
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
**
**
意图识别是NLP中对话系统的一项基本任务。意图识别(有时也称为意图检测)是使用标签对每个用户话语进行分类的任务,标签来自一组预定义的标签。
分类器对标记数据进行训练并学会区分对话属于哪个类别。如果一个看起来不像任何训练对话输入到分类器,有时结果可能会非常尴尬。所以我们需要对域外话语进行分类(类别外)。
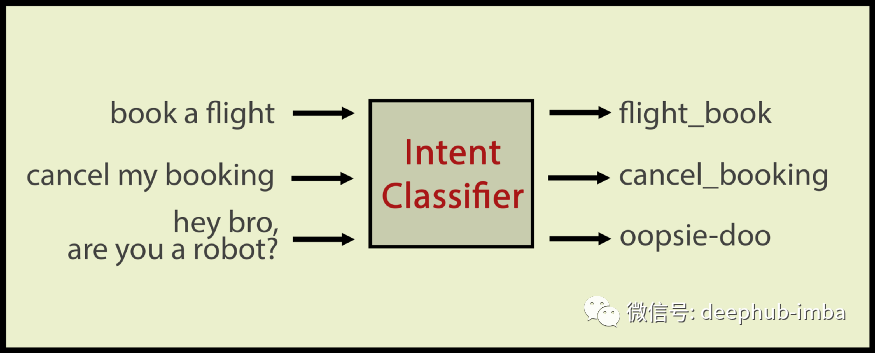
意图分类器对话语进行分类。在这里,示例域是机票预订和话语“嘿,兄弟,你是机器人吗?”是一个不在服务领域内表达。
问题是,用户和我们开发人员生活在不同的语言中。开发人员希望用户在语义丛林中的安全农场(也就是所谓的专属领域),但用户并不是很清楚分类器或聊天机器人NLU是如何工作的(他们也不需要)。我们不可能期望用户停留在正确的语义领域,并且我们应该为聊天机器人提供处理良好话语的技能。
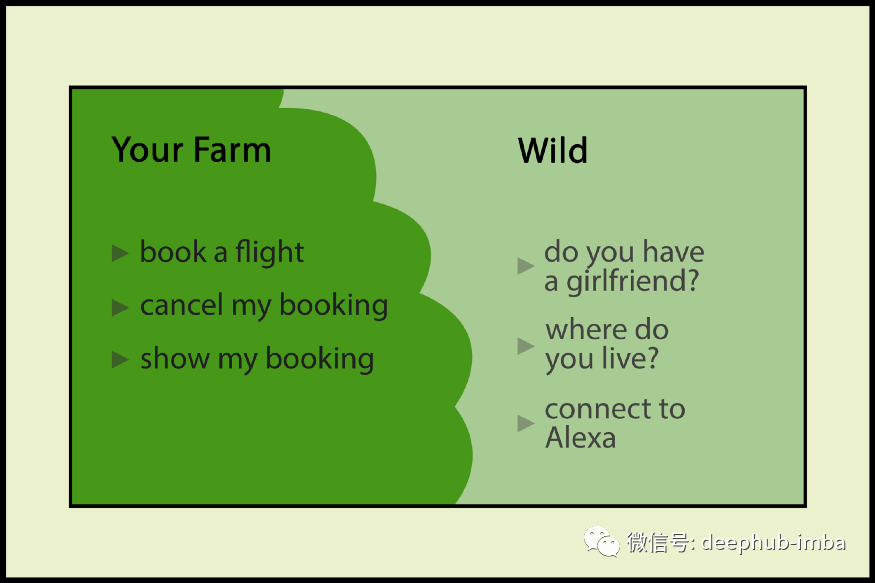
在这篇文章中,我们将讨论如何通过检测哪些话语属于域哪些话语不属于域,来保持我们的域的完整性,Chris是我们的司机语音助手。首先,我将介绍Chris所服务的领域和话语,然后我们将讨论用孪生网络(Siamese Networks)和零样本(Zero-Shot )学习进行文本分类。
Chris 的服务的领域和使用的数据
Chris是司机的语音助手。我们的Chris是一个司机助手,由德国Autolabs制造。Chris可以发送/阅读短信,WhatsApp消息,打电话给电话联系人,播放音乐,导航,回答天气查询,并进行一点聊天。
以下是典型的用户话语:
play music
some music please
stop the music
send a message
send a message to Tess
send a whatsapp
read my messages
do I have any new messages
display the latest message
start the navigation
show navigation
show the map
stop the navigation
nearest gas station
find a parking spot
read it
no cancel
cancel
yes
next
no next
tell me the time
how is the weather today
