
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
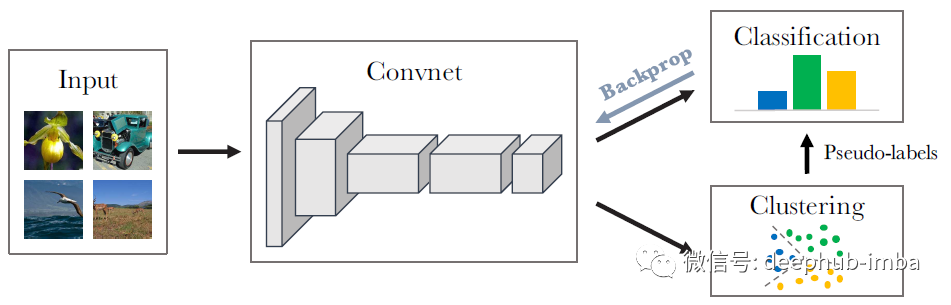
在这篇文章中,我们要简单介绍Facebook 的“Deep Clustering for Unsupervised Learning of Visual Features”。
DeepCluster 将神经网络的参数和结果特征的聚类分配一起进行联合学习。
DeepCluster 使用标准聚类算法 k-means 对特征进行迭代分组,并使用后续结果作为监督的伪标签来更新网络的权重。
这是一篇2018年ECCV的论文,目前被引用超过900次。
本文所使用的符号
在谈论 DeepCluster 之前,让我们使用监督学习定义一些符号。
- 给定 N 个图像的训练集 X = {x1, x2, ..., xN},我们想要找到一个参数 θ∗ 使得映射 f 能够产生良好的通用特征。
- 这些参数传统上是通过监督学习的,即每个图像 xn 都与 {0, 1}^k 中的标签 yn 相关联。这个标签表示图像与k个可能的预定义类中的一个的关s系。
- 参数化分类器 gW 在特征 f (xn) 之上预测正确的标签。
- 因此,损失函数为(公式(1)):
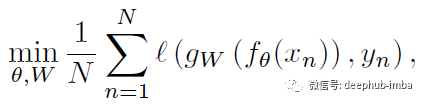
- 其中 ℓ 是多项对数损失
- 使用小批量随机梯度下降和反向传播来计算梯度来最小化这个损失函数
DeepCluster 作为自监督学习中的代理任务(pretext task)
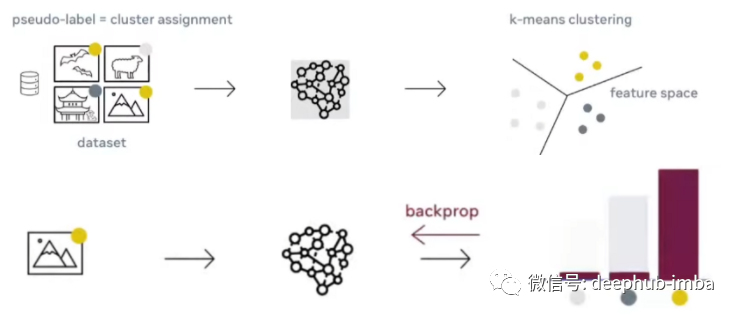
图中的上面部分:基于CNN生成向量的k-Means聚类;下面部分:使用聚类结果作为伪标签进行反向传播
DeepCluster 过程
DeepCluster工作的想法是利用这个信号来引导 convnet 的判别能力。
我们对 convnet 的输出进行聚类并使用后续的聚类的结果作为“伪标签”来优化上面的提到的公式(1). 这种深度聚类 (DeepCluster) 方法迭代地学习特征并对它们进行分组。。
其中聚类是使用标准聚类算法 k-means。
k-means 将一组向量作为输入,在我们的例子中是由 convnet 产生的特征 f(xn),并根据几何准则将它们聚类为 k 个不同的组。
更准确地说,它通过解决以下问题(公式(2))来联合学习 d×k 质心矩阵 C 和每个图像 n 的聚类分配 yn:
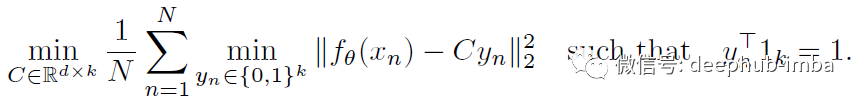
总体而言,DeepCluster 交替使用公式(2)对特征进行聚类以生成伪标签或通过使用公式 (1)预测这些伪标签来更新网络的参数。
避免空簇
有可能产生最佳决策边界是将所有输入分配给单个簇。这个问题是由于缺乏防止空簇的机制造成的。更详细的说,当一个簇变空时随机选择一个非空簇,并将其质心与一个小的随机扰动一起用作空簇的新质心。然后将属于非空簇的点重新分配给两个结果簇。
