Deephub
更多文章请关注公众号:Deephub-IMBA

Pandas数据合并:10种高效连接技巧与常见问题
Pandas库中的merge和join函数提供了强大的数据整合能力,但不恰当的使用可能导致数据混乱。基于对超过1000个复杂数据集的分析经验,本文总结了**10种关键技术**,帮助您高效准确地完成数据合并任务。
PINN应用案例:神经网络求解热扩散方程高质量近似解
PINN框架的关键组成是一个特殊设计的损失函数,其中包含微分方程残差项。该残差项量化了神经网络解与PDE描述的物理定律之间的偏离程度。
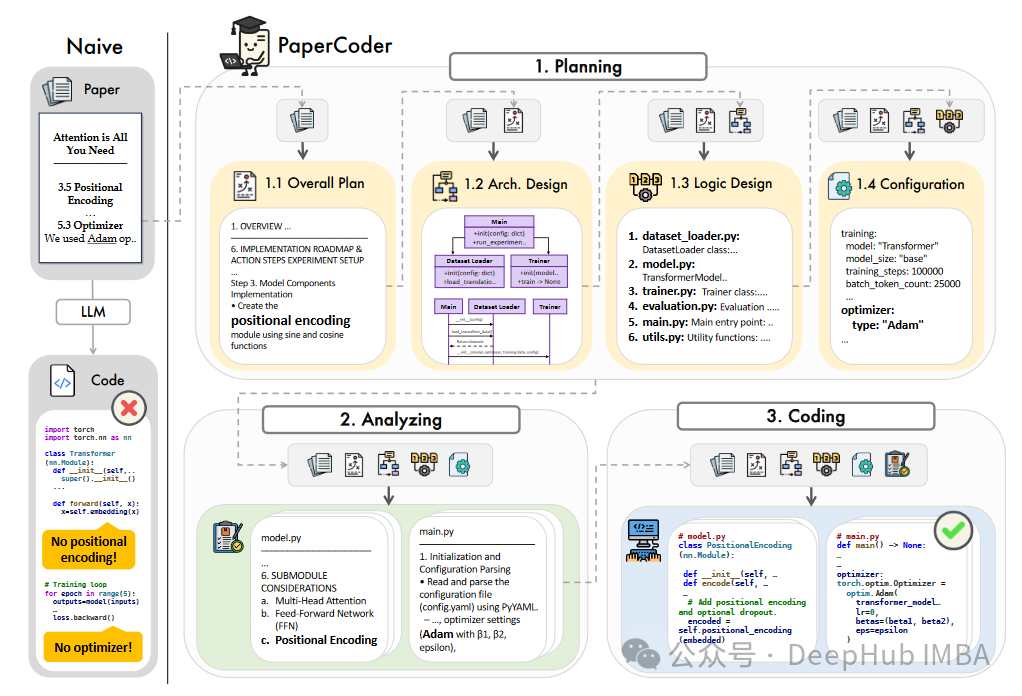
PaperCoder:一种利用大型语言模型自动生成机器学习论文代码的框架
本文介绍了一种名为PaperCoder的新型多智能体LLM框架,旨在自动生成机器学习研究论文的代码库。
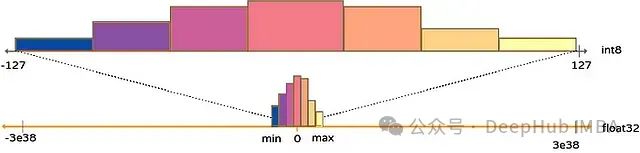
PyTorch量化感知训练技术:模型压缩与高精度边缘部署实践
本文将深入探讨模型量化的原理、主要量化技术类型以及如何使用PyTorch实现这些技术。
