
Deephub
更多文章请关注公众号:Deephub-IMBA
Adam-mini:内存占用减半,性能更优的深度学习优化器
论文提出一种新的优化器Adam-mini,在不牺牲性能的情况下减少Adam优化器的内存占用。
深度学习中常用损失函数介绍
选择正确的损失函数对于训练机器学习模型非常重要。不同的损失函数适用于不同类型的问题。本文将总结一些常见的损失函数,并附有易于理解的解释、用法和示例
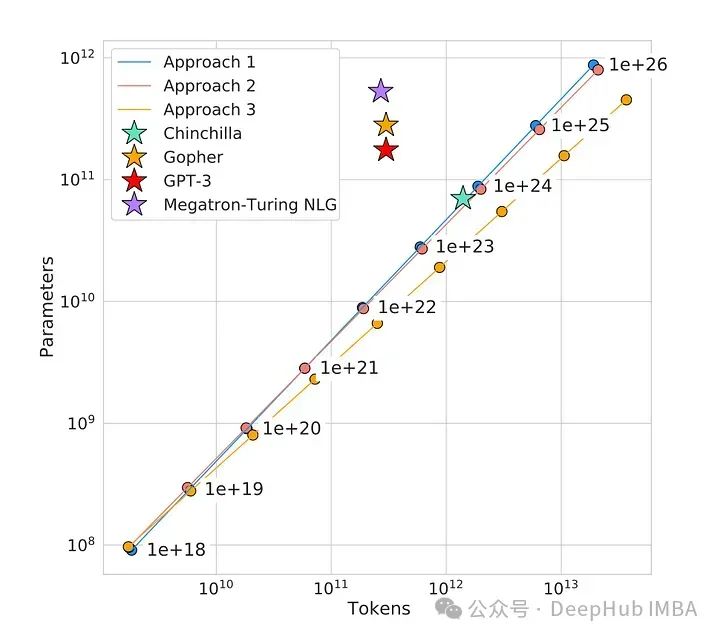
大语言模型的Scaling Law:如何随着模型大小、训练数据和计算资源的增加而扩展
在这篇文章中,我们将介绍使这些模型运作的秘密武器——一个由三个关键部分组成的法则:模型大小、训练数据和计算能力。通过理解这些因素如何相互作用和规模化,我们将获得关于人工智能语言模型过去、现在和未来的宝贵见解。
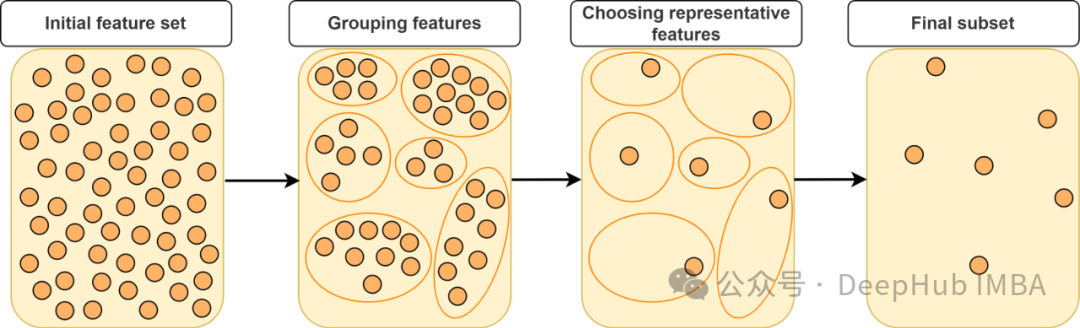
精简模型,提升效能:线性回归中的特征选择技巧
