
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
每个月都会有几千篇的论文在arXiv发布,我们不可能看完所有的文章,但是我们可以从中找到一些趋势:
- 大型语言模型不再与较小的模型在同一类别中竞争(如训练前+监督数据微调)。为什么?这已经没有意义了,因为每个人都知道,当更大的模型在SuperGLUE这样的监督基准上进行微调时会发生什么:它们只会变得更好。相反,我们看到这些模型正在探索一些以前不可行的问题,比如零样本/少样本和或多模态学习。
- 衡量标准和基准:我们如何量化我们关心的东西?为了使我们的进步更有意义,我们也需要不断地重新思考和创新。MNIST对于一些计算机视觉研究来说是很棒的,但你不会在这数据集上发现吹嘘新的SOTA方法。幸运的是,学者们经常关注这一点,传统上大多数揭示事实的论文都来自大学,就像我们很快就会看到的那篇。
- 我们经常讨论建模方面的事情——模型的架构、损失函数、优化器等等——因为它们很吸引人,但越来越多的证据表明,如果你想解决一个新问题,你的大脑时间最好花在数据处理上。Andres Ng多年来一直在倡导这一观点,它就像美酒一样在陈年。
下面进入到我们的推荐环节:
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
By Yucheng Zhao, Guangting Wang, Chuanxin Tang, Chong Luo, Wenjun Zeng and Zheng-Jun Zha.
这篇论文的缺点也是它的优点:为进一步优化他们的实验而付出的有限的范围和努力。当社区通过数百次迭代优化某项技术时,很难以公平的方式将其与新方法进行比较:现有方法的成功有多少可归因于其基本思想,而有多少是由于 是理所当然的小优化和专业知识的纯粹积累?他分析了过去十年在计算机视觉领域占据统治地位的 CNN 的情况,和在语言领域占主导地位的 Transformer 的情况。
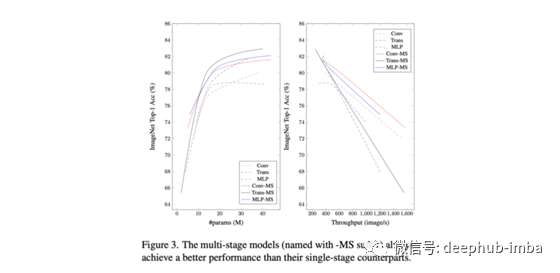
作者提出了一个相当简单的策略来正面比较这三种架构:将网络架构定义为嵌入、空间混合和下采样块的组合,并且仅在空间混合与不同架构之间进行交换。需要注意的是,所有的架构都共享一个初始patch嵌入层,这实际上是对原始图像的卷积(即每个patch共享权值的线性投影),所以所有的技术都包含一个类似卷积的第一个层。
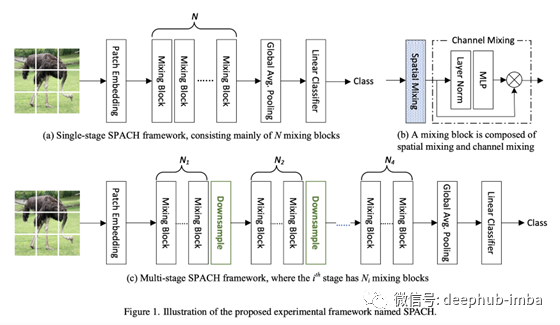
我们可以从这些实验中得出的结论是有限的:在最初的patch嵌入之后,当有足够的数据时,mlp表现得出奇地好,尽管cnn仍然在数据受限的情况下中占据统治地位,而transformer的对于规模的扩充表现得更好,因为当你不断增加数据时,它们的效果也会增加。
另一篇相关的推荐 :Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?
Shallow pooling for sparse labels
By Negar Arabzadeh, Alexandra Vtyurina, Xinyi Yan, Charles L. A. Clarke.
