
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
Keenious 是一个专为学生、研究人员设计的搜索引擎!并且提供了应用程序直接在文本编辑器中运行;可以帮助我们分析整个文档并工作时找到高度相关的结果
介绍
与传统搜索不同,我们的Keenious 学术搜索引擎在直接相关的结果(关键字等)与通过语义与输入文档相关的相似性结果之间取得平衡。相似性的结果促进了对研究和主题的持续发现和探索,这两者对各级研究人员和学生都至关重要。
找到正确的平衡很困难因为用户意图本身就是不确定的,所以很难找一种行之有效的方法来寻找最佳平衡方案。我们使用自己的理解、反复试验以及最重要的用户反馈来找到最佳组合。
最近,我们一直在探索引入一种无需基于文本的语义向量即可执行的语义搜索的方法。这样做的原因是用户无需搜索文档就可以对研究和主题进行深入探索和发现。我们通常将此称为冷启动问题,即用户没有论文或文档文本可供搜索的情况。
能够开发出一种解决方案一直是我们关注的焦点,该解决方案允许用户无需文档或搜索查询,只通过单一提示或输入(他们喜欢的论文、主题等)轻松发现个性化的研究建议。我们目前找到的解决方案是使用知识图谱(KG)结合快速向量搜索解决方案(Weaviate)。
在本文中,我们将简要介绍知识图谱,以及我们在Keenious如何利用它们,同时主要关注如何使用Weaviate缩放图并使其嵌入到搜索引擎中。这里主要包括Weaviate的概述,以及Weaviate为什么作为此任务的正确工具。
Keenious的快速介绍
在我们开始之前,你可能不熟悉 Keenious 及其功能。Keenious 是一种工具,可以分析你的写作,并在几秒钟内向你展示数百万在线出版物中最相关的研究。
我们相信学习不是一个静态的过程因此研究也不应该是,使用 Keenious每一个文档都可以变为搜索查询。我们的插件会在撰写文本的同时分析的文本并在每一步为你找到最相关的研究。Keenious 通过筛选跨学科主题和研究领域来发掘隐藏的宝藏。
如果需要搜索更具体的内容,可以使用搜索单独浏览论文或文档中的每个句子。这将缩小搜索范围,同时保持它与文档的其余部分相关。
学术知识图谱
知识图谱 (KG) 是一个很深的主题,这里我们就不详细的介绍,有兴趣的朋友可以查看以前我们公众号 deephub-imba 发布的文章。我们这整理了一些知识图谱的要点,供你理解本文后面的内容
- 知识图谱又名语义网络:它们是一种连接多个现实世界实体和概念的网络,并区分它们相互关联的不同方式。几乎任何概念/实体/系统都可以抽象为知识图谱。
- 更正式的 KG 是异构图,其中可以存在多种类型的节点和/或边。例如,movielens 数据集可以抽象为由多种类型的节点组成的 KG,例如电影、演员、流派、语言和指定两个实体之间关系的边,即演员 → 出演 → 电影。
- 它们与所有节点和边都属于同一类型的同构图形成直接对比,例如,朋友(社交)网络。
- 我们的知识图谱的主要实体(节点)和关系(边)是论文引用以及丰富图谱的其他论文特定元数据。
- 使用这些节点和边缘关系,我们能够创建学术知识图并训练自定义模型以生成非常丰富的图嵌入,其中每个嵌入代表一种独特的节点类型,包括我们数据集中的论文。这些嵌入构成了此搜索的基础,也是我们提供给 Weaviate 的内容,以使我们的 KG 中的每个独特实体都可被发现。
Weaviate矢量搜索引擎

Weaviate 是一个矢量搜索引擎,帮助推动人工智能搜索和发现。矢量搜索现在正处于一个重要且非常有趣的交汇处,它正在成熟并且成为搜索技术的主流,因为它好处是不可否认的。