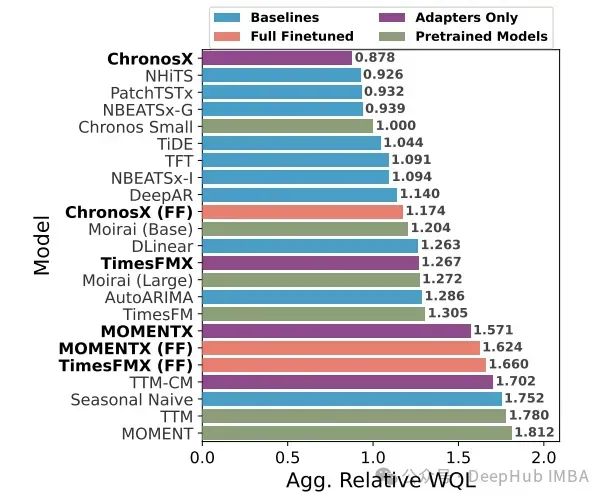
ChronosX: 可使用外生变量的时间序列预测基础模型
本文将系统剖析ChronosX的工作机制,并深入探讨其在多种基准测试中的表现。

PyTorchVideo实战:从零开始构建高效视频分类模型
本文展示了如何使用PyTorchVideo和PyTorch Lightning构建视频分类模型的完整流程。通过合理的数据处理、模型设计和训练策略,我们能够高效地实现视频理解任务。
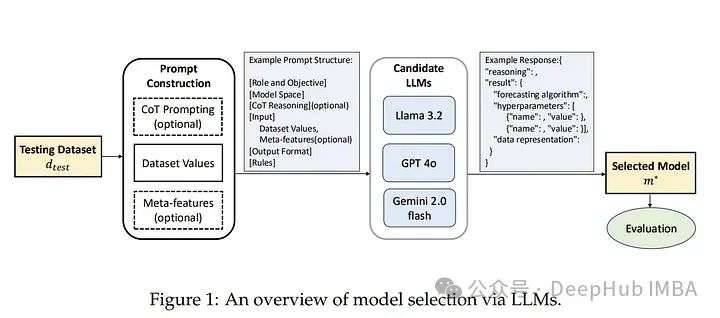
基于大型语言模型的高效时间序列预测模型选择
本文作者提出了一种基于大型语言模型(LLM)的模型选择范式。核心思想是利用LLM(如LLaMA 3.2、GPT-4o、Gemini 2.0)在零样本推理中的知识和推理能力,代替传统的性能矩阵来直接推荐最优模型。

在AMD GPU上部署AI大模型:从ROCm环境搭建到Ollama本地推理实战指南
本文以 AMD Radeon RX 7900XT 为例在 Linux 环境下解决了 ROCm 部署的诸多技术挑战。
防止交叉验证中的数据泄露:提升模型在实际环境中的性能
