
本文将演示 3 个处理时间序列数据最常用的 pandas 操作
首先我们要导入需要的库:
importpandasaspd
importnumpyasnp
importmatplotlib.pyplotasplt
本文使用的数据集非常简单。它只有 1 列,名为 VPact (mbar),表示气候中的气压。该数据集的索引是日期时间类型:
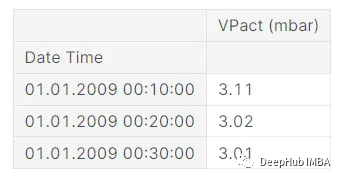
我们也可以应用 pd.to_datetime(df.index) 来制作日期时间类型的索引。
本地化时区
✏️本地化是什么意思?
本地化意味着将给定的时区更改为目标或所需的时区。这样做不会改变数据集中的任何内容,只是日期和时间将显示在所选择的时区中。
✏️ 为什么需要它?
如果你拿到的时间序列数据集是UTC格式的,而你的客户要求你根据例如美洲时区来处理气候数据。你就需要在将其提供给模型之前对其进行更改,因为如果您不这样做模型将生成的结果将全部基于UTC。
✏️ 如何修改
只需要更改数据集的索引部分
df.index=df.index.tz_localize("UTC")
看看下面的结果:
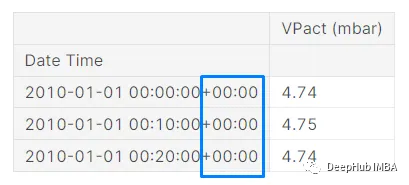
数据集的索引部分发生变化。日期和时间和以前一样,但现在它在最后显示+00:00。这意味着pandas现在将索引识别为UTC时区的时间实例。
现在我们可以专注于将UTC时区转换为我们想要的时区。
df.index=df.index.tz_convert("Asia/Qatar")
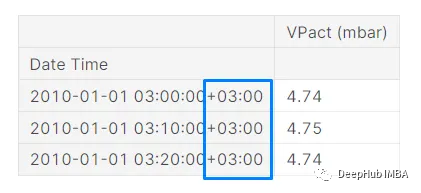
现在我们的时区已经改变到卡塔尔时区+03:00。
时间窗口重采样
在本节中将研究如何根据时间间隔来预测时间序列数据。
✏️这是什么意思?
这意味着收集一定范围的目标值(在本例中为蒸气压读数)并以某种方式概括它们,以便我们可以大致了解数据集中的趋势。我们可以通过取平均值、最大值、最小值等来概括假设一次读数的组。这里我们将5 个读数分成一组,也就是我们所说的时间窗口
✏️ 我们为什么需要它?
我将用一个例子来解释这一点。假设客户的问题是:
“我给你我的气候传感器读数,每 10 分钟获取一次,我希望你告诉我每天对蒸气压的预测。也就是说,我想要对未来每一天的预测。”
现在你可能会说,这有什么大不了的?我们手上有一些读数,每 10 分钟读取一次,我们只需要预测每天的气压。
在我们开始工作之前,让我们先对器进行可视化:
fig, ax=plt.subplots(figsize=(15, 6))
df['VPact (mbar)'].plot(ax=ax,xlabel='Time', ylabel='VPact (mbar)')
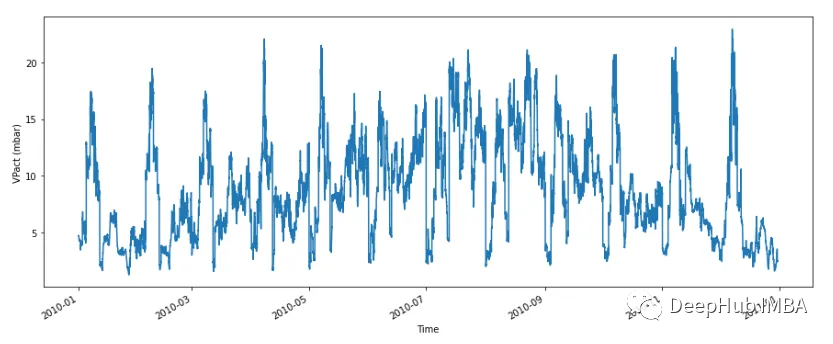
✏️ 如何重采样
现在,我们重新采样数据集,并使其成为汇总数据的单行/记录。
resampled_df=df["VPact (mbar)"].resample("1D")
这可能看起来很奇怪,但它返回的是一个对象而不是一个DF。如果我们试图运行resampled_df.head(),它会抛出一个错误。这是因为虽然已经将它重新采样为每行一天,但我们还没有告诉它应该如何聚合一天窗口中出现的所有读数。
聚合的操作包括:最大值、最小值、平均值、众数?本文中我们取平均值。
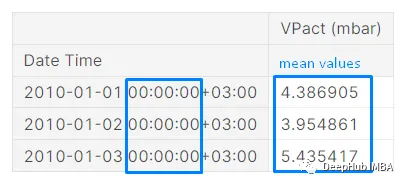