在本文中,我们将探讨各种特征选择方法和技术,用以在保持模型评分可接受的情况下减少特征数量。通过减少噪声和冗余信息,模型可以更快地处理,并减少复杂性。

贝叶斯分析与决策理论:用于确定分类问题决策点的应用
在分类问题中,一个常见的难题是决定输出为数字时各类别之间的切分点。

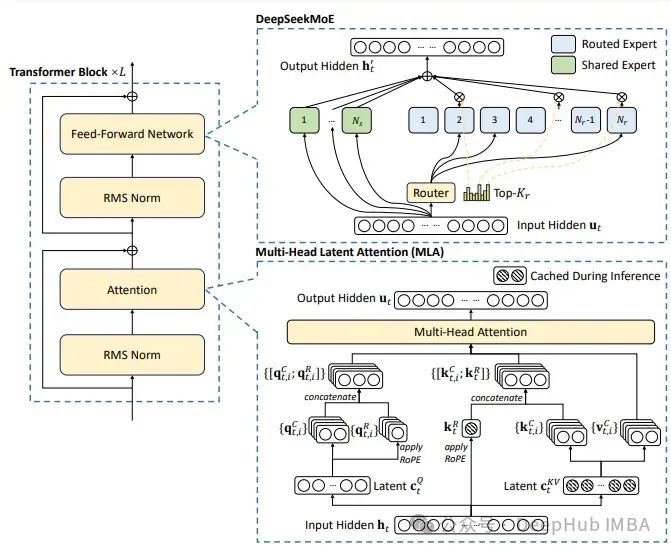
用PyTorch从零开始编写DeepSeek-V2
DeepSeek-V2是一个强大的开源混合专家(MoE)语言模型,通过创新的Transformer架构实现了经济高效的训练和推理。该模型总共拥有2360亿参数,其中每个令牌激活21亿参数,支持最大128K令牌的上下文长度。
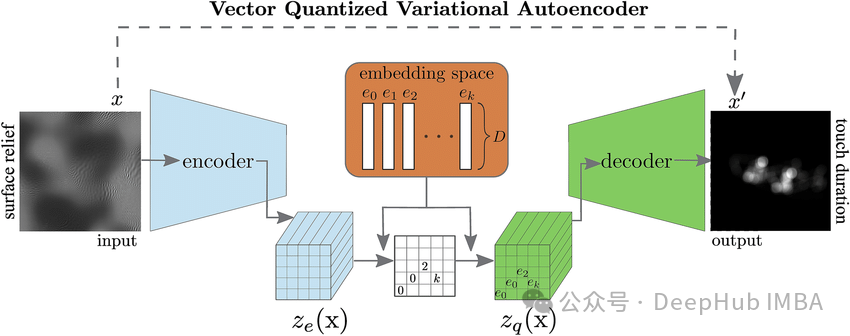
VQ-VAE:矢量量化变分自编码器,离散化特征学习模型
VQ-VAE 是变分自编码器(VAE)的一种改进。这些模型可以用来学习有效的表示。本文将深入研究 VQ-VAE 之前,不过,在这之前我们先讨论一些概率基础和 VAE 架构。

PyTorch Tabular:高效优化结构化数据处理的强大工具