本文将深入探讨如何构建真正稳健的验证策略,确保模型在面对真实世界数据时依然能保持预期的性能。

提升AI训练性能:GPU资源优化的12个实战技巧
本文系统阐述的优化策略为提升 AI/ML 工作负载中的 GPU 资源利用率提供了全面技术指导。通过实施数据处理并行化、内存管理优化以及模型设计改进等技术手段

使用Torch Compile提高大语言模型的推理速度
在本文中,我们将探讨torch.compile的工作原理,并测量其对LLMs推理性能的影响。
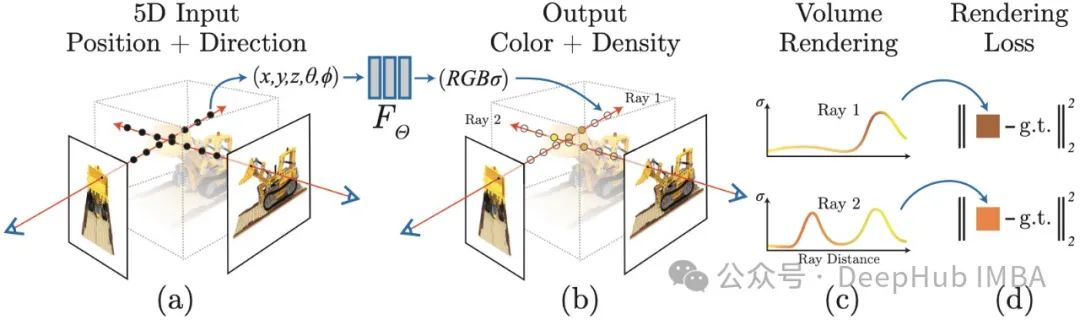
神经辐射场(NeRF)实战指南:基于PyTorch的端到端实现
本文将系统性地引导读者使用PyTorch构建完整的神经辐射场(NeRF)处理流程。从图像加载到高质量三维场景渲染,文章将详细讨论实现过程中的关键技术点和优化策略。
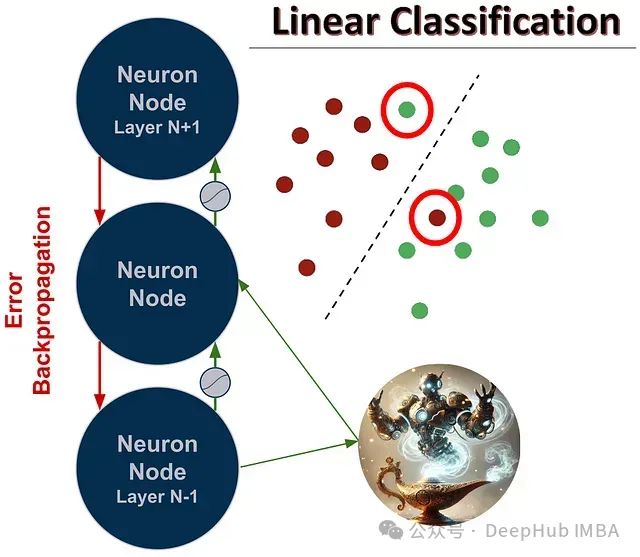
Perforated Backpropagation:神经网络优化的创新技术及PyTorch使用指南
Perforated Backpropagation技术代表了深度学习基础构建模块的重要革新,通过仿生学习机制重塑了人工神经元的计算范式。