就像倒排索引如何改变我们进行全文搜索的方式一样,像 Weaviate 这样的矢量搜索引擎正在推动下一代对文本、图像和知识图谱中的非结构化数据的搜索。
数据对象和混合索引搜索
从根本上说,Weaviate的架构从一开始就经过了深度的思考。Weaviate中的数据对象基于一个类属性结构,这使得 Weaviate 中的所有对象都可以轻松地使用 GraphQL 进行本机查询,并且对使用了复杂的过滤器和标量值进行查询进行了优化。其实,传统的倒排索引和矢量索引的结合才是Weaviate真正脱颖而出的原因。在同一个查询中,用户可以选择从向量搜索中包含或排除具有特定标量值(文本、数字等)的数据对象。
即插即用设计
Weaviate另一个有趣的设计方面是它的API是高度模块化的。矢量索引 API 的结构也是作为一个插件系统进行工作,这样可以使得Weaviate 以适应矢量搜索的并进行持续改进。
Weaviate 当前的向量索引类型是 HNSW,这是一种最先进的近似最近邻 (ANN) 向量搜索算法。ANN 搜索是一个非常活跃的研究领域,并且一直在提出新的可以提高召回率和效率的新索引架构。因为 Weaviate 的矢量索引 API 与后端无关,这意味着将来当最新和最好的 ANN 索引添加到 Weaviate 的可用插件时,用户可能能够在对其设置进行最小更改的情况下进行切换(有可能根本不需要改动)。
我认为选择花时间设计一个可以适应未来任何向量索引的API是一个非常好的选择。太多的文本搜索引擎使用20多年前的检索方法,这种检索方法早就被超越了,但因为代码耦合太紧密,无法被取代。
模块和集成
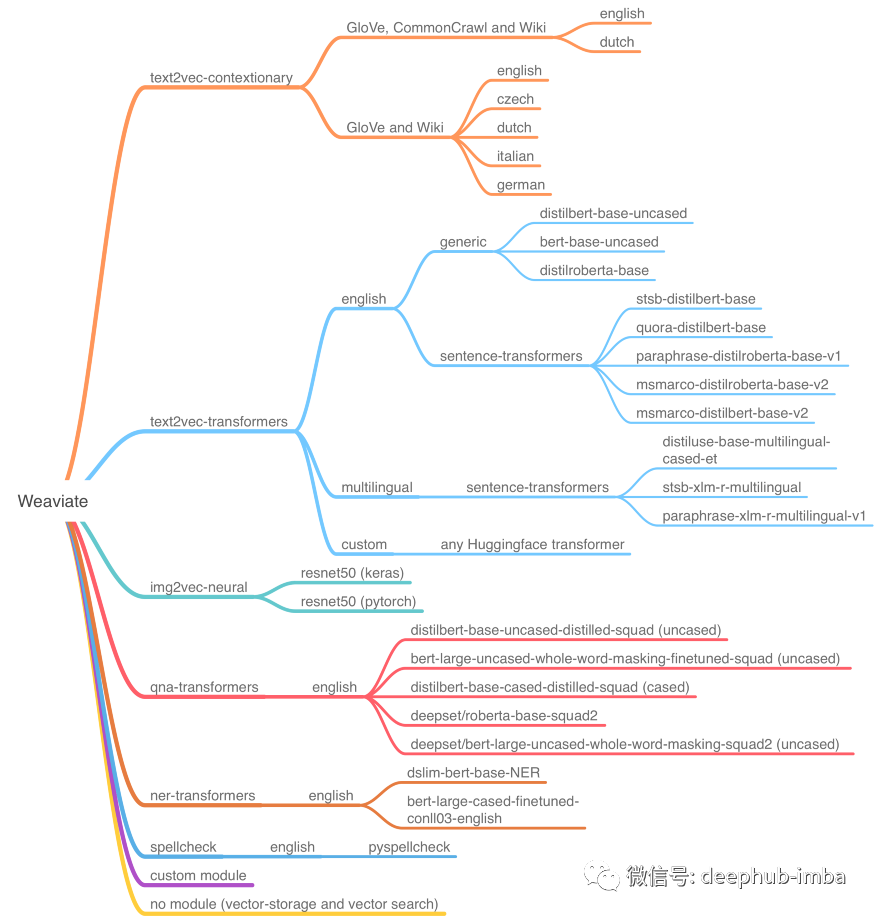
Weaviate 除了采取的整体模块化方法之外还建立在搜索之上的功能模块,以及许多定制的向矢量转换数据的矢量化模块。Weaviate 内置一些非常强大的模块,在使用过程中涉及几个常规转换步骤,可以通过创建自己任务流进行拼接。以下是我整理的一些常用模块:
text2vec-contextionary:一个非常有趣的功能,它本质上将数据对象和对象的上下文进行向量化表示并保存到数据库中。
text2vec-transformers:利用sentence-transformers中丰富的嵌入模型为每个导入Weaviate的文本对象创建一个段落/文档嵌入,这样开发人员就不必自己实现推理代码。
img2vec-neural:与 text2vec 类似,该模块使用大型预训练计算机视觉模型自动将图像矢量化,以无缝启用对任何图像的语义搜索。
横向扩展
注意:在编写本文的时候,Weaviate加入了横向扩展特性的候选版本v.1.8.0-rc0刚刚发布。预计到2021年秋季,它将稳定发布。
虽然我们的用例目前能够适用于Weaviate的单个节点实例,但最终我们还是需要一个可以无限扩展的向量搜索解决方案。在矢量搜索的世界里这是很麻烦的事情。一旦向量到达了一定的数量级许多向量搜索算法的性能都会有一个上限。Weaviate的设计时也考虑了作为节点集群进行水平扩展,很像Elasticsearch目前用于文本搜索的功能。Weaviate的可扩展版本由一个索引组成,该索引被分解成许多不同的分片或小型ANN索引,然后可以分布在多个节点上。
通过这种设置,可以向Weaviate集群添加对象的数量实际上没有限制,因为它可以扩展到任何用例而不会牺牲性能。