意图名称由子域名称名和动作名称组成。以下是与上述话语对应的一些意图和操作:
music.play
music.pause
messages.write
messages.read
navigation.start
navigation.stop
universals.accept
universals.reject
universals.next
misc.time
misc.weather
但是,当用户询问了一些域外言论怎么办?这里还有一些例子:
hey siri
launch siri
wake up siri
open my instagram
share my video on instagram
delete my facebook account
play my audibooks
set an alarm
show alarms
please delete all alarms
open the doors
聊天机器人肯定不能包含用户要求的所有功能。例如,打开车门根本不是 Chris 的技能。尽管 UX 团队在每个包装中都包含有关 Chris 技能的指南,但用户肯定不会阅读(谁会去看说明书呢)并向测试一下Chris 都能干什么。
简短的话语可能看起来“容易”但也会有很多的问题。例如语音识别错误尤其是在短话语中,因为话语中可能会缺少语义上的关键词(例如“播放音乐”中的“播放”)。此外,语音识别引擎必须在正确的时间开始收听,否则它可能会漏掉一个单词,诸如“是”、“否”之类的简短话语,这对于解决上下文至关重要。如果您的机器人多次要求用户确认,那么它可能会给用户带来糟糕的使用感受。
什么是零样本文本分类?
零样本短文本分类是在一组类标签上训练分类器,并用训练集中没有看到的类标签测试分类器的任务。NLP 最近的工作集中在更广泛环境中的零样本学习,零样本学习 NLP 现在意味着训练一个模型来完成它没有明确训练的任务。例如GPT-3 就是一个零样本学习器。
在零样本分类中,我们用一些线索或类名向分类器描述一个未出现的分类。对于零样本文本分类,通常使用意图名称来描述意图的语义。当我第一次开始做 Chris NLU 时,数据是用于“常规”意图分类的。然后我开始尝试 ood 并发现我们的 domain.action 类命名方案(music.play、navigation.start 等)确实非常适合零样本学习。
将标签和话语嵌入同一空间
零样本文本分类的一种常见方法是将意图名称和话语嵌入到同一空间中。通过这种方式,零样本算法可以通过语义组学习意图名称和话语之间的语义关系。这根本不是一个新想法,研究人员使用词向量来表示固定维度的文本和意图名称(例如在 Veeranna 。2016中)。由于 Transformers 的发明连续向量的表示法经历了一场革命,现在我们有了更多高质量的句子和单词嵌入。
