
混合精度已经成为训练大型深度学习模型的必要条件,但也带来了许多挑战。将模型参数和梯度转换为较低精度数据类型(如FP16)可以加快训练速度,但也会带来数值稳定性的问题。使用进行FP16 训练梯度更容易溢出或不足,导致优化器计算不精确,以及产生累加器超出数据类型范围的等问题。
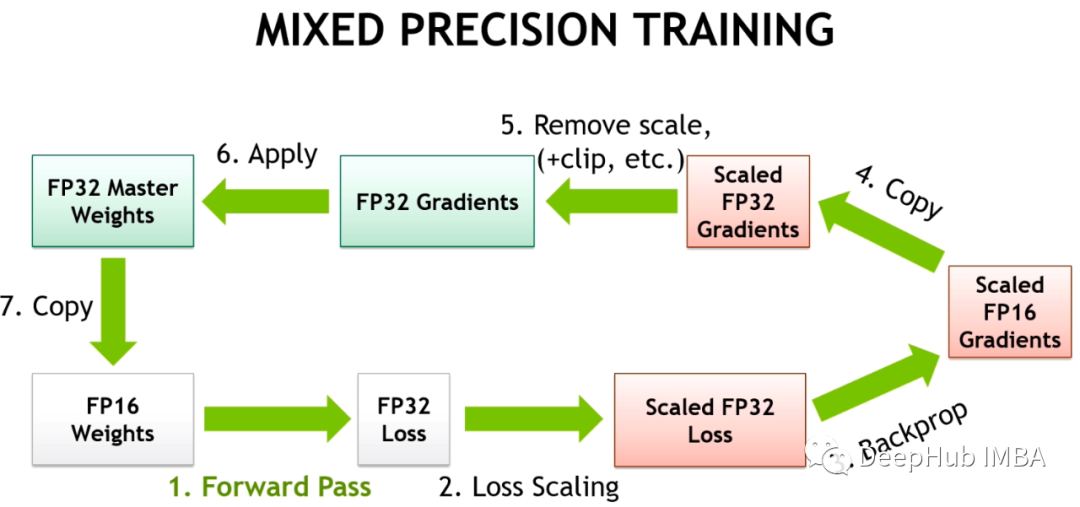
在这篇文章中,我们将讨论混合精确训练的数值稳定性问题。为了处理数值上的不稳定性,大型训练工作经常会被搁置数天,会导致项目的延期。所以我们可以引入Tensor Collection Hook来监控训练期间的梯度条件,这样可以更好地理解模型的内部状态,更快地识别数值不稳定性。
在早期训练阶段了解模型的内部状态可以判断模型在后期训练中是否容易出现不稳定是非常好的办法,如果能够在训练的头几个小时就能识别出梯度不稳定性,可以帮助我们提升很大的效率。所以本文提供了一系列值得关注的警告,以及数值不稳定性的补救措施。
混合精度训练
随着深度学习继续向更大的基础模型发展。像GPT和T5这样的大型语言模型现在主导着NLP,在CV中对比模型(如CLIP)的泛化效果优于传统的监督模型。特别是CLIP的学习文本嵌入意味着它可以执行超过过去CV模型能力的零样本和少样本推理,训练这些模型都是一个挑战。
这些大型的模型通常涉及深度transformers网络,包括视觉和文本,并且包含数十亿个参数。GPT3有1750亿个参数,CLIP则是在数百tb的图像上进行训练的。模型和数据的大小意味着模型需要在大型GPU集群上进行数周甚至数月的训练。为了加速训练减少所需gpu的数量,模型通常以混合精度进行训练。
混合精确训练将一些训练操作放在FP16中,而不是FP32。在FP16中进行的操作需要更少的内存,并且在现代gpu上可以比FP32的处理速度快8倍。尽管在FP16中训练的大多数模型精度较低,但由于过度的参数化它们没有显示出任何的性能下降。
