
1. 引言
多代理强化学习(Multi-Agent Reinforcement Learning, MARL)是强化学习的一个重要分支,它将传统的单代理强化学习概念扩展到多代理环境中。在MARL中,多个代理通过与环境和其他代理的交互来学习最优策略,以在协作或竞争场景中最大化累积奖励。
MAgent中代理之间的对抗(混合MARL示例)
MARL的正式定义如下:多代理强化学习是强化学习的一个子领域,专注于研究在共享环境中共存的多个学习代理的行为。每个代理都受其个体奖励驱动,采取行动以推进自身利益;在某些环境中,这些利益可能与其他代理的利益相冲突,从而产生复杂的群体动态。
2. 单代理强化学习回顾
在深入MARL之前,有必要回顾单代理强化学习的基本概念。
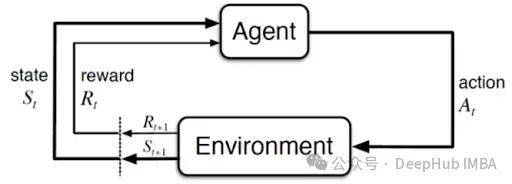
经典马尔可夫决策过程图示(来源:R. Sutton和A. Barto)
2.1 核心概念
- 代理:代理是与环境交互的实体,基于观察或状态采取行动,目标是最大化累积奖励。
- 状态和环境:环境是代理操作的外部系统。它向代理提供状态信息,接收代理的行动,并返回新的状态和奖励。状态是代理可观察到的环境当前情况的表示。
- 马尔可夫决策过程(MDPs):强化学习问题通常被formulated formulated表述为马尔可夫决策过程,用元组<S, A, P, R, γ>表示。其中S和A分别是状态空间和行动空间,P(s' | s, a)是给定行动a时从状态s转移到s'的概率,R是奖励函数,γ是折扣因子。
2.2 策略
代理的行为由其策略π指导:给定一个状态,策略输出一个行动或行动的概率分布。强化学习的目标是找到最优策略π*,以最大化长期累积奖励。
3. 单代理MDP求解方法
解决MDP的核心目标是随时间最大化累积奖励。主要的强化学习方法可分为两类:
3.1 基于价值的方法

价值函数和学习方法概览
在基于价值的方法中,代理学习价值函数,以评估状态或状态-行动对的价值,并基于这些价值选择行动。典型的基于价值的算法包括Q学习、SARSA和时序差分(TD)学习。
3.2 基于策略的方法

策略梯度方法和更新规则概览
基于策略的方法直接学习最优策略,将状态映射到行动以最大化长期奖励。常见的基于策略的算法包括策略梯度和演员-评论家方法。
4. 多代理强化学习的特点与挑战
将单代理强化学习扩展到多代理环境中,需要重新考虑系统建模方法。多代理环境通常被建模为马尔可夫博弈,其中多个代理同时交互,每个代理都影响状态转移和奖励分配。
4.1 马尔可夫博弈
马尔可夫博弈由元组(N, S, A, P, R, γ)定义:
- N:代理数量
- S:状态空间
- A = A₁ × A₂ × … × Aₙ:联合行动空间
- P:状态转移概率函数
- R = (R₁, R₂, …, Rₙ):每个代理的奖励函数集
- γ:折扣因子
4.2 MARL的类别
多代理强化学习可以根据代理之间的交互方式分为以下几类:
- 合作型MARL:代理学习共同完成任务,最大化共享奖励。适用于多机器人系统等场景。
- 竞争型MARL:代理在对抗性或零和博弈中最大化自身奖励。例如棋类游戏或对抗性场景。
- 混合利益型MARL:代理既有合作也有竞争关系,目标部分一致,部分冲突。常见于贸易、交通和多人视频游戏等复杂场景。
4.3 MARL面临的主要挑战
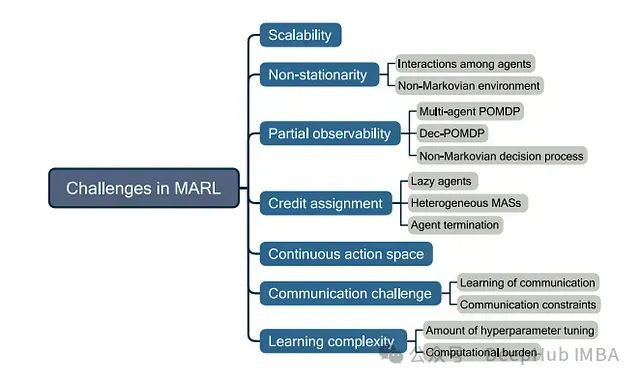
MARL中的主要挑战
4.3.1 非平稳性
