
Deephub
更多文章请关注公众号:Deephub-IMBA

11个提升Python列表编码效率的高级技巧
Python中关于列表的一些很酷的技巧
LLM推理引擎怎么选?TensorRT vs vLLM vs LMDeploy vs MLC-LLM
有很多个框架和包可以优化LLM推理和服务,所以在本文中我将整理一些常用的推理引擎并进行比较。
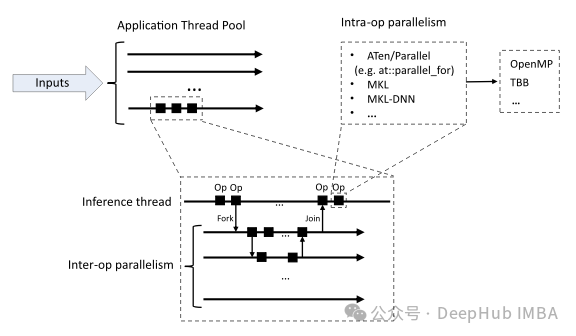
PyTorch中的多进程并行处理
这篇文章我们将介绍如何利用torch.multiprocessing模块,在PyTorch中实现高效的多进程处理。
2024年6月后2周重要的大语言模型论文总结:LLM进展、微调、推理和对齐
本文总结了2024年6月后两周发表的一些最重要的大语言模型论文。这些论文涵盖了塑造下一代语言模型的各种主题,从模型优化和缩放到推理、基准测试和增强性能。

RouteLLM:高效LLM路由框架,可以动态选择优化成本与响应质量的平衡
该论文提出了一个新的框架,用于在强模型和弱模型之间进行查询路由选择。通过学习用户偏好数据,预测强模型获胜的概率,并根据成本阈值来决定使用哪种模型处理查询 。该研究主要应用于大规模语言模型(LLMs)的实际部署中,通过智能路由在保证响应质量的前提下显著降低成本。

字符串相似度算法完全指南:编辑、令牌与序列三类算法的全面解析与深入分析
在自然语言处理领域,人们经常需要比较字符串,这些字符串可能是单词、句子、段落甚至是整个文档。本文将详细介绍这个问题。

使用 PyTorch 创建的多步时间序列预测的 Encoder-Decoder 模型
本文提供了一个用于解决 Kaggle 时间序列预测任务的 encoder-decoder 模型,并介绍了获得前 10% 结果所涉及的步骤。

图神经网络版本的Kolmogorov Arnold(KAN)代码实现和效果对比
今天我们就来使用KAN创建一个图神经网络Graph Kolmogorov Arnold(GKAN),来测试下KAN是否可以在图神经网络方面有所作为。
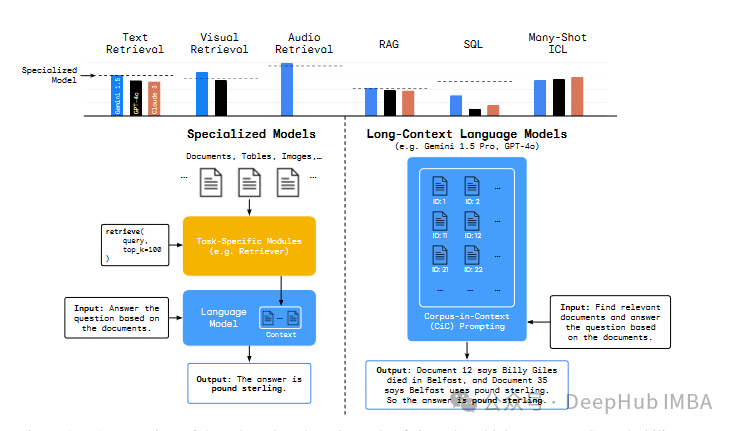
DeepMind的新论文,长上下文的大语言模型能否取代RAG或者SQL这样的传统技术呢?
关于长上下文大型语言模型是否真正利用其巨大的上下文窗口,以及它们是否真的更优越