随着英伟达在Volta架构中引入Tensor Cores,低精度浮点加速训练更加快速。因为深度学习模型有很多参数,任何一个参数的确切值通常都不重要。通过用16位而不是32位来表示数字,可以一次性在Tensor Core寄存器中拟合更多参数,增加每个操作的并行性。

但FP16的训练是存在挑战性的。因为FP16不能表示绝对值大于65,504或小于5.96e-8的数字。深度学习框架例如如PyTorch带有内置工具来处理FP16的限制(梯度缩放和自动混合精度)。但即使进行了这些安全检查,由于参数或梯度超出可用范围而导致大型训练工作失败的情况也很常见。深度学习的一些组件在FP32中发挥得很好,但是例如BN通常需要非常细粒度的调整,在FP16的限制下会导致数值不稳定,或者不能产生足够的精度使模型正确收敛。这意味着模型并不能盲目地转换为FP16。
所以深度学习框架使用自动混合精度(AMP),它通过一个预先定义的FP16训练安全操作列表。AMP只转换模型中被认为安全的部分,同时将需要更高精度的操作保留在FP32中。另外在混合精度训练中模型中通过给一些接近于零梯度(低于FP16的最小范围)的损失乘以一定数值来获得更大的梯度,然后在应用优化器更新模型权重时将按比例向下调整来解决梯度过小的问题,这种方法被称为梯度缩放。
下面是PyTorch中一个典型的AMP训练循环示例。

梯度缩放器scaler会将损失乘以一个可变的量。如果在梯度中观察到nan,则将倍数降低一半,直到nan消失,然后在没有出现nan的情况下,默认每2000步逐渐增加倍数。这样会保持梯度在FP16范围内,同时也防止梯度变为零。
训练不稳定的案例
尽管框架都尽了最大的努力,但PyTorch和TensorFlow中内置的工具都不能阻止在FP16中出现的数值不稳定情况。