PyTorch Tabular 是一个用于构建和训练深度学习模型以解决各种表格数据问题的库。
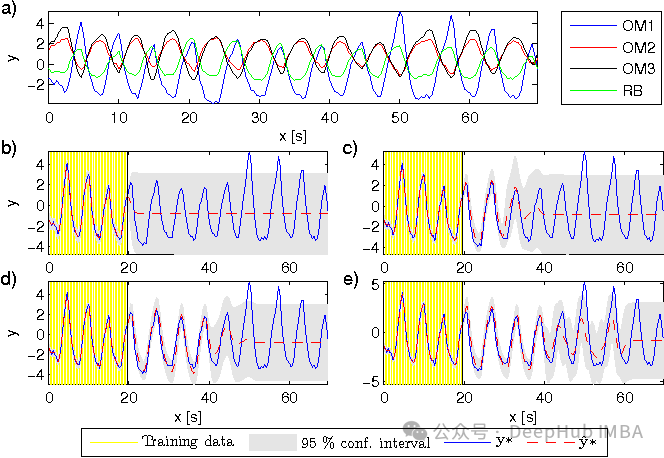
多任务高斯过程数学原理和Pytorch实现示例
本文将介绍如何通过共区域化的内在模型(ICM)和共区域化的线性模型(LMC),使用高斯过程对多个相关输出进行建模。
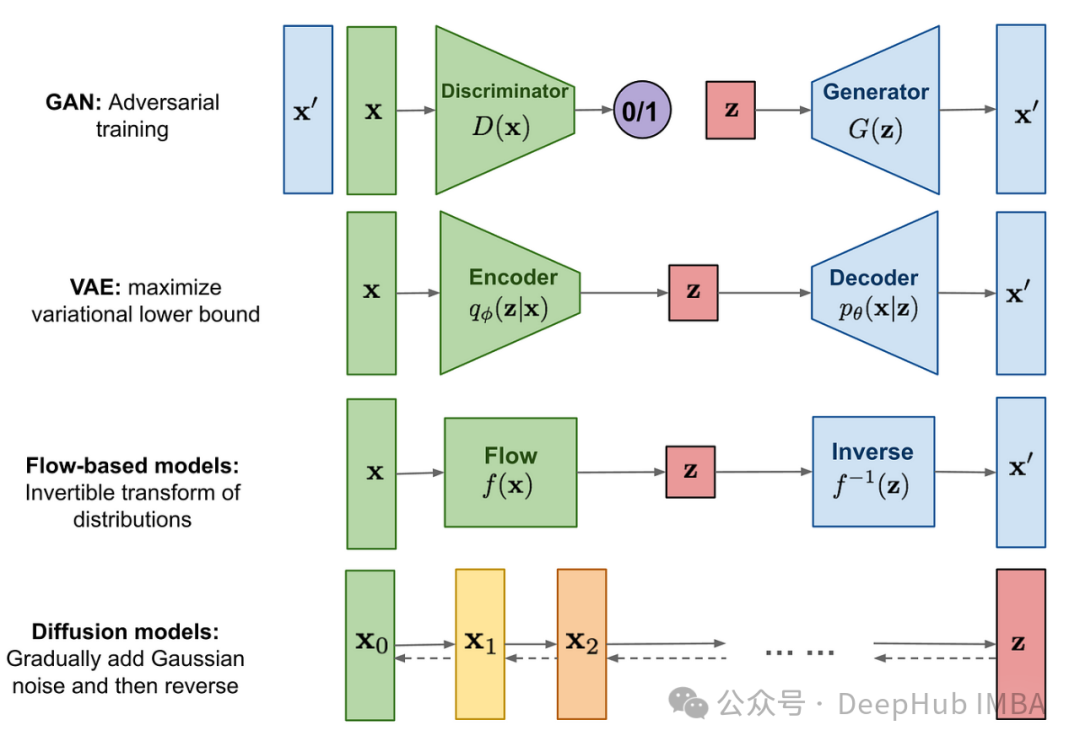
使用Pytorch中从头实现去噪扩散概率模型(DDPM)
在本文中,我们将构建基础的无条件扩散模型,即去噪扩散概率模型(DDPM)。从探究算法的直观工作原理开始,然后在PyTorch中从头构建它。本文主要关注算法背后的思想和具体实现细节。

谷歌的时间序列预测的基础模型TimesFM详解和对比测试
在本文中,我们将介绍模型架构、训练,并进行实际预测案例研究。将对TimesFM的预测能力进行分析,并将该模型与统计和机器学习模型进行对比。
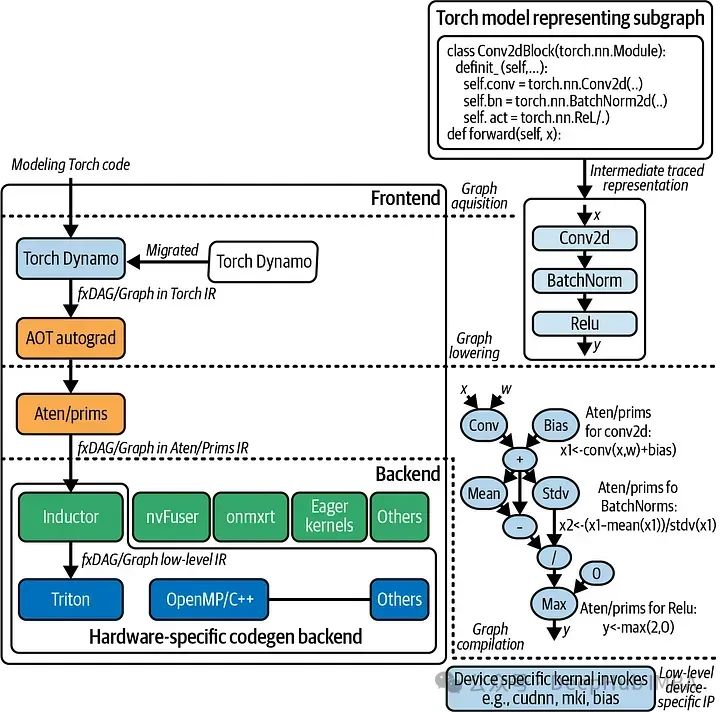
Pytorch的编译新特性TorchDynamo的工作原理和使用示例