深入解析高斯过程:数学理论、重要概念和直观可视化全解
在这篇文章中,我将详细介绍高斯过程。并可视化和Python实现来解释高斯过程的数学理论。

Transformer 能代替图神经网络吗?
今天介绍的这篇论文叫“Understanding Transformer Reasoning Capabilities via Graph Algorithms”
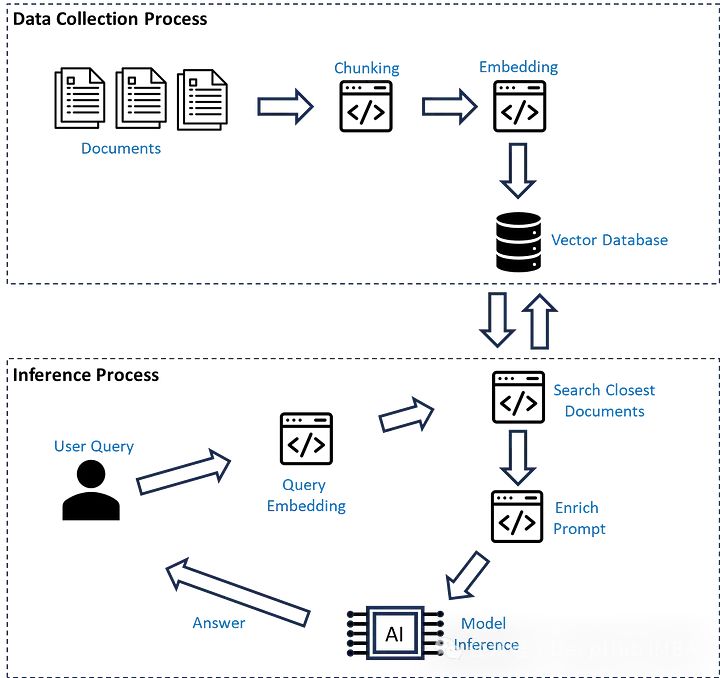
RAG流程优化(微调)的4个基本策略
在本文中,我们将介绍使用私有数据优化检索增强生成(RAG)的四种策略,可以提升生成任务的质量和准确性。通过使用一些优化策略,可以有效提升检索增强生成系统的性能和输出质量,使其在实际应用中能够更好地满足需求。

Theta方法:一种时间序列分解与预测的简化方法
Theta方法整合了两个基本概念:分解时间序列和利用基本预测技术来估计未来的价值。
精选:15款顶尖Python知识图谱(关系网络)绘制工具,数据分析的强力助手
我们今天将介绍15个很好用的免费工具,可以帮助我们绘制网络图。
2024年6月上半月30篇大语言模型的论文推荐
大语言模型(LLMs)在近年来取得了快速发展。本文总结了2024年6月上半月发布的一些最重要的LLM论文,可以让你及时了解最新进展。