横向可扩展是矢量搜索引擎真正投入生产所需的最关键特性。Weaviate目前在可伸缩性方面处于有利地位。整个代码库,包括HNSW的自定义实现,都是用Go语言编写的,因为Go非常适合大型可伸缩系统。
使用 Weaviate 为知识图谱提供搜索支持
对于考虑使用 Weaviate 的任何人来说,需要注意的是它对内存要求很高,但是具体取决于需要的“模式”。如果针对索引添加新对象,即大量写入,那么内存消耗会非常大。为了解决这个问题可以在大量的插入之后重新启动 Weaviate 这样可以仅使用一小部分内存,因为插入后的向量不需要存储在内存中。
下面让我们来讨论一下 Keenious 如何实际使用 Weaviate 来支持我们即将推出的知识图谱搜索功能。
虽然 Weaviate 具有前面提到的许多功能模块,但其核心是纯矢量原生数据库和搜索引擎。由于我们已经训练自定义模型来为我们的项目生成丰富的嵌入向量,因此我们只需要所有的向量都直接导入到 Weaviate 中,无需任何转换。在单节点版本中我们目前已经索引了超过6000万的文档。
目前,我们在自己的自定义工作站上构建索引和数据库,Keenious 的每个人都亲切地称其为Goku。下一步我们会将其迁移到 Kubernetes 上工作。Weaviate 有一个非常有用的工具,可以快速创建一个基本的 docker-compose 文件来使事情顺利进行
Weaviate 有许多不同的客户端可供选择,具体取决于您熟悉的语言。Python、Go、Java、Javascript 和 CLI 客户端,都已经是非常成熟的产品了。
优化 Weaviate 的一些技巧
目前,向量索引有 4 个主要参数,可以在某种意义上进行调整。这些参数是:
- efConstruction
- maxConnections
- ef
- vectorCacheMaxObjects
前 3 个参数直接来自 HNSW 本身并且特定于算法,因此可以查看原始论文以获取对每个参数作用的更详细说明。这些参数的主要影响,特别是 efConstruction 和 maxConnections 是召回率/精度和资源使用/导入时间之间的权衡。
增加 maxConnections 通常会提高索引的质量,但也会增加内存中 HNSW 图的大小。如果您无法承受增加的内存使用量,那么 efConstruction 可能是您想要增加的参数,但增加此参数会增加导入时间。
ef 参数实际上只在进行搜索时起作用,并且取决于索引中的对象数量和相应时间的要求。我们发现,在索引时使用较高的 efConstruction 值时,我们可以在搜索时提供较低的 ef 值。
请小心使用 vectorCacheMaxObjects,几乎肯定希望它大于或等于索引时数据集中的对象数,但是当运行 Weaviate 仅用于搜索时,将内存保持在较低水平可能是有益的,因为不这样做'不需要将所有向量存储在内存中,HNSW 图做了繁重的工作,向量仅用于计算最终的距离分数。
总结
在 Keenious,我们对 Weaviate 的矢量搜索质量和构建在其上的所有附加功能感到非常满意,这些附加功能真正改变了矢量搜索的游戏规则。
选择 Weaviate 使我们能够完全专注于为我们的搜索引擎开发出色的功能,这些功能涉及我们存储在 Weaviate 中的 60 多万个知识图谱嵌入。我们能够用最前沿的产品来解决学术搜索问题,而不是技术实现要求,这太棒了。
我们很快(2021 年秋末)在此基础上提供了一些非常有趣的功能,我们期待在发布后与您分享这些功能,敬请期待。
作者:Charles Pierse
喜欢就关注一下吧:
点个 在看 你最好看!********** **********