
混合模型ACmix将自注意与卷积的整合,同时具有自注意和卷积的优点。这是清华大学、华为和北京人工智能研究院共同发布在2022年CVPR中的论文
卷积分解与自注意力
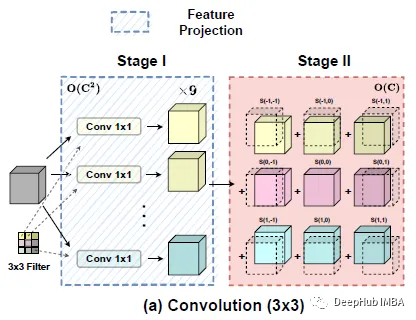
卷积分解
标准卷积:
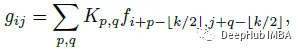
重写为来自不同内核位置的特征映射的总和:
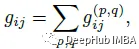
这里的:

为了进一步简化公式,使用Shift操作的定义:
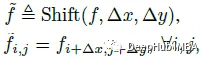
g(p,q)ij可以改写为:
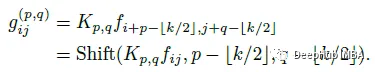
由上得出,标准卷积可以概括为两个阶段:
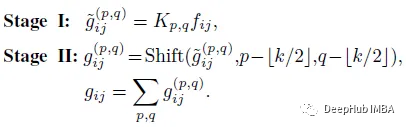
在第一阶段,输入特征从某个位置(p, q)核权重进行线性投影。这与标准的1×1卷积相同。
在第二阶段,投影特征图根据内核位置移动并最终聚合在一起。
自注意力分解
考虑一个有N个头的标准自注意模块。注意力模块的输出为:
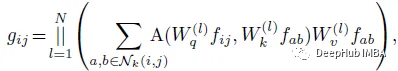
其中||是N个注意头输出的级联。注意力权重计算为:
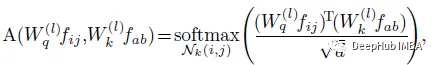
多头自注意可以分解为两个阶段,重新表述为:
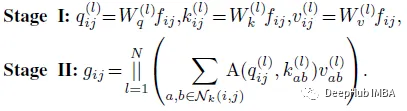
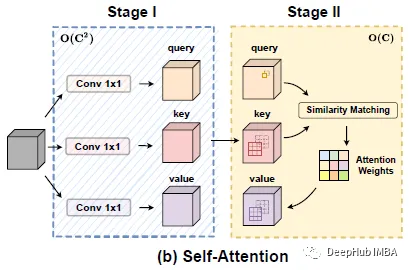
在第一阶段,首先执行1×1卷积,将输入特征投影为查询、键和值。
在第二阶段,注意力权重的计算和值矩阵的聚合,即局部特征的聚集。
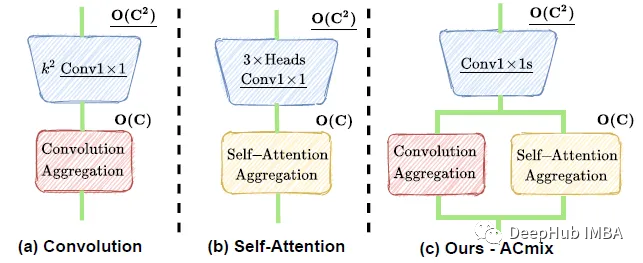
ACmix
自注意力与卷积的整合
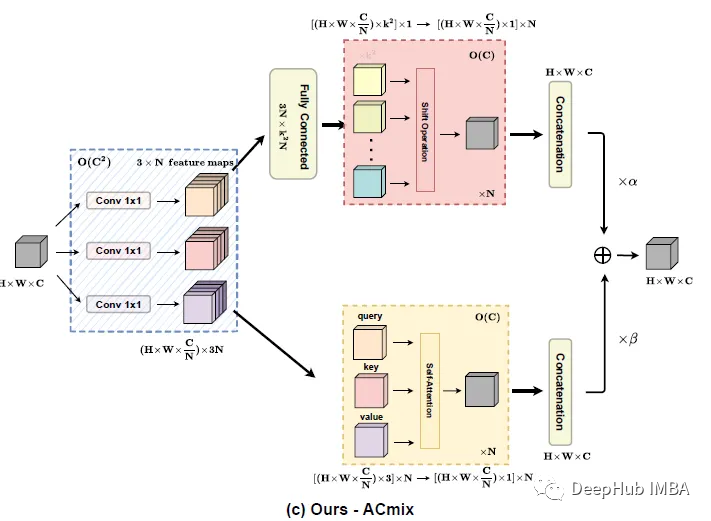
ACmix包括两个阶段:
在第一阶段,输入特征通过三个1×1卷积进行投影,并分别重塑为N块,得到3×N特征映射的中间特征集。
在第二阶段,有自注意力路径和卷积两个路径。对于自注意路径,对应的三个特征映射作为查询、键和值,遵循传统的多头自注意模块。
对于核大小为k的卷积路径,采用轻型全连接层并生成 k² 特征图,同时进行移位操作和聚合。
最后,将两条路径的输出加在一起,强度由两个可学习标量控制:
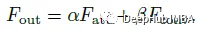
改进的移位和求和
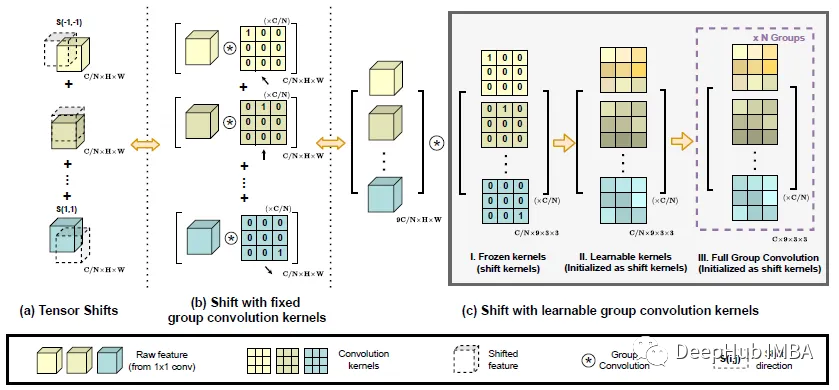
shift 移位操作的改进。(a) 使用张量移位的简单实现。(b) 使用精心设计的组卷积核快速实现。(c) 进一步适应可学习内核和多个卷积组。