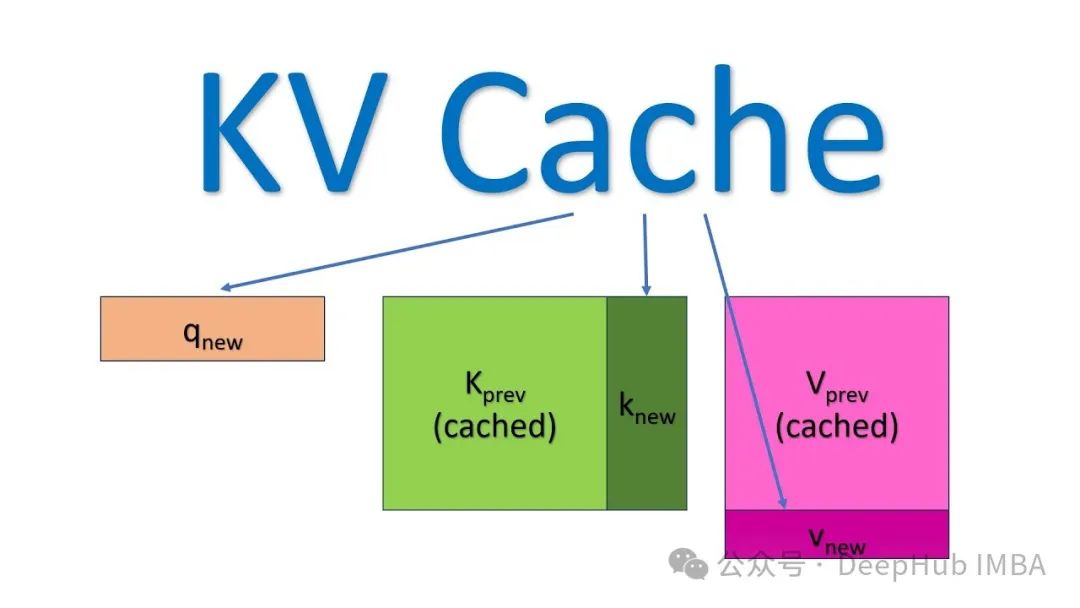
加速LLM大模型推理,KV缓存技术详解与PyTorch实现
本文详细阐述了KV缓存的工作原理及其在大型语言模型推理优化中的应用,文章不仅从理论层面阐释了KV缓存的工作原理,还提供了完整的PyTorch实现代码,展示了缓存机制与Transformer自注意力模块的协同工作方式。
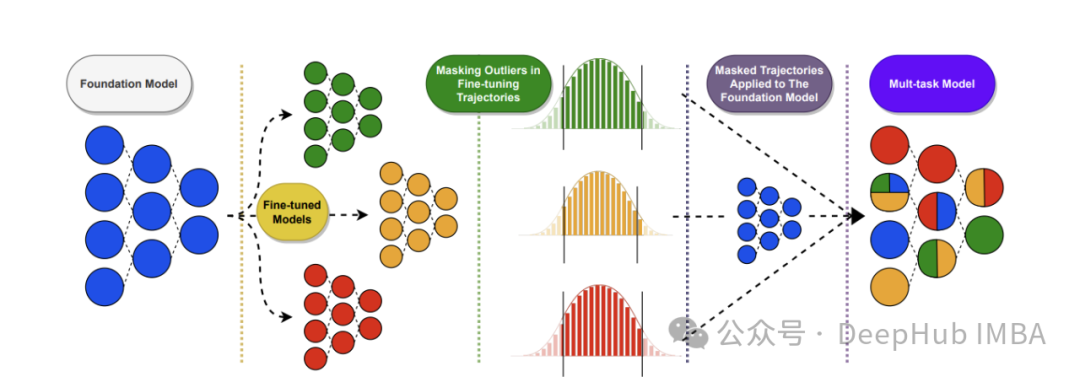
零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
本文系统介绍了11种先进的LLM权重合并策略,从简单的线性权重平均到复杂的几何映射方法,全面揭示了如何在零训练成本下优化大语言模型性能。
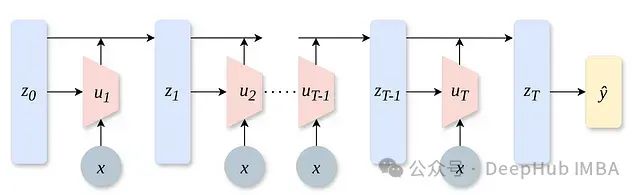
NoProp:无需反向传播,基于去噪原理的非全局梯度传播神经网络训练,可大幅降低内存消耗
NoProp的核心技术基于扩散模型的概念,通过训练网络的每一层**对注入噪声的目标标签实施去噪操作**,从而彻底重新构想了深度学习的基础训练范式。