TorchDynamo 是一个由 PyTorch 团队开发的编译器前端,它旨在自动优化 PyTorch 程序以提高运行效率。

注意力机制中三种掩码技术详解和Pytorch实现
在这篇文章中,我们将探索在注意力机制中使用的各种类型的掩码,并在PyTorch中实现它们。
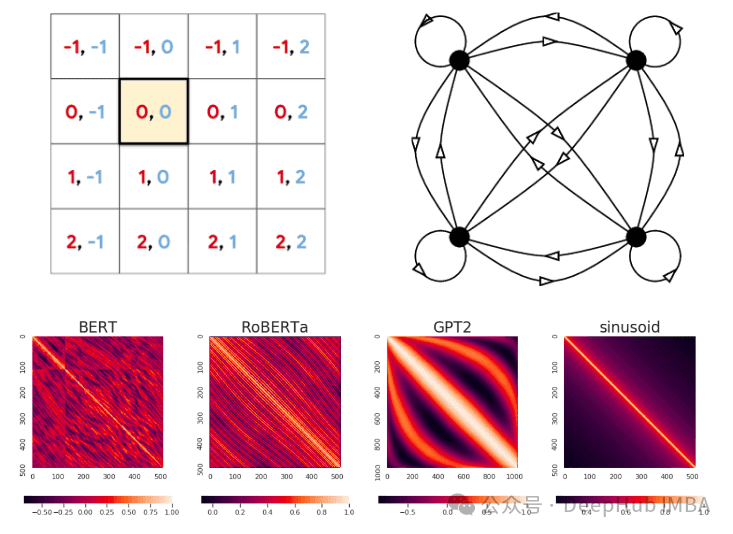
Transformer中高级位置编码的介绍和比较:Linear Rope、NTK、YaRN、CoPE
绝对和相对位置编码是最常见的两种位置编码方式,但是本文将要比较更高级的位置编码方法: 1、RoPE 位置编码及其变体 2、CoPE

Doping:使用精心设计的合成数据测试和评估异常检测器的技术
使用Doping方法,真实数据行会被(通常是)随机修改,修改的方式是确保它们在某些方面可能成为异常值,这时应该被异常检测器检测到。然后通过评估检测器检测Doping记录的效果来评估这些检测器。
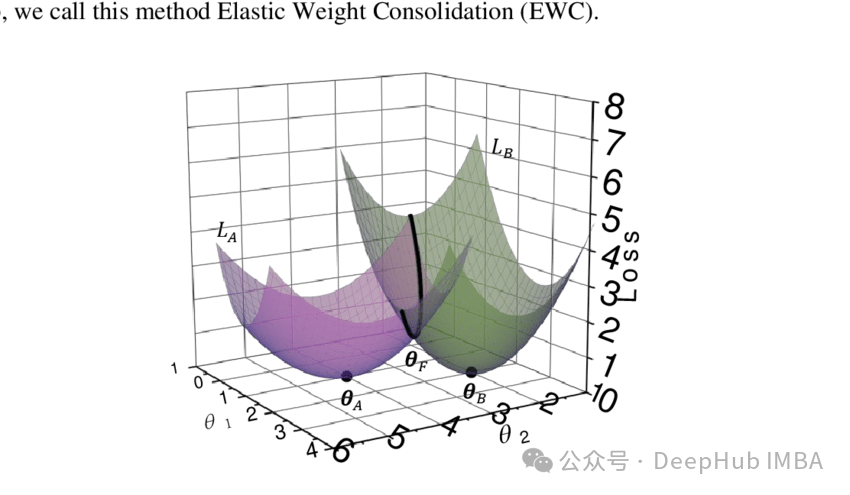