在HuggingFace的T5实现中,即使在训练之后模型变体也会产生INF值。在非常深的T5模型中,注意力值会在层上累积,最终达到FP16范围之外,这会导致值无穷大,比如在BN层中出现nan。他们是通过将INF值改为在FP16的最大值解决了这个问题,并且发现这对推断的影响可以忽略不计。
另一个常见问题是ADAM优化器的限制。作为一个小更新,ADAM使用梯度的第一和第二矩的移动平均来适应模型中每个参数的学习率。
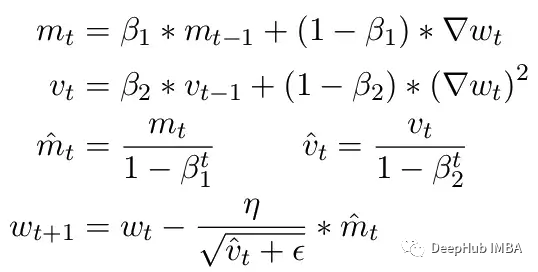
这里Beta1 和 Beta2 是每个时刻的移动平均参数,通常分别设置为 .9 和 .999。用 beta 参数除以步数的幂消除了更新中的初始偏差。在更新步骤中,向二阶矩参数添加一个小的 epsilon 以避免被零除产生错误。epsilon 的典型默认值是 1e-8。但 FP16 的最小值为 5.96e-8。这意味着如果二阶矩太小,更新将除以零。所以在 PyTorch 中为了训练不会发散,更新将跳过该步骤的更改。但问题仍然存在尤其是在 Beta2=.999 的情况下,任何小于 5.96e-8 的梯度都可能会在较长时间内停止参数的权重更新,优化器会进入不稳定状态。
ADAM的优点是通过使用这两个矩,可以调整每个参数的学习率。对于较慢的学习参数,可以加快学习速度,而对于快速学习参数,可以减慢学习速度。但如果对多个步骤的梯度计算为零,即使是很小的正值也会导致模型在学习率有时间向下调整之前发散。
另外PyTorch目前还一个问题,在使用混合精度时自动将epsilon更改为1e-7,这可以帮助防止梯度移回正值时发散。但是这样做会带来一个新的问题,当我们知道梯度在相同的范围内时,增加ε会降低了优化器适应学习率的能力。所以盲目的增加epsilon也不能解决由于零梯度而导致训练停滞的情况。
CLIP训练中的梯度缩放