特征工程与数据预处理全解析:基础技术和代码示例
我们将深入研究处理异常值、缺失值、编码、特征缩放和特征提取的各种技术。
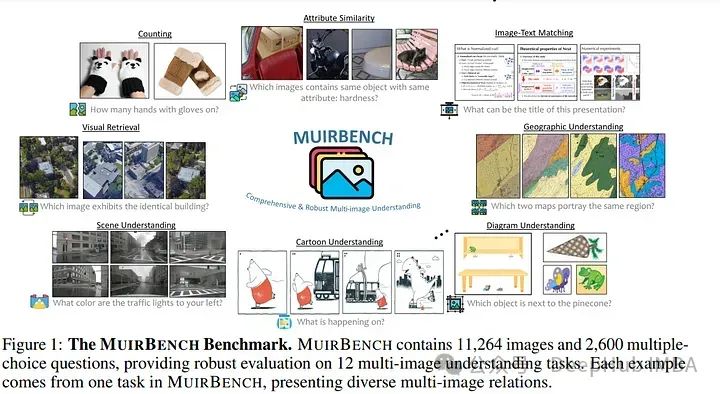
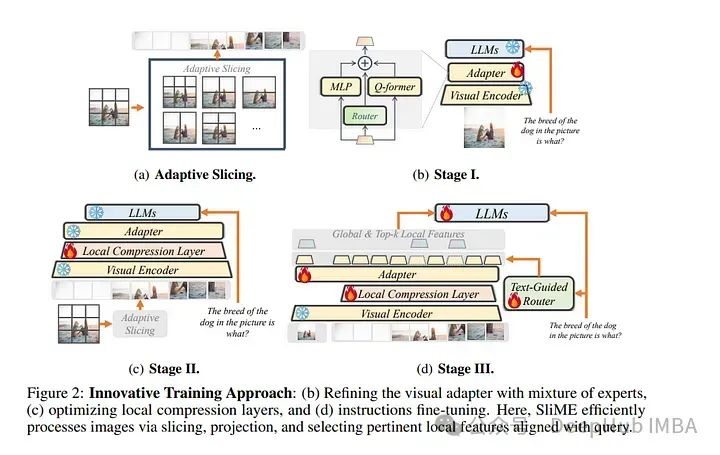
2024年6月计算机视觉论文推荐:扩散模型、视觉语言模型、视频生成等
6月还有一周就要结束了,我们今天来总结2024年6月上半月发表的最重要的论文,重点介绍了计算机视觉领域的最新研究和进展。
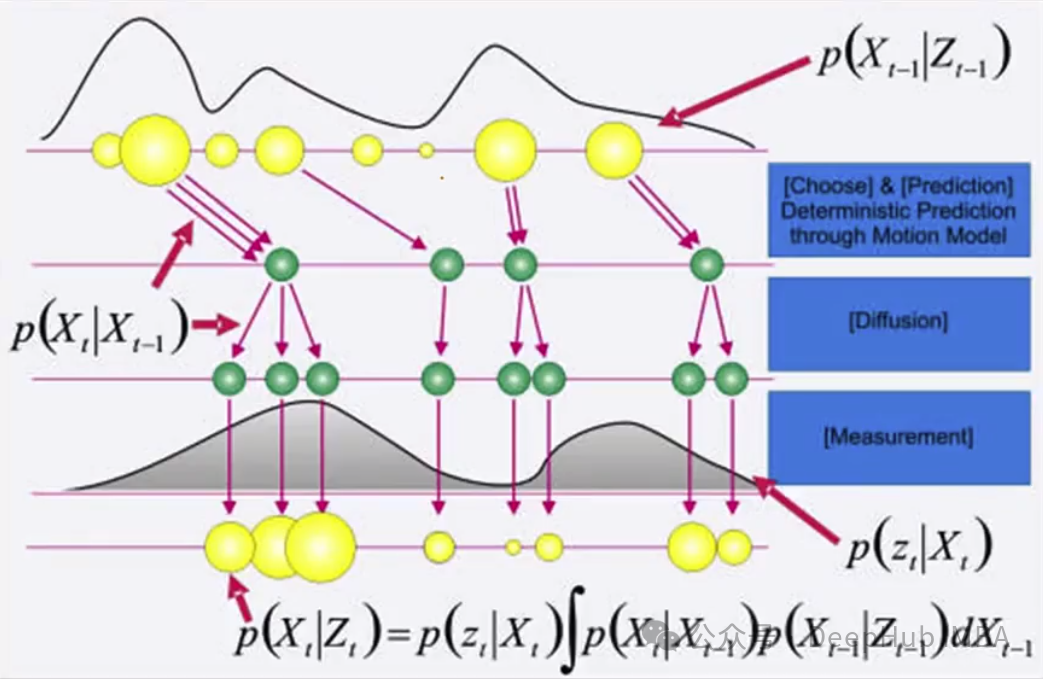
使用粒子滤波(particle filter)进行视频目标跟踪
粒子滤波是一种贝叶斯滤波方法,主要用于非线性、非高斯动态系统中的状态估计。它通过使用一组随机样本(称为粒子)来表示状态的后验概率分布,并通过这些粒子的加权平均来估计状态。
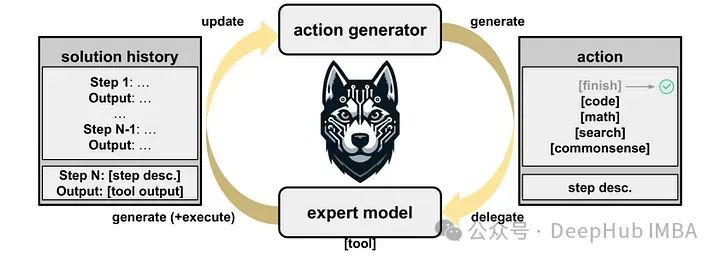
HUSKY:一个优化大语言模型多步推理的新代理框架
HUSKY是一个开源语言代理,设计用于处理各种复杂的任务,包括数字、表格和基于知识的推理。与其他专注于特定任务或使用专有模型的代理不同
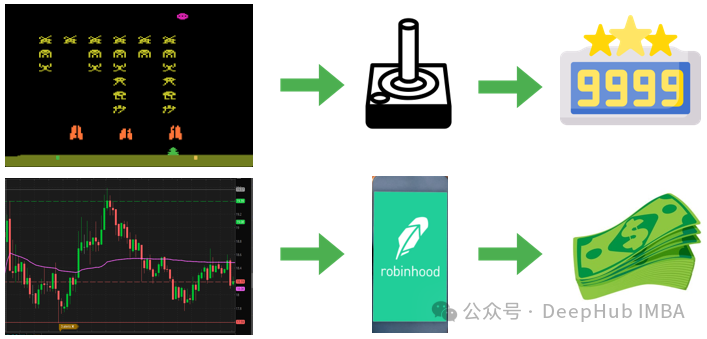
使用深度强化学习预测股票:DQN 、Double DQN和Dueling Double DQN对比和代码示例
通过DRL,研究人员和投资者可以开发能够分析历史数据的模型,理解复杂的市场动态,并对股票购买、销售或持有做出明智的决策。