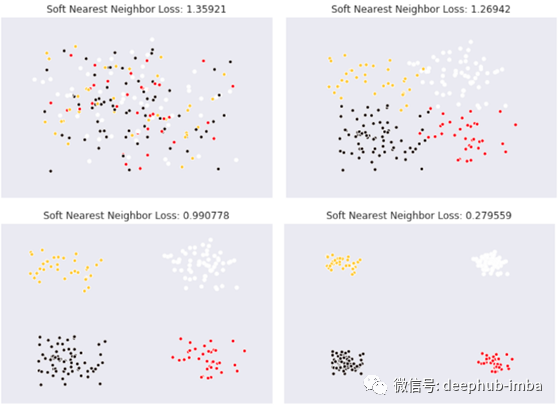
Soft Nearest Neighbor Loss [软最近邻损失]
下图显示了ResNet中每个区块的软最近邻损失值。它是一种高性能的图像分类网络,但除了最后一层以外,它不分离每个类别的特征。在我看来ResNet的这一特性可能是最后一层附近精度快速提高的原因,如图13所示。
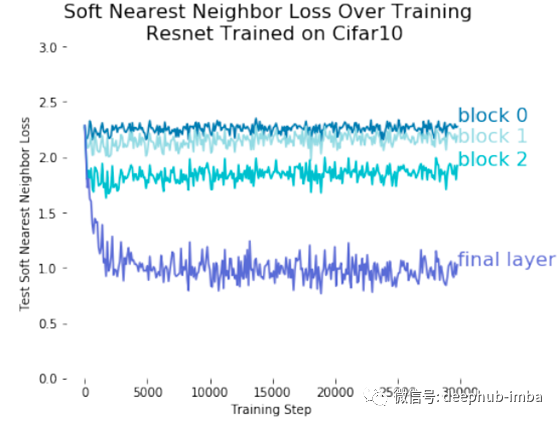
在最后一层,软最近邻损失值较小,说明特征是按类别划分的。(Frosst等人,2019年)
6、MLP-Mixer的表示更接近ViT而不是ResNet
近年来,利用多层感知器(MLPs)即具有密集层的网络,已经超过transformers成为最高精度的图像分类模型。一个典型的例子是名为MLP-Mixer的网络(Tolstikhin et al., 2021)。该网络的结构如下图所示。
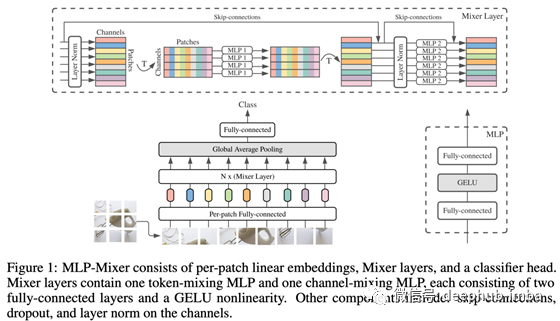
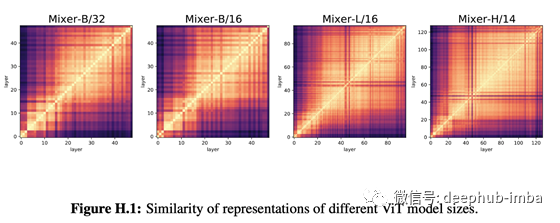
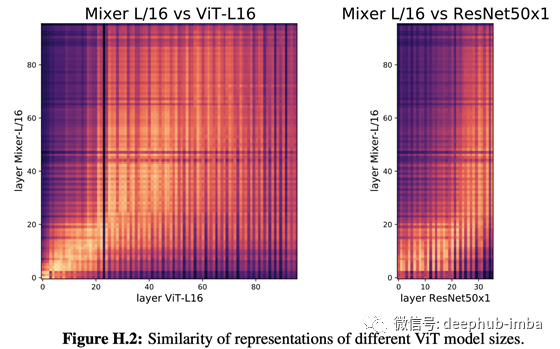
MLP-Mixer是一个系统,它使用MLP1在patches 之间混合信息,然后使用MLP2在patches 内混合信息,然后通过堆积将两者结合的块进行传播。该 MLP-Mixer 可以达到与 ViT 相同或更高的精度。下图以与之前相同的方式比较了 MLP-Mixer 的表示。将此图与图 1 和图 2 进行比较,作者表示总体趋势与 ViT 相似。
MLP-Mixer通过将图像分割成像ViT这样的patchs来传播图像,因此它在结构上更接近ViT而不是ResNet。这种结构可能是导致这种结果的原因。
总结
在本文中,我详细研究了 ViT 和 CNN 之间的差异。回顾一下,以下是两者之间的一些差异。Transformers 将继续成为计算机视觉领域的主要影响力。我希望这篇文章能帮助你理解Transformers。
- 与 CNN 相比,ViT 在浅层和深层获得的表征之间具有更多相似性
- 与 CNN 不同,ViT 从浅层获得全局表示,但从浅层获得的局部表示也很重要。
- ViT 中的跳过连接比 CNN (ResNet) 中的影响更大,并且显着影响表示的性能和相似性。
- ViT 比 ResNet 保留了更多的空间信息
- ViT可以用大量数据学习高质量的中间表示
Do Vision Transformers See Like Convolutional Neural Networks? arxiv 2108.08810
作者:Akihiro FUJII
喜欢就关注一下吧:
点个 在看 你最好看!********** **********