为了进一步证明训练中可能出现的不稳定性,我们在CLIP图像模型上构建了一系列实验。CLIP是一种基于对比学习的模型,它通过视觉转换器和描述这些图像的文本嵌入同时学习图像。对比组件试图在每批数据中将图像匹配回原始描述。由于损失是在批次中计算的,在较大批次上的训练已被证明能提供更好的结果。
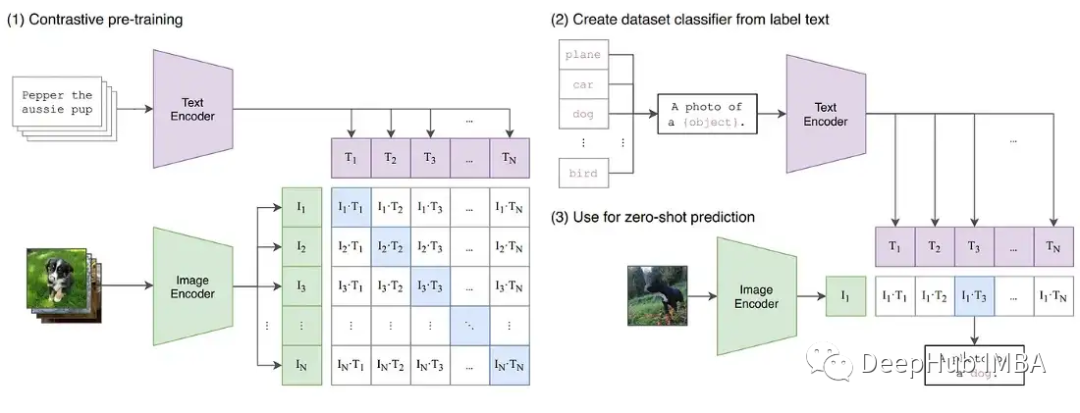
CLIP同时训练两个transformers模型,一个类似GPT的语言模型和一个ViT图像模型。两种模型的深度都为梯度增长创造了超越FP16限制的机会。OpenClip(arxiv 2212.07143)实现描述了使用FP16时的训练不稳定性。
Tensor Collection Hook
为了更好地理解训练期间的内部模型状态,我们开发了一个Tensor Collection Hook (TCH)。TCH可以包装一个模型,并定期收集关于权重、梯度、损失、输入、输出和优化器状态的摘要信息。
例如,在这个实验中,我们要找到和记录训练过程中的梯度条件。比如可能想每隔10步从每一层收集梯度范数、最小值、最大值、绝对值、平均值和标准差,并在 TensorBoard 中可视化结果。
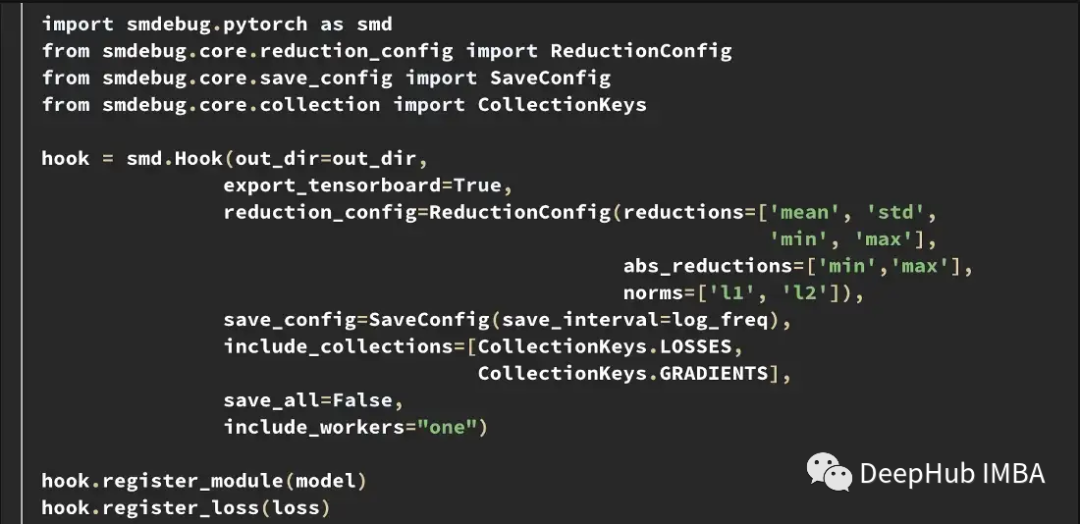
然后可以用out_dir作为--logdir输入启动TensorBoard。
实验
为了重现CLIP中的训练不稳定性,用于OpenCLIP训练Laion 50亿图像数据集的一个子集。我们用TCH包装模型,定期保存模型梯度、权重和优化器时刻的状态,这样就可以观察到不稳定发生时模型内部发生了什么。
从vvi - h -14变体开始,OpenCLIP作者描述了在训练期间存在稳定性问题。从预训练的检查点开始,将学习率提高到1-e4,与CLIP训练后半段的学习率相似。在训练进行到300步时,有意连续引入10个难度较大的训练批次。