Trivial parametrization
在聚类中Trivial parametrization的含义为大量的数据被聚类到少量的几类上,我也不知道中文翻译成什么,所以就直接写英文了。这种情况下网络可能对于任意的输入都产生相同的输出。如果绝大多数图像被分配到几个簇,参数 θ 将专门用来区分它们。另外解决这个问题的方法是根据类别(或伪标签)对样本进行均匀采样。
对DeepCluster进行分析
标准化互信息 (NMI)
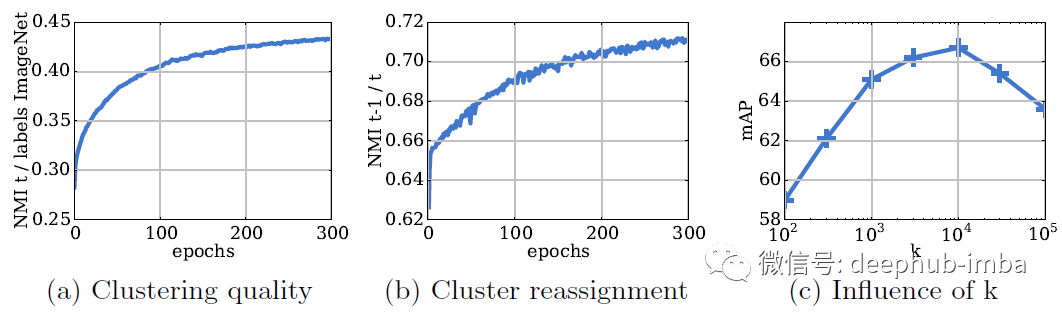
(a):聚类质量随训练轮次的变化;(b):在每个聚类步骤中聚类重新分配的变化;(c): 针对 k 的分类结果验证 mAP 性能
标准化互信息 (NMI),用于评估:
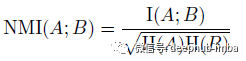
其中 I 表示互信息,H 表示熵。
如果两个分配 A 和 B 是独立的,则 NMI 等于 0。如果其中一个可以从另一个确定性地预测,则 NMI 等于 1
- 簇和标签之间的依赖性随着时间的推移而增加,表明学习到的特征逐渐捕获与对象分类相关的信息。
- NMI 正在增加,这意味着重新分配越来越少,并且簇随着时间的推移而趋于稳定。
- 在 k=10,000 时获得最佳性能。鉴于 ImageNet 有 1000 个类。显然,一定程度的过度分割是有益的。
可视化

从 YFCC100M 的 100 万张图像的子集中过滤可视化和前 9 个激活图像
正如预想的那样,网络中更深的层似乎捕获了更大的纹理结构。

上层的过滤器包含有关与对象类高度相关的结构的信息。底层的过滤器似乎根据样式触发,例如绘图或抽象形状。
DeepCluster性能对比
ImageNet 和 Places 上线性分类
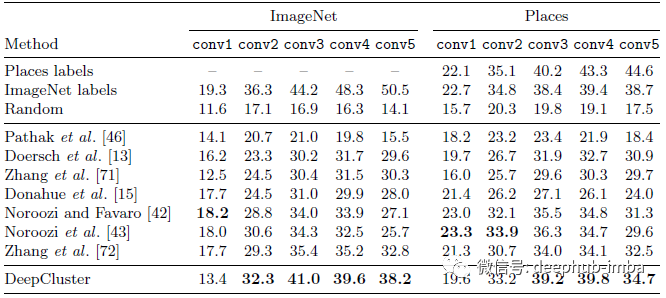
ImageNet
冻结不同的卷积层之上训练线性分类器。在 ImageNet 上,DeepCluster 从 conv2 到 conv5 层的性能优于现有技术 1-6%。在 conv3 层中观察到了最大的改进。
如果在最后一层训练 MLP,DeepCluster 的性能将比现有技术高 8%。
DeepCluster 和 AlexNet 之间的性能差异在更高层上显着增加:在 conv2-conv3 层,差异仅为 4% 左右,但在 conv5 上这一差异上升到 12.3%,这说明 AlexNet 可能存储了大部分分类信息。
Places
DeepCluster 产生的 conv3-4 特征与使用 ImageNet 标签训练的特征相当。
这表明当目标任务与 ImageNet 覆盖的域足够远时,分类的标签就不那么重要了。
Pascal VOC
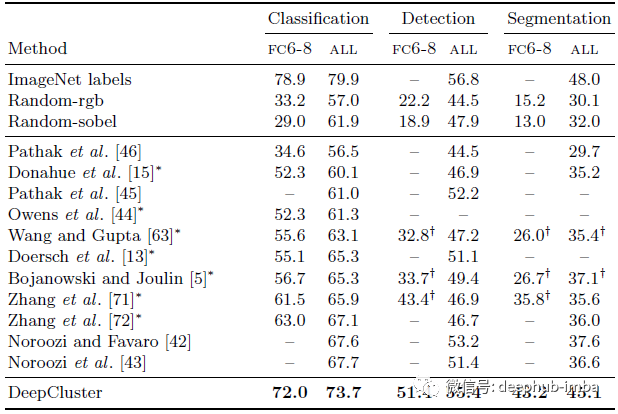