持续学习中避免灾难性遗忘的Elastic Weight Consolidation Loss数学原理及代码实现
Elastic Weight Consolidation。EWC提供了一种很有前途的方法来减轻灾难性遗忘,使神经网络在获得新技能的同时保留先前学习任务的知识。
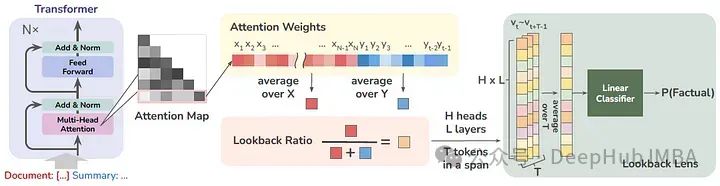
Lookback Lens:用注意力图检测和减轻llm的幻觉
这篇论文的作者提出了一个简单的幻觉检测模型,其输入特征由上下文的注意力权重与新生成的令牌(每个注意头)的比例给出。
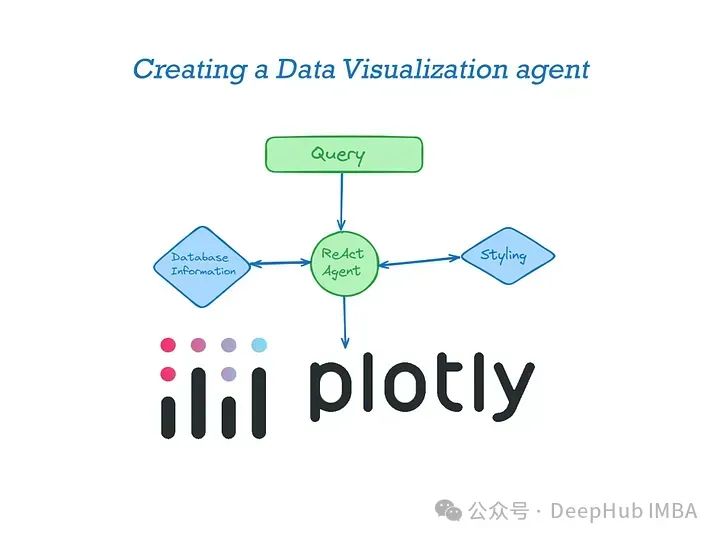
LLM代理应用实战:构建Plotly数据可视化代理
我们构建一个数据可视化的代理,通过代理我们只需提供很少的信息就能够让LLM生成我们定制化的图表。
统计学入门:时间序列分析基础知识详解
时间序列分析中包含了许多复杂的数学公式,它们往往难以留存于记忆之中。为了更好地掌握这些内容,本文将整理并总结时间序列分析中的一些核心概念,如自协方差、自相关和平稳性等