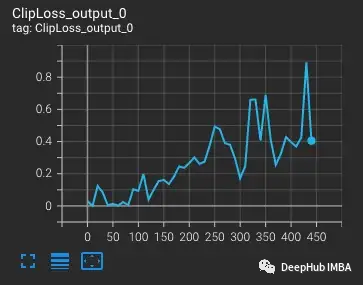
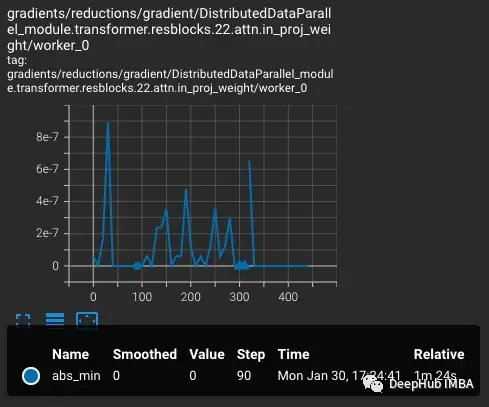
损失会随着学习率的增加而增加,这是可预期的。当在第300步引入难度较大的情况时,损失会有一个小的,但不是很大的增加。该模型发现难度较大的情况,但没有更新这些步骤中的大部分权重,因为nan出现在梯度中(在第二个图中显示为三角形)。通过这组难度较大的情况后,梯度降为零。
PyTorch梯度缩放
这里发生了什么?为什么梯度是零?问题就出在PyTorch的梯度缩放。梯度缩放是混合精度训练中的一个重要工具。因为在具有数百万或数十亿个参数的模型中,任何一个参数的梯度都很小,并且通常低于FP16的最小范围。
当混合精确训练刚刚提出时,深度学习的科学家发现他们的模型在训练早期通常会按照预期进行训练,但最终会出现分歧。随着训练的进行梯度趋于变小,一些下溢的 FP16 变为零,使训练变得不稳定。
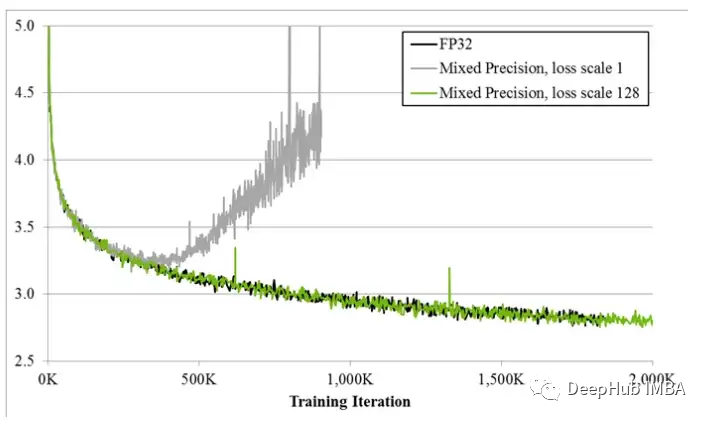
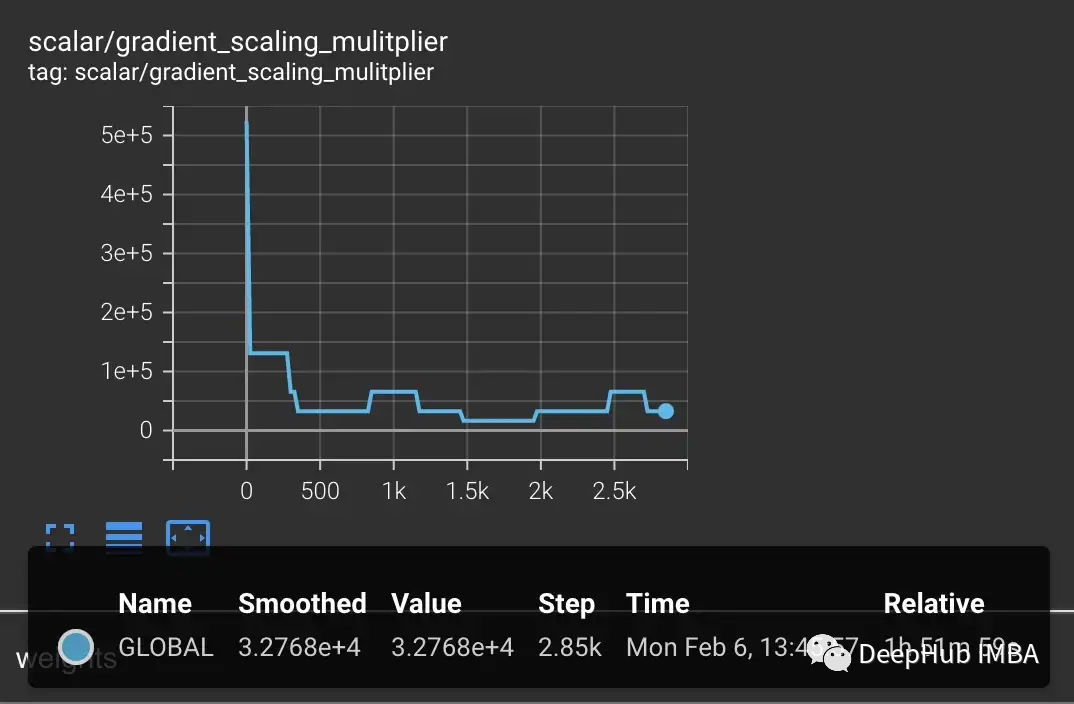
为了解决梯度下溢,早期的技术只是简单地将损失乘以一个固定的量,计算更大的梯度,然后将权重更新调整为相同的固定量(在混合精确训练期间,权重仍然存储在FP32中)。但有时这个固定的量仍然不够。而较新的技术,如PyTorch的梯度缩放,从一个较大的乘数开始,通常是65536。但是由于这可能很高,导致大的梯度会溢出FP16值,所以梯度缩放器监视将溢出的nan梯度。如果观察到nan,则在这一步跳过权重更新将乘数减半,然后继续下一步。这一直持续到在梯度中没有观察到nan。如果在2000步中梯度缩放器没有检测到nan,它将尝试使乘数加倍。
在上面的例子中,梯度缩放器完全按照预期工作。我们向它传递一组比预期损失更大的情况,这会产生更大的梯度导致溢出。但问题是现在的乘数很低,较小的梯度正在下降到零,梯度缩放器不监视零梯度只监视nan。