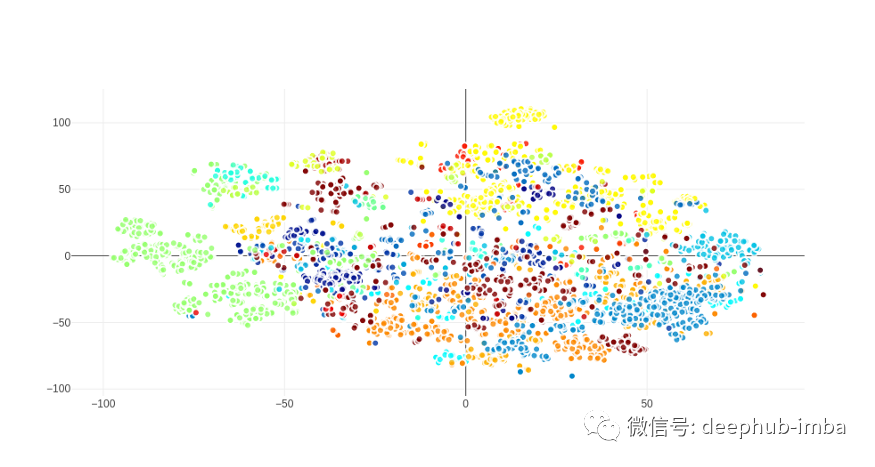
在我们的研究中,首先使用平均池化向量来表示话语,然后使用 BERT 对我们的话语进行编码以生成话语向量。让我们看看当我们使用词向量时,意图名称是如何与话语结合在一起的。我们使用了 100 维Glove向量。通过对一个句子的词向量求平均值来生成嵌入。为了获得标签的嵌入(例如 music.play),我们平均了域(音乐)和动作(播放)的嵌入。为所有话语生成嵌入后我们使用 t-SNE 将我们的数据集转换为二维(用于可视化)。下面的散点图显示了所有数据集的话语和意图名称,具有相同意图的话语用相同的颜色着色:
这是话语和意图名称如何对齐的:
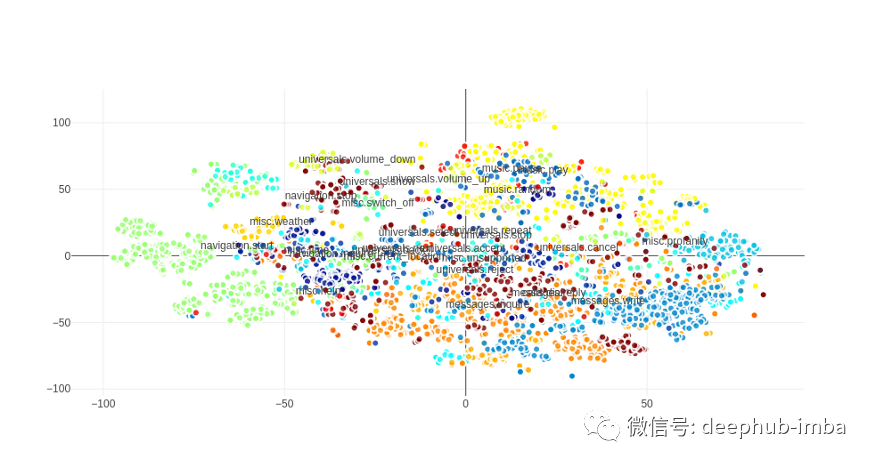
如果我们放大一点,我们会看到意图名称和相应的话语确实非常一致:
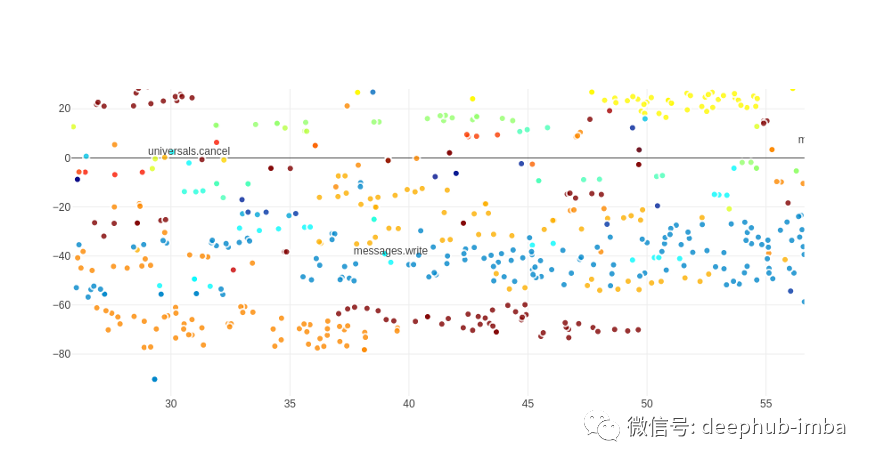
数据集话语创建了一个相当漂亮的散点图,没有很多异常值和相同意图的话语与意图名称组合在一起。
为什么没有使用BERT嵌入话语和意图名称呢?这对话语很有效,但意图名称不是真正的句子和简短的表达。BERT是为完整的句子而训练的而对于简短的表达比如我们的意图名称可能不太管用。在这种情况下,我们可以通过BERT为话语创建768维嵌入,然后通过Glove 单词向量为意图名称创建100维嵌入。为了将它们嵌入到相同的空间中,我们需要计算一个投影矩阵ϕ,它将768的话语向量投射到100维意图向量上。因为我们已经标注了数据,所以我们可以通过回归来学习投影矩阵。(包含正则化以防止过度拟合是很重要的)。然后我们也可以得到一个类似于上面的视觉对齐。
用于零样本文本分类的孪生网络
上面的EDA向我们展示了意图名称和话语之间的语义相似性是非常明显和可学习的。然后我们可以让 Siamese NN 学习意图名称和话语之间的相似性。
传统的意图分类器输入话语并生成类标签。通常我们使用 LSTM 或 BERT 对话语进行编码,然后将编码后的话语输入 Dense 层并获得类标签:
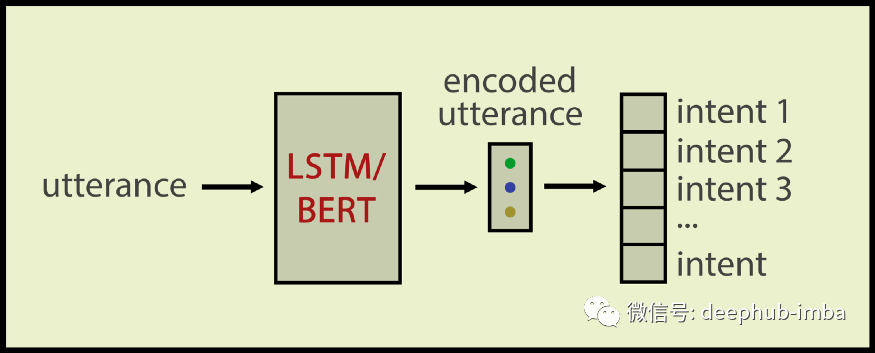
我们的零样本意图分类器会学习标签和话语在语义上是否相似。在这里我们使用了 孪生网络架构,它非常适合计算语义相似度。我们的 孪生网络输入一个意图名称和一个话语;输出是与输入相关或不相关。
该架构包括