MS MARCO是最受欢迎的信息检索(IR)基准之一。论文呢揭示了现有基准的一些不足之处,并更广泛地提出了如何对IR进行评估的改进。
IR基准测试通常以以下方式进行:给定一个查询,语料库中的一段被标记为与该查询相关。大多数查询只有一个段落被标注为相关,尽管事实可能在语料库中有更多的段落。标注所有查询文档对在大多数情况下是不可行的,因此我们可以说标签是稀疏的。然后使用Mean Reciprocal Rank (MRR)来评估检索模型,在这个模型中,被标注为相关的文章应该排名第一,而不是“惩罚”不相关的文章(记住,尽管没有标注,它们可能实际上是相关的)。
这种设置的问题是:如果检索模型将没有标注但实际上比标注的段落更相关的段落排在首位,该怎么办?论文提出的这项工作准确地回答了这个问题。
给定MS Marco的查询子集,他们运行查询并要求标注者回答以下问题:那个段落是与查询最相关的段落,被标注为相关的段落还是来自神经排序模型的最高结果?对于标注者来说并不知道段落是来自于哪里。结果表明,来自神经排序器的结果比标注的结果更受欢迎(见下图)。
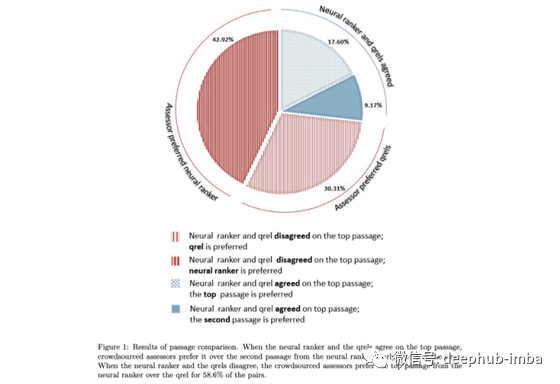
这个结果非常有趣,因为它表明流行的排行榜可能不再反映对 IR 的任何改进,而是对标注的过度拟合。作为解决此问题的建议,作者建议转移到非静态注释数据集,其中最相关的段落用成对标签连续注释(例如,两个段落中的哪一个与给定的查询最相关?)。
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
By Ofir Press, Noah A. Smith, Mike Lewis.
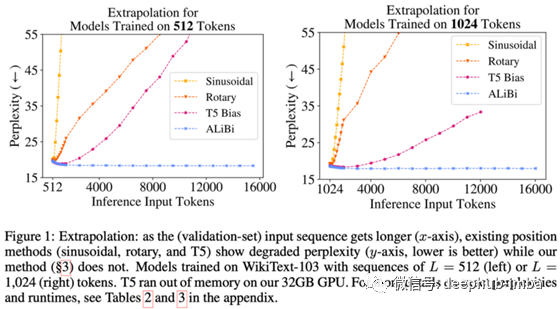
Transformer 是原生的 set-to-set 神经网络,这意味着架构是顺序不变的,这就是研究人员尝试将位置信息编码到模型中的不同方法的原因。本文提出了一种新的超级简单、无需学习的编码相对位置信息的方法,该方法对于在更大的上下文中进行推理比在训练中更有效。这会成为一个新的标准吗?
长期以来,Transformers 中的位置编码随处可见,因为它似乎“随心所欲”:给定一种编码位置的方法,transformer 和梯度下降会找到一种方法来解决它并表现良好。我们甚至需要一个调查表来了解它![2] 但是,正弦位置嵌入或固定学习绝对嵌入等常用技术的隐藏陷阱是什么?当进行比训练时更长的推理时,他们不能很好地泛化。
此处提出的方法仅依赖于向注意力矩阵(在 softmax 之前)添加一个偏差,该偏差与中心标记与其邻居之间的距离成正比(见图 B)。这些偏差是固定的而不是学习的,并且缩放因子 m 被设置为一个超参数。

令人惊讶的是,Transformer可以很好地学习这种位置编码,并与类似大小的等效模型相比执行起来具有竞争力。有趣的比较发生在模型使用比训练时更长的序列进行推理时(见下图)。虽然现有的模型难以推广(即随着序列的加长,困惑程度急剧增加),但在ALiBi并不受到影响。
但是还有一个重要的警告没有在论文中彻底解决:注意力矩阵中的偏差通过一个 softmax 来抑制远标记的贡献,这就像有一个注意力的“软窗口”。实际上,这意味着在位置偏差足够负的某个点,该标记将永远不会做出有意义的贡献,无论推理时的输入长度如何,都使得有效上下文始终具有有限的大小。
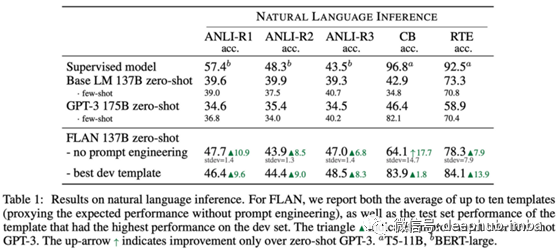
Finetuned Language Models Are Zero-Shot Learners
By Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu et al.