在多代理环境中,每个代理面临的环境是动态变化的,因为其他代理也在不断学习和调整策略。这违反了马尔可夫性质,使得传统的强化学习方法难以直接应用。
- 影响:状态转移概率和奖励函数不再是静态的。
- 后果:代理的最优策略可能随着其他代理行为的变化而改变,导致学习过程的不稳定性。
4.3.2 部分可观察性
在大多数多代理场景中,单个代理无法获得完整的环境状态信息或其他代理的行动。
- 建模:问题转化为部分可观察马尔可夫决策过程(POMDP)。
- 挑战:代理需要在不完整信息的基础上推断隐藏状态,增加了策略学习的复杂性。
4.3.3 可扩展性和联合行动空间
随着代理数量的增加,系统的复杂度呈指数级增长。
- 联合行动空间:对于n个代理,联合行动空间为A₁ × A₂ × … × Aₙ。
- 计算挑战:状态-行动空间的急剧扩大导致计算复杂性显著增加,传统RL方法效率降低。
- 可扩展性需求:需要开发能够处理大规模多代理系统的算法。
4.3.4 信用分配问题
在合作场景中,准确评估每个代理对团队目标的贡献变得尤为复杂。
- 挑战:难以确定哪些代理的行动对实现共同目标起到了关键作用。
- 局限性:传统方法往往无法提供清晰的个体贡献洞察,影响奖励分配的公平性和有效性。
这些挑战共同构成了MARL研究的核心问题,推动了该领域算法和理论的不断发展。在接下来的章节中,我们将探讨应对这些挑战的一些主要方法和算法。
5. MARL中的决策制定与学习范式
多代理强化学习(MARL)在现实世界的多个领域都有重要应用,尤其是在机器人领域。MARL算法旨在使每个代理学习如何在最大化自身奖励的同时,维持其对全局奖励最大化的贡献。
5.1 MARL的主要学习范式
5.1.1 集中训练与分散执行(CTDE)
CTDE是MARL中一种广泛使用的范式,它在训练和执行阶段采用不同的信息访问策略:
- 训练阶段:代理可以访问全局信息。
- 执行阶段:代理仅基于局部观察进行决策。
这种方法平衡了学习效率和实际部署的需求。
5.1.2 完全分散学习
在这种范式下,代理在训练和执行过程中都无法获取其他代理的信息:
- 每个代理独立更新自己的策略。
- 目标是最大化所有代理的奖励总和。
这种方法面临的主要挑战是环境的非平稳性,因为从每个代理的角度来看,其他代理的行为变化会导致环境动态的变化。
5.2 核心算法
5.2.1 值分解网络(VDN)
VDN是一种在CTDE框架下使用的方法,其核心思想是将全局Q值分解为各个代理的Q值之和。
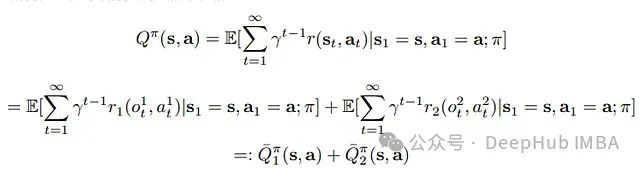
Q-tot作为各个代理Q值的总和
VDN的基本假设是联合Q函数可以加性分解为个体代理Q函数:
Q_tot = ∑ Q_i
优点:
- 允许分散执行
- 每个代理可以独立优化自身策略
局限性:
- 简单的加和可能导致策略多样性降低
- 容易陷入局部最优,特别是当Q网络在代理间共享时
5.2.2 QMIX
QMIX是对VDN的改进,引入了一个混合网络来组合个体代理值到联合Q值。
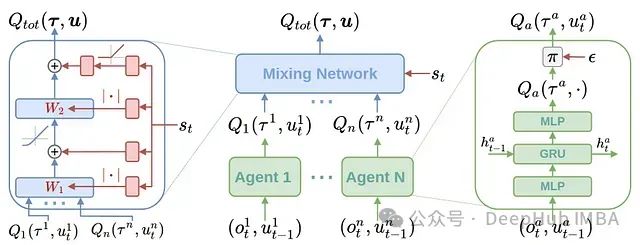
QMIX架构
核心特点:
- 使用混合网络表示个体代理值和联合Q值之间的非线性关系
- 保持单调性约束,确保行动选择的一致性
Q-tot作为混合网络输出
QMIX遵循标准的Q学习范式,使用时序差分(TD)误差更新全局Q值:
TD_error=r+γ*max_a' Q(s', a') - Q(s, a)
5.2.3 独立近端策略优化(IPPO)
IPPO是一种简单而有效的MARL算法,其中每个代理在训练和执行过程中都独立运作。