- 一个 LSTM/BERT 层来编码话语和标签
- 然后是一个距离层来计算话语和标签之间的语义距离
- 最后一个密集层将距离向量压缩为二进制值
这个架构仍然是一个文本分类器,但这次输入的数量是2,输出向量的维数只有1。输出是二进制的,0表示标签和话语无关;1 表示话语属于该标签的类别。
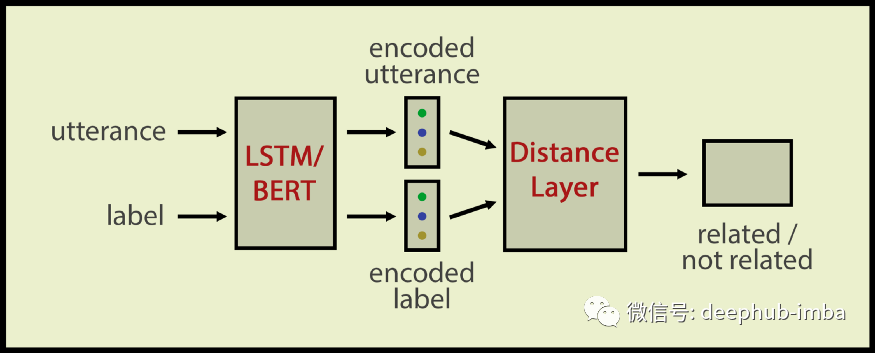
我们可以向孪生分类器询问我们想要的任何标签(即使分类器以前从未见过这个标签),只要我们能为标签提供良好的嵌入。这对于域外话语非常有用,因为即使您没有任何用于 ood 类的标记数据或只有几个示例,使用孪生网络的零样本分类器仍然可以确定话语是否与 Chris 域相关。
孪生网络在很长一段时间内用于语义相似性,但使用一些技巧可以让我们轻松实现零样本意图预测模型。有时这个想法一直在你面前,但你必须从不同的角度来看待它。
总结
在本文中,我们使用了一种全新的方法来解决意图分类的“传统”问题。首先,我们对 Chris 话语进行了语义分组。然后,我们更新了我们对孪生网络的了解。最后我们看到了如何使用孪生网络进行零样本分类。
引用
- Language Models are Few-Shot Learners, https://arxiv.org/abs/2005.14165
- Are Pretrained Transformers Robust in Intent Classification?A Missing Ingredient in Evaluation of Out-of-Scope Intent Detection https://arxiv.org/pdf/2106.04564.pdf
- Detecting Out-Of-Domain Utterances Addressed to a Virtual Personal Assistant https://www.microsoft.com/en-us/research/wp-content/uploads/2014/09/IS14-Orphan2.pdf
- Using Semantic Similarity for Multi-Label Zero-ShotClassification of Text Documents , https://www.esann.org/sites/default/files/proceedings/legacy/es2016-174.pdf
作者:Duygu ALTINOK
喜欢就关注一下吧:
点个 在看 你最好看!********** **********