尽管取得了很大的进步,但NLP中的提示预测仍然不是很健壮:在不应该出现的地方添加逗号,输出可能会完全改变。本文展示了如何在自回归语言建模前训练中加入标记数据,使模型在零次学习的配置下更见状地学习和更好地迁移到新任务。
零样本学习是机器学习中最有前途的发展领域之一。我们的梦想很明确:找到一个模型,并让它在第0天就在您的领域中工作,而不需要数据收集、标记、训练、维护、监控漂移等。
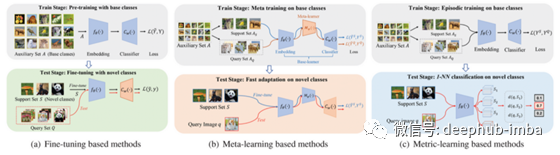
大型自监督语言模型目前是最终实现这一梦想的主要候选者(尽管还有许多障碍需要克服)。特别是自从GPT-3(推出一年多了!)以来,输入提示已经成为一项关键技术,并且一直存在。本文研究了如何将大型语言模型训练成更健壮、更准确的零样本自然语言提示,就像GPT-3所做的那样。然而,将其与GPT-3进行正面比较是不公平的:该模型在训练前包含了标记数据,但他们没有直接对其进行优化,而是使用模板创建该任务的自然语言表达(见下图);而GPT-3不包括任何训练数据——实际上会一些数据集意外泄露到训练前数据中,将其暴露给训练前[3]中的模型。
结果是模型在许多任务中表现得比GPT-3更好,并显示出了良好的泛化任务,尽管它仍远不是一个完全监督的模型。
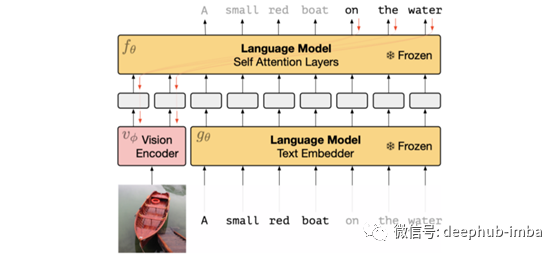
Multimodal Few-Shot Learning with Frozen Language Models
By Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals and Felix Hill.
多模态和异步:你能利用预先训练过的语言模型中的信息来完成视觉任务而不需要再训练它吗?
本文提出的思想相当简单:训练一个语言模型,使其参数保持不变,然后训练一个图像编码器将图像编码成提示语句,以便该语言模型执行特定的任务。我喜欢将其概念化为“学习一个图像条件提示(通过神经网络图像),以便模型执行任务”。
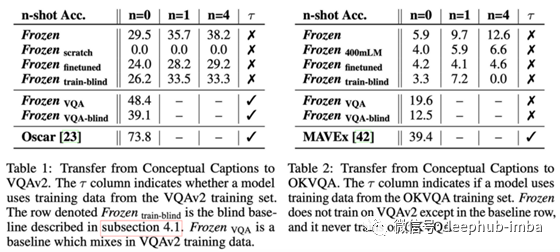
这是一个很有前途的研究方向,但就绝对性能而言,结果还不是很令人印象深刻。比较使用多模态数据进行完全微调的模型(Frozen finetuned)和保持语言模型不变的模型(Frozen VQA-blind)是很有趣的:只有后者从训练数据集(Conceptual caption[4])到目标评估数据集(VQAv2[5])表现出良好的泛化,但其仍然远不是一个完全监督的模型。
其他关于Transformers 和自监督学习的工作
On the Opportunities and Risks of Foundation Models(Rishi Bommasani)、Percy Liang等人在8月发布时引起了相当大的轰动。这本纸质书包含了很多内容:概述、介绍和论文,内容涉及在大量数据的监督下训练的大型神经模型的新兴领域,为此,它们被称为基础模型。虽然这是一个引人注目和全面的概述——涵盖了这些模型的技术和社会影响——但似乎不清楚它们是否需要一个新的命名法。
Primer: search for Efficient Transformer for Language Modeling,作者是David R. So等人,他们提出了一种方法来搜索性能良好、效率最高的Transformer架构,与普通架构相比,可以实现大约2倍的加速。与标准的Transformer相比,结果发现架构有两个主要的修改:平方ReLU激活和在自注意中的每个Q、K和V投影后添加一个深度卷积层。
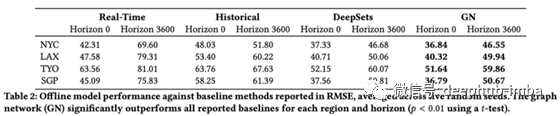
ETA Prediction with Graph Neural Networks in Google Maps
By Austin Derrow-Pinion, Jennifer She, David Wong, Petar Veličković et al.