尽管理论上是轻量级的,但将张量向各个方向移动实际上会破坏数据局部性并且难以实现矢量化实现。所以用固定核的深度卷积作为位移。以Shift(f,−1,−1)为例,移位特征计算为:
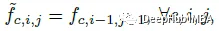
一个固定的内核可以用于移位操作:
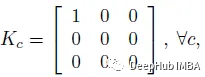
相应的输出可以表述为:
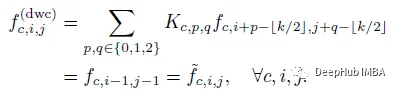
通过精心设计特定移位方向的核权重,卷积输出就等价于简单张量移位。这样的修改使该模块具有更高的计算效率。在此基础上,还引入了一些适应性,增强模块的灵活性。卷积核作为可学习的权重释放,移位核作为初始化。这提高了模型的容量。
ACmix的计算成本
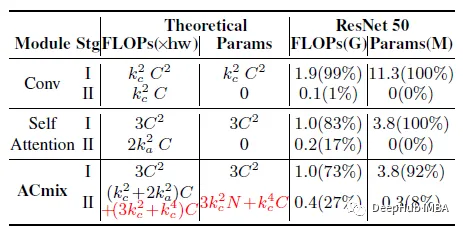
阶段1的计算成本和训练参数与自注意相同,比传统卷积更轻。阶段2ACmix引入了一个轻量级全连接层和组卷积的额外计算开销。计算复杂度与通道大小C呈线性关系,与阶段I相比相对较小。
推广到其他注意力模式
ACmix是独立于自注意公式的,所以可以很容易地采用在不同的变体上。具体来说,注意权重可以总结为
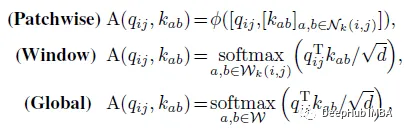
结果
ImageNet
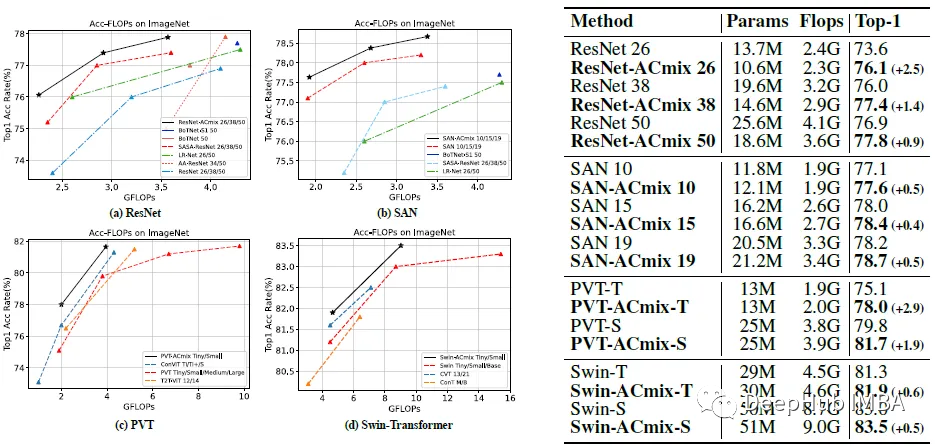
对于ResNet-ACmix模型,所提出的模型优于具有近似FLOPs或参数的所有基线。对于SAN-ACmix、PVT-ACmix和Swin-ACmix,所提出的模型取得了一致的改进。
ADE20K
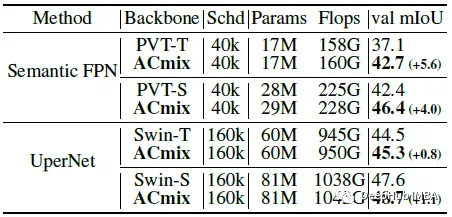
在ImageNet-1K上进行预训练,ACmix在所有设置下都实现了改进。
COCO

左、中:ACmix始终优于具有相似参数或FLOPs的基线。右:与PVT-S相比,模型在mAP可比较的情况下达到1.3× fps。当涉及到更大的模型时,优势更加明显。
消融实验

左:卷积和自注意模块的组合始终优于单路径模型。使用可学习参数也为ACmix带来了更高的灵活性。
中:通过用分组卷积代替张量位移,推理速度大大提高。使用可学习的卷积核和精心设计的初始化增强了模型的灵活性,并有助于最终的性能。
右:α和β实际上反映了模型在不同深度对卷积或自我注意的偏向。在Transformer模型的早期阶段,卷积可以作为很好的特征提取器。在网络的中间阶段,模型倾向于利用两种路径的混合,并越来越倾向于卷积。在最后一个阶段,自注意表现出优于卷积。
论文地址:
[2022 CVPR] ACMixOn the Integration of Self-Attention and Convolution
作者:Sik-Ho Tsang