resampled_df.mean()
# OUTPUT:
# Date Time
# 2010-01-01 00:00:00+03:00 4.386905
# 2010-01-02 00:00:00+03:00 3.954861
# 2010-01-03 00:00:00+03:00 5.435417
# 2010-01-04 00:00:00+03:00 5.129375
# 2010-01-05 00:00:00+03:00 10.372361
# Freq: D, Name: VPact (mbar), Length: 365, dtype: float64
我们还需要将其转换为df。
resampled_df = resampled_df.mean().to_frame()
时间索引从每分钟读数变为每天。我们再次可视化
fig, ax = plt.subplots(figsize=(15, 6))
resampled_df['VPact (mbar)'].plot(ax=ax,xlabel='Time', ylabel='VPact (mbar)')
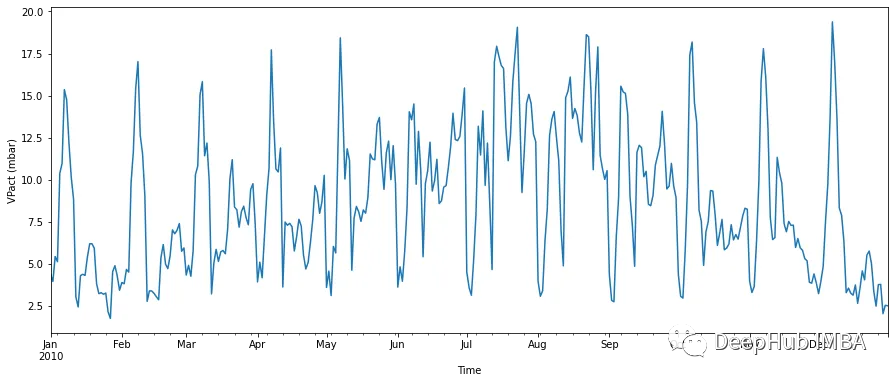
时间间隔小了很多,显示的也是每天的数据
填补时间空白
本节中将介绍如何填充数据中的时间间隔。
✏️这是什么意思?
时间序列数据由是一段连续的时间产生的数据组成。如果在数据集中有一些缺失的数据会就会在时间间隔上产生裂缝
✏️为什么需要它?
如果给模型提供有空白的数据,模型会立即崩溃,这是我们不想看到的。
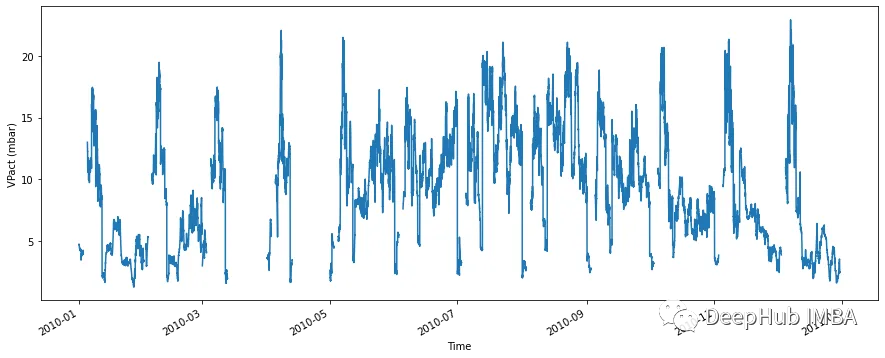
让我们假设我们的数据集有一些空值序列。数据集看起来像这样:
fig, ax=plt.subplots(figsize=(15, 6))
df_with_gap['VPact (mbar)'].plot(ax=ax,xlabel='Time', ylabel='VPact (mbar)')
✏️ 如何填充空白
我们尝试各种各样的值来填补这一空白。但是没有一个是标准,因为所有的填充值都只是对实际值的广义猜测。
在这个的例子中,我只展示其中一种填充方法,其他的方法都与其类似。这里将使用正向填充法。这个方法遍历我数据集,并获取它在遇到空白之前读取的最后一个值,并用最后一个值填充整个空白。这个方法虽然简单,但在很多情况下还是有用的。
df_with_gap=df_with_gap['VPact (mbar)'].fillna(method="ffill")
我们还将它转换成一个DF。
df_with_gap=df_with_gap.to_frame()
现在让我们看看数据集。应该看一条完整的线,并且不包含空白的空间。
fig, ax=plt.subplots(figsize=(15, 6))
df_with_gap['VPact (mbar)'].plot(ax=ax,xlabel='Time', ylabel='VPact (mbar)')
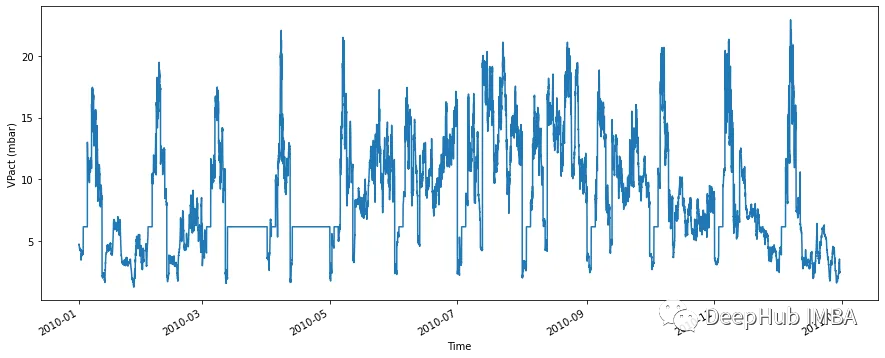
缺失的数据现在已经被补齐了。
总结
以上就是3个常用的时间数据处理的操作,希望对你有帮助。
本文源代码
https://www.kaggle.com/code/muhammadhammad02/wrangling-concepts-with-time-series-data
作者:Muhammad Hammad Hassan