当谷歌Maps计算出你从A点到B点需要多少时间时,你想知道幕后发生了什么吗?
同样,您最需要的是大规模的高质量数据。本文描述了完全使用神经网络估计某事物从 A 点到 B 点所需时间的问题。
收集一个巨大的数据集(google map)。将道路和路径的地图表示为带有分段和交叉点的图。应用一个图神经网络(GNN)来学习每个节点的嵌入+使用那些做推断,训练与监督数据连同一些辅助损失正则化训练。GNN由边、节点和全局超段表示(嵌入)组成,这些超段表示通过聚合函数(神经网络)进行组合,将之前的表示作为输入,并输出可用于预测的新表示。例如,在给定之前的节点、边缘和超段表示的情况下,边缘表示将用于估计每个段所经过的时间。
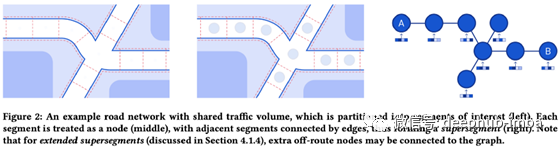
与谷歌地图现有基线的相比收益是巨大的,悉尼等城市的 ETA 准确度提高了 40%。本文的另一个有趣方面是详细介绍了如何在满足延迟需求的同时部署这样的模型,这涉及对多个超分段的预计算和缓存预测。
Eyes Tell All: Irregular Pupil Shapes Reveal GAN-generated Faces
By Hui Guo, Shu Hu, Xin Wang, Ming-Ching Chang and Siwei Lyu.
这个很有趣。Deepfakes 的挑战是普通人眼无法区别计算机生成的内容和原始内容,所以我们需要是能够在必要时有效地检测到它,以防止错误信息的传播。事实证明,瞳孔是人脸的一个非常能揭示真相的方面!
仔细观察一张脸的瞳孔:人类的瞳孔碰巧一直都很圆,但生成对抗网络(GAN)生成的脸并没有很好地捕捉到这一特征。结果是,GAN生成的面孔通常会显示出稍微不规则的瞳孔,这使得通过观察它们可以检测出人工生成的图像。

通过分割瞳孔并将其拟合成椭圆形状,这项工作显示出惊人的良好的ROC曲线用于检测假人脸图像。

还有一篇比较相似的论文 Dodging Attack Using Carefully Crafted Natural Makeup by Nitzan Guetta et al.
Code and popular implementations
LibFewShot 是一个用于少样本学习的综合库。这个新库可以帮助你入门。
SwinIR
By Jingyun Liang et al.
SwinIR 是一种使用 Swin Transformer 进行图像恢复的方法,Swin Transformer 是微软 [1] 几个月前提出的计算机视觉 (CV) 模型主干。他们的方法在三个基准测试中达到了 SOTA。

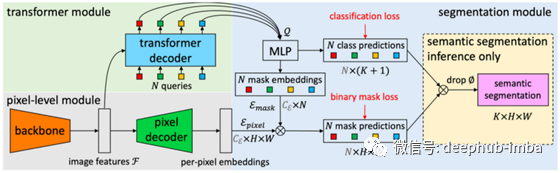
MaskFormer
By Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
现代语义分割通常被构建为每像素分类任务(即为属于汽车、道路或鸟类的每个像素分配一个类),然后执行实例级分割(即找到在每张图片的掩码)会被建模为一个二元掩码分类任务。MaskFormer 建议直接学习一组二元掩码(就像在实例级分割中一样),然后是每个掩码的分类步骤,在不显式逐像素分类的情况下显示很好的结果。
引用
[1] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. By*Ze Liu,Yutong Lin,Yue Cao,Han Hu,Yixuan Wei,Zheng Zhang,Stephen Lin,Baining Guo; 2021*
[2] Position Information in Transformers: An Overview. By Philipp Dufter, Martin Schmitt, Hinrich Schütze; 2021.
[3] Language Models are Few-Shot Learners. By OpenAI et al.; 2020.
[4] Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts. By*Soravit Changpinyo,Piyush Sharma,Nan Ding,Radu Soricut; 2021.*
[5] Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. By*Yash Goyal,Tejas Khot,Douglas Summers-Stay,Dhruv Batra,Devi Parikh; 2016.*
喜欢就关注一下吧:
点个 在看 你最好看!********** **********