在 Pascal VOC 上进行分类、检测和分割的最先进无监督特征学习方法的比较
在所有三个任务中,DeepCluster 在所有设置中都优于以前的无监督方法,例如Context Prediction [13], Context Encoders [46], Colorization [71], Split-Brain Auto [72], Jigsaw Puzzles [42]
- 对现有技术的微调改进最大的是语义分割(7.5%)。
- 在检测方面,DeepCluster 的性能仅略好于之前发布的方法。有趣的是,与许多无监督方法相比,微调随机网络的性能相对较差,但如果只学习了 fc6-8,则性能很差。
YFCC100M
基于Pascal VOC迁移任务的训练集对DeepCluster性能的影响
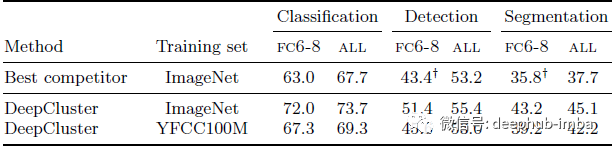
- 在 YFCC100M 中,分类严重不平衡,导致数据分布不利于 DeepCluster。
- 该实验验证了 DeepCluster 对图像分布变化的鲁棒性,即使这种分布不利于其设计,也能产生最先进的通用视觉特征。
AlexNet 与 VGGNet
使用 AlexNet 和 VGG16 的 Pascal VOC 2007 目标检测
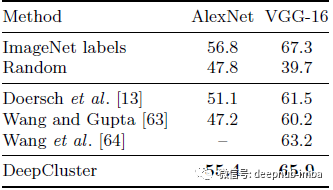
在之前的实验中,使用了 AlexNet。这里尝试了一个更深的网络 VGGNet。使用 DeepCluster 训练 VGG-16 的性能高于最先进的水平,使我们仅比传统的有监督的SOTA低 1.4%。
图像检索
使用 VGG16 在牛津和巴黎数据集上进行实例级图像检索的 mAP
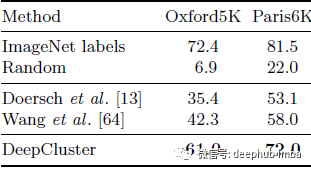
上表表明,图像检索中预训练是必不可少的,将其作为下游任务进行研究可以进一步了解无监督方法产生的特征的质量。
最后,这个方法最主要问题之一是 k 均值聚类需要相当多的时间。
引用
[2018 ECCV] [DeepCluster]Deep Clustering for Unsupervised Learning of Visual Features
Self-Supervised Learning
2008–2010 [Stacked Denoising Autoencoders] 2014 [Exemplar-CNN] 2015 [Context Prediction] 2016 [Context Encoders] [Colorization] [Jigsaw Puzzles] 2017 [L³-Net] [Split-Brain Auto] 2018 [RotNet/Image Rotations] [DeepCluster]
作者:Sik-Ho Tsang
喜欢就关注一下吧:
点个 在看 你最好看!********** **********