关键特点:
- 每个代理拥有独立的策略和评论家网络
- 使用PPO算法进行策略更新
IPPO使用PPO的裁剪目标函数来防止过大的策略更新:
IPPO中使用的PPO裁剪目标
优势:
- 简单,易于实现
- 良好的可扩展性
局限性:
- 可能难以实现全局最优,特别是在需要高度协调的任务中
5.2.4 多代理近端策略优化(MAPPO)
MAPPO是PPO算法在多代理场景中的扩展,采用CTDE方法。
核心思想:
- 使用中心化评论家来解决非平稳性问题
- 评论家可以访问联合状态,学习更稳定的值函数
MAPPO的策略更新通过最大化以下PPO目标来执行:
其中L_i_PPO是代理i的PPO目标。
中心化评论家通过最小化以下误差来更新:
MAPPO通过结合中心化训练和分散执行,在处理非平稳环境方面表现出色。
在下一部分中,我们将继续探讨更多高级MARL算法,以及多代理系统中的通信策略。
6. 高级MARL算法与通信策略
6.1 多代理深度确定性策略梯度(MADDPG)
MADDPG是深度确定性策略梯度(DDPG)算法在多代理环境中的扩展。它采用集中训练分散执行(CTDE)的策略,引入了中心化的Q函数来处理所有代理的联合行动。

MADDPG算法流程
核心特点如下:
- 每个代理拥有自己的演员网络(策略)和评论家网络
- 评论家网络在训练时可访问所有代理的观察和行动
- 使用目标网络来稳定学习过程
MADDPG的评论家网络更新遵循标准的Q学习范式:
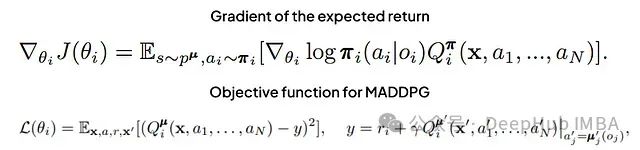
其中Q函数是中心化的动作-值函数,接受所有代理的行动作为输入。
策略更新通过最大化预期Q值来实现:
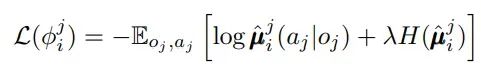
MADDPG通过允许代理学习其他代理的策略,有效地处理了非平稳环境的挑战。
6.2 MARL中的通信策略
在多代理系统中,有效的通信对于协调和决策至关重要。然而,通信也面临诸如带宽限制、不可靠信道等挑战。
代理间的三种不同通信策略
6.2.1 可微分和强化的代理间学习(RIAL/DIAL)
RIAL和DIAL是探索代理间高效通信的重要方法:
- RIAL:结合DRQN和独立Q学习,分别用于行动选择和通信
- DIAL:引入可微分通信通道,支持端到端学习
6.2.2 SchedNet
SchedNet引入了学习型调度机制,代理学习决定哪些代理应该被允许广播消息。
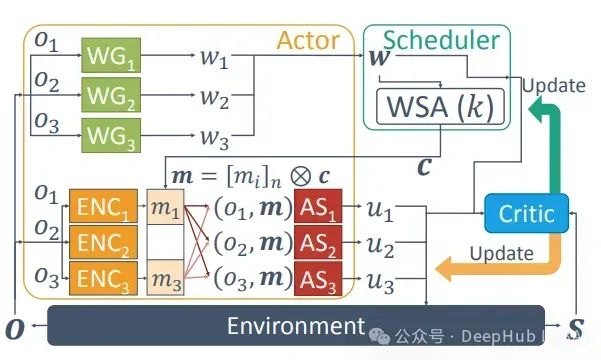
SchedNet架构
主要组件:
- 调度机制
- 消息编码
- 基于有限通信和局部观察的行动选择
6.2.3 TarMAC:目标多代理通信
TarMAC专注于提高代理间通信的效率和有效性。
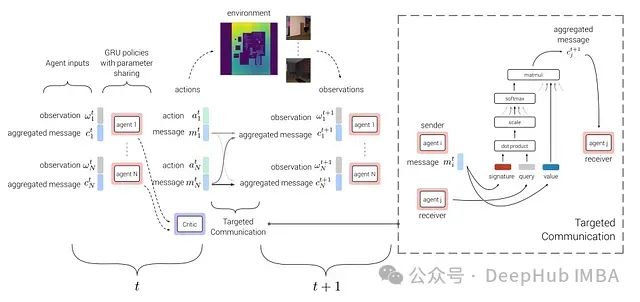
TarMAC架构
核心思想:
- 使用目标通信策略,允许代理选择性地与特定同伴通信
- 采用基于签名的软注意力机制来实现消息定向
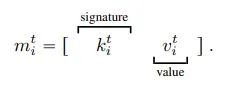
使用签名和值构建的消息
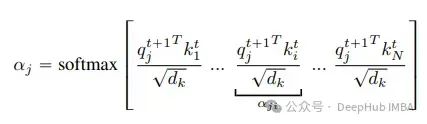
跨代理计算的注意力
6.2.4 基于自编码器的通信方法
这种方法旨在开发多代理系统中的通信语言,重点关注如何使用自编码器在环境中建立语言基础。
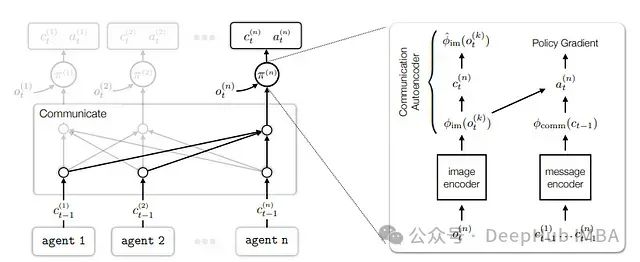