上面的例子最初看起来可能有些故意的成分,因为我们有意将困难的例子分组。但是经过数天的训练,在大批量的情况下,产生nan的异常情况的概率肯定会增加。所以遇到足够多的nan将梯度推至零的几率是非常大。其实即使不引入困难的样本,也经常会发现在几千个训练步骤后,梯度始终为零。
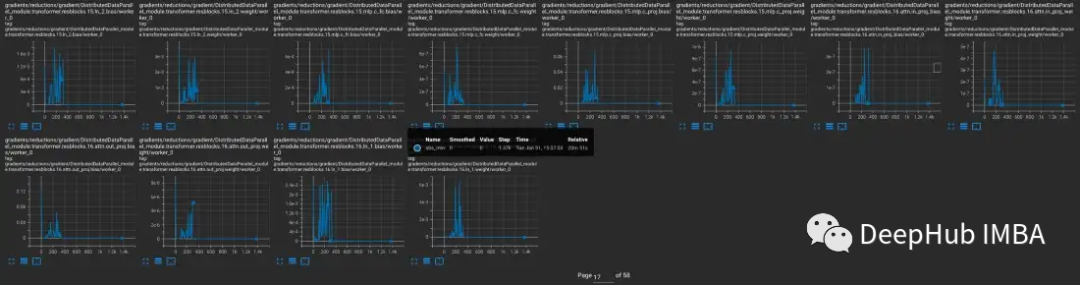
产生梯度下溢的模型
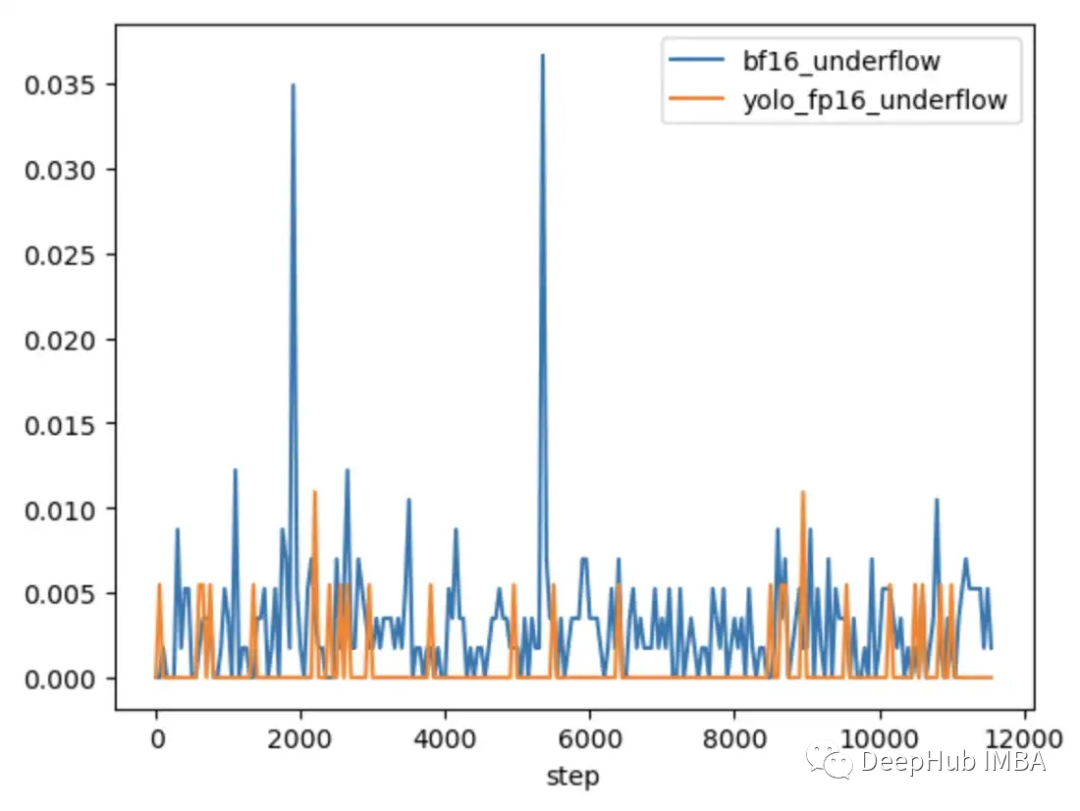
为了进一步探索问题何时发生,何时不发生,将CLIP与通常在混合精度下训练的较小CV模型YOLOV5进行了比较。在这两种情况下的训练过程中跟踪了每一层中零梯度的频率。
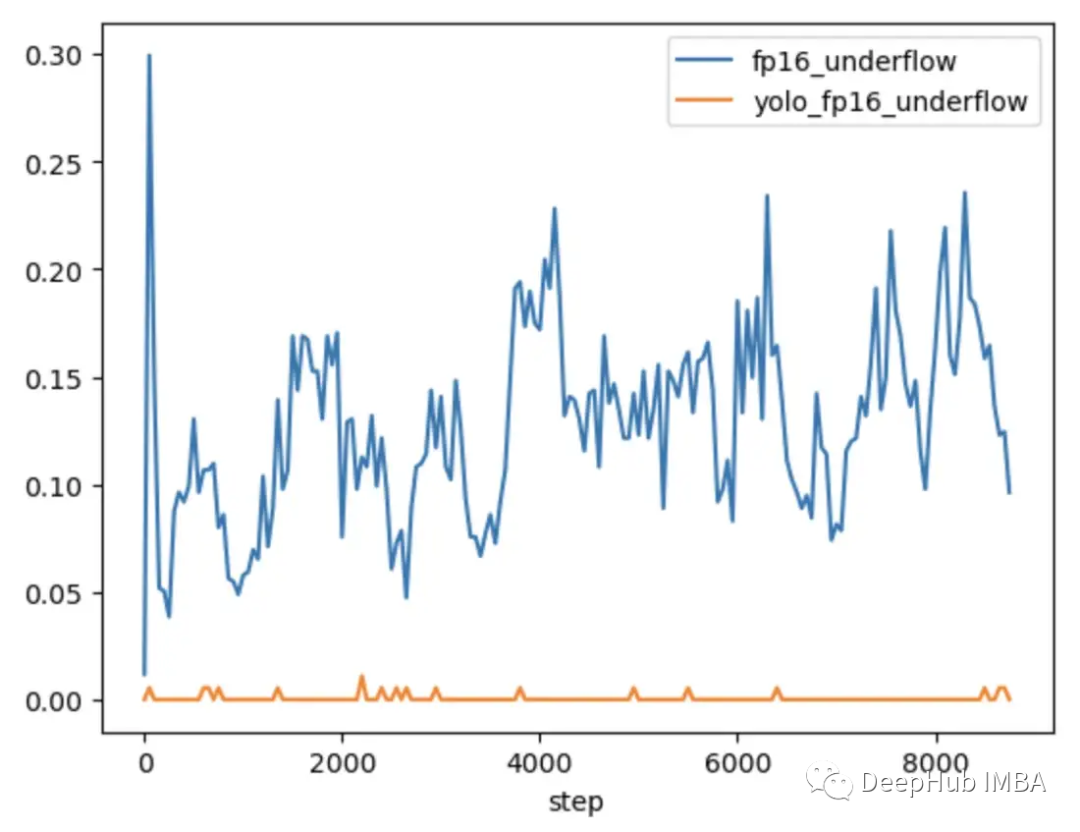
在前9000步的训练中,CLIP中5-20%的层显示梯度下溢,而Yolo中的层仅显示偶尔下溢。CLIP中的下溢率也随着时间的推移而增加,使得训练不太稳定。
使用梯度缩放并不能解决这个问题,因为CLIP范围内的梯度幅度远远大于YOLO范围内的梯度幅度。在CLIP的情况下,当梯度缩放器将较大的梯度移到FP16的最大值附近时,最小的梯度仍然低于最小值。
如何解决解CLIP中的梯度不稳定性
在某些情况下,调整梯度缩放器的参数可以帮助防止下溢。在CLIP的情况下,可以尝试修改以一个更大的乘数开始,并缩短增加间隔。

但是我们发现乘数会立即下降以防止溢出,并迫使小梯度回到零。
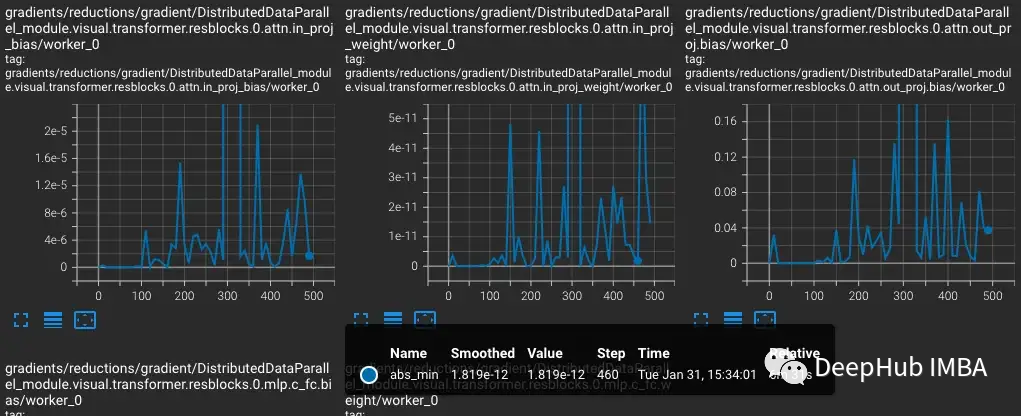