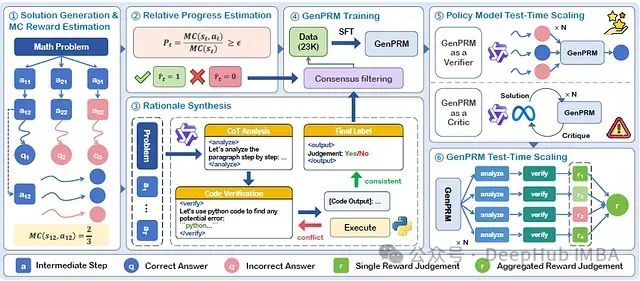
GenPRM:思维链+代码验证,通过生成式推理的过程奖励让大模型推理准确率显著提升
论文提出了GenPRM,一种创新性的生成式过程奖励模型。该模型在评估每个推理步骤前,先执行显式的思维链(Chain-of-Thought, CoT)推理并实施代码验证,从而实现对推理过程的深度理解与评估。
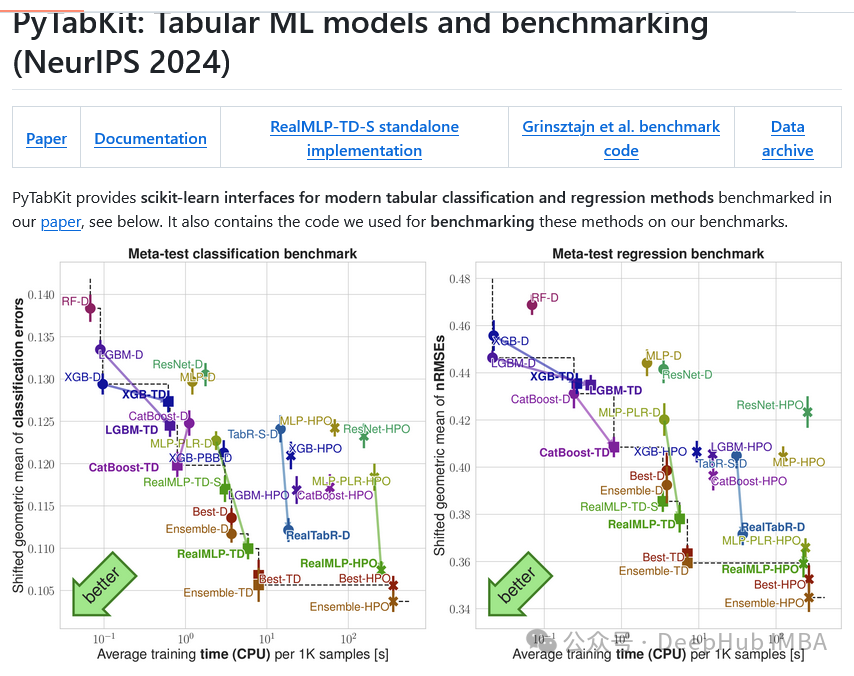
PyTabKit:比sklearn更强大的表格数据机器学习框架
**PyTabKit** 专为表格数据的分类和回归任务设计,集成了 **RealMLP** 等先进技术以及优化的梯度提升决策树(GBDT)超参数配置,为表格数据处理提供了新的技术选择。
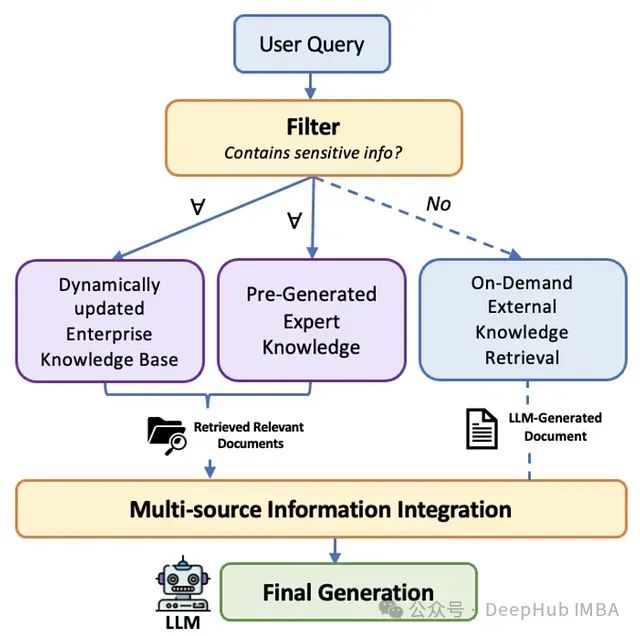
SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过滤机制,为企业提供了一种平衡信息准确性、完整性与数据安全性的RAG解决方案,同时有效控制部署成本。