基于自编码器的通信架构
主要组件:
- 图像编码器:将原始像素观察嵌入到低维特征空间
- 通信自编码器:学习从特征空间到通信符号的映射
- 接收器模块:使用GRU策略处理编码的图像特征和消息特征
7. 结论和未来方向
多代理强化学习(MARL)通过引入多个代理在共享环境中交互的复杂性,极大地扩展了传统强化学习的边界。MARL在处理非平稳性、部分可观察性、可扩展性和信用分配等方面的挑战推动了该领域的快速发展。
未来研究方向
- 可扩展性:开发能够有效处理大规模多代理系统的算法仍然是一个关键挑战。
- 分散训练分散执行(DTDE):探索完全分散的训练和执行方法,以应对更复杂的实际场景。
- 通信策略:进一步研究高效、鲁棒的代理间通信机制,特别是在有限带宽和不可靠通道的情况下。
- 迁移学习:研究如何将学到的策略从一个多代理环境迁移到另一个环境。
- 模型化MARL:结合模型学习与MARL,提高样本效率和泛化能力。
- 公平性和伦理:探讨MARL系统中的公平性问题,以及如何在多代理决策中纳入道德和伦理考虑。
随着研究的深入和技术的进步,MARL有望在更多复杂的实际问题中发挥关键作用,推动人工智能在多代理系统中的应用不断向前发展。
论文引用
- Deep Recurrent Q-Learning for Partially Observable MDPs: https://arxiv.org/abs/1507.06527
- Is Independent Learning All You Need in the StarCraft Multi-Agent Challenge?: https://arxiv.org/abs/2011.09533
- The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games: https://arxiv.org/abs/2103.01955
- Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments: https://arxiv.org/abs/1706.02275
- Value-Decomposition Networks For Cooperative Multi-Agent Learning: https://arxiv.org/abs/1706.05296
- QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning: https://arxiv.org/abs/1803.11485
- Learning to Communicate with Deep Multi-Agent Reinforcement Learning: https://arxiv.org/abs/1605.06676
- Learning to Schedule Communication in Multi-agent Reinforcement Learning: https://arxiv.org/abs/1902.01554
- TarMAC: Targeted Multi-Agent Communication: https://arxiv.org/abs/1810.11187
- Learning to Ground Multi-Agent Communication with Autoencoders: https://arxiv.org/abs/2110.15349