改进缩放比例的一种解决方案是使其更适应参数范围。比如论文 Adaptive Loss Scaling for Mixed Precision Training 建议按层而不是整个模型执行损失缩放,这样可以防止下溢。而我们的实验表明需要一种更具适应性的方法。由于 CLIP 层内的梯度仍然覆盖整个 FP16 范围,缩放需要适应每个单独的参数以确保训练稳定性。但是这种详细的缩放需要大量内存会减少了训练的批大小。
较新的硬件提供了更有效的解决方案。比如BFloat16 (BF16) 是另一种 16 位数据类型,它以精度换取更大的范围。FP16 处理 5.96e-8 到 65,504,而BF16 可以处理 1.17e-38 到 3.39e38,与 FP32 的范围相同。但是 BF16 的精度低于 FP16,会导致某些模型不收敛。但对于大型的transformers模型,BF16 并未显示会降低收敛性。
我们运行相同的测试,插入一批困难的观察结果,在 BF16 中,当引入困难的情况时,梯度会出现尖峰,然后返回到常规训练,因为梯度缩放由于范围增加而从未在梯度中观察到 NaN。
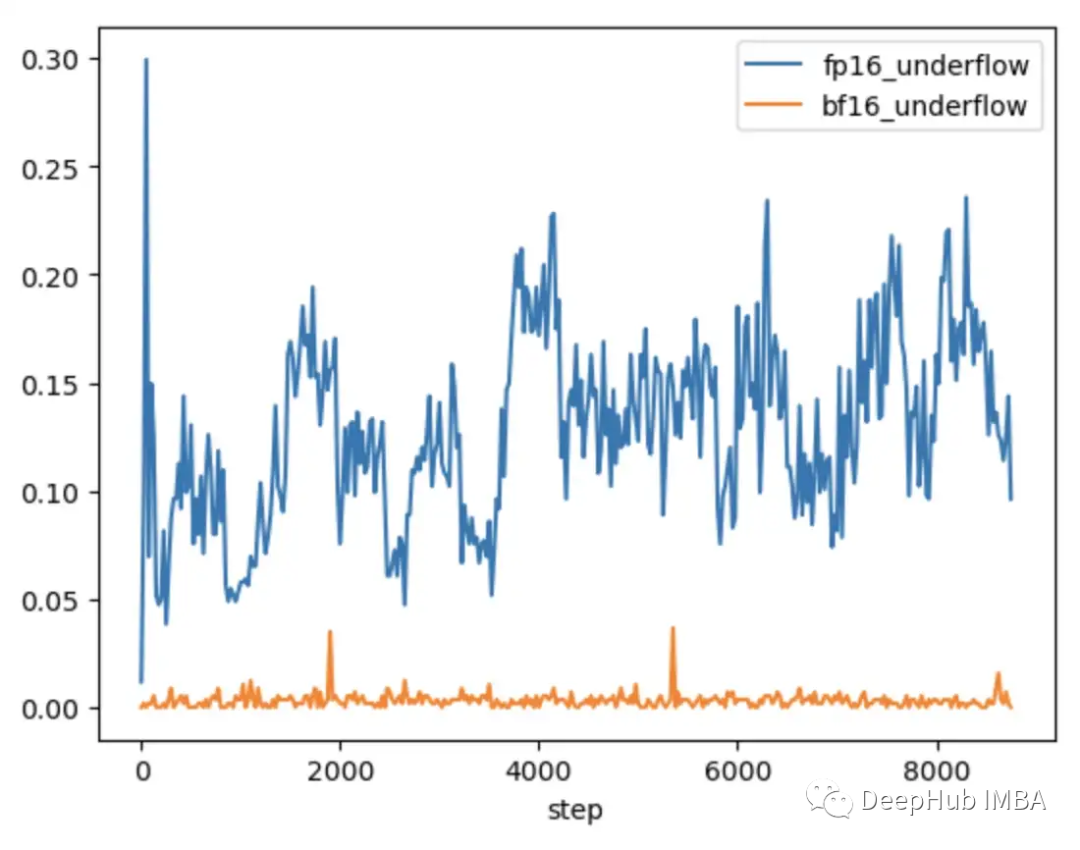
对比FP16和BF16的CLIP,我们发现BF16中只有偶尔的梯度下溢。
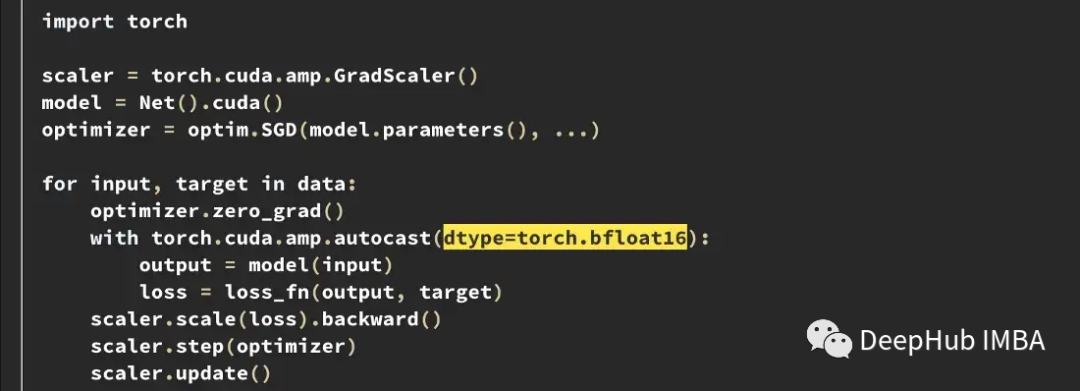
在PyTorch 1.12及更高版本中,可以通过对AMP的一个小更改来启动BF16。
如果需要更高的精度,可以试试Tensorfloat32 (TF32)数据类型。TF32由英伟达在安培GPU中引入,是一个19位浮点数,增加了BF16的额外范围位,同时保留了FP16的精度。与FP16和BF16不同,它被设计成直接取代FP32,而不是在混合精度下启用。要在PyTorch中启用TF32,在训练开始时添加两行。

这里需要注意的是:在PyTorch 1.11之前,TF32在支持该数据类型的gpu上默认启用。从PyTorch 1.11开始,它必须手动启用。TF32的训练速度比BF16和FP16慢,理论FLOPS只有FP16的一半,但仍然比FP32的训练速度快得多。
如果你用亚马逊的AWS:BF16和TF32在P4d、P4de、G5、Trn1和DL1实例上是可用的。
在问题发生之前解决问题
上面的例子说明了如何识别和修复FP16范围内的限制。但这些问题往往在训练后期才会出现。在训练早期,模型会产生更高的损失并对异常值不太敏感,就像在OpenCLIP训练中发生的那样,在问题出现之前可能需要几天的时间,这回浪费了昂贵的计算时间。
FP16和BF16都有优点和缺点。FP16的限制会导致不稳定和失速训练。但BF16提供的精度较低,收敛性也可能较差。所以我们肯定希望在训练早期识别易受FP16不稳定性影响的模型,这样我们就可以在不稳定性发生之前做出明智的决定。所以再次对比那些表现出和没有表现出后续训练不稳定性的模型,可以发现两个趋势。
在FP16中训练的YOLO模型和在BF16中训练的CLIP模型都显示出梯度下溢率一般小于1%,并且随着时间的推移是稳定的。
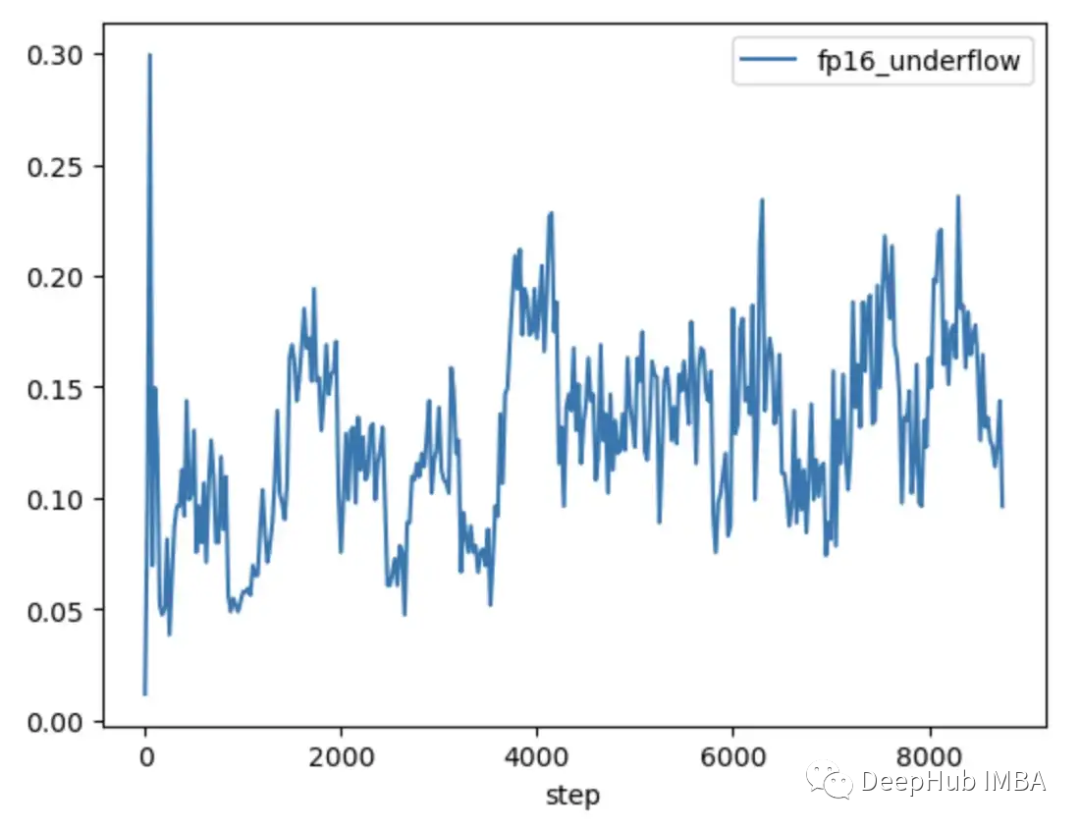
在FP16中训练的CLIP模型在训练的前1000步中下溢率为5-10%,并随着时间的推移呈现上升趋势。
所以通过使用TCH来跟踪梯度下溢率,能够在训练的前4-6小时内识别出更高梯度不稳定性的趋势。当观察到这种趋势时可以切换到BF16。
总结
混合精确训练是训练现有大型基础模型的重要组成部分,但需要特别注意数值稳定性。了解模型的内部状态对于诊断模型何时遇到混合精度数据类型的限制非常重要。通过用一个TCH包装模型,可以跟踪参数或梯度是否接近数值极限,并在不稳定发生之前执行训练更改,从而可能减少不成功的训练运行天数。
TCH的代码在这里:
https://github.com/johnbensnyder/sagemaker-debugger/tree/datatype
作者:Ben Snyder