
在数据驱动分析领域,从复杂流体流动中提取有意义的模式一直是一个重大挑战。稀疏促进动态模态分解(Sparsity Promoting Dynamic Mode Decomposition, SPDMD)提供了一种有效方法,能够揭示最主要的特征,同时去除冗余信息,从而实现更高效和更具洞察力的分解。这种方法将动态模态分解(Dynamic Mode Decomposition, DMD)的数学优雅性与稀疏优化技术相结合,为识别高维数据中的关键结构提供了一个强大的框架。
动态模态分解(DMD)已成为流体动力学数据驱动建模的基石,它提供了一种将复杂的高维流动数据分解为基本时空模态的有力方法。然而,标准DMD方法在处理平移不变性和瞬态现象等方面存在一些局限性。这些局限性突显了将DMD方法扩展到更复杂版本的必要性,这些版本通过调整DMD算法来克服这些局限性。本文将探讨DMD的一个变体——稀疏促进动态模态分解(SPDMD)。
SPDMD的应用
在机器学习和人工智能领域,SPDMD的应用场景广泛。它可用于图像处理和计算机视觉中的特征提取和降维,提高图像压缩和重建的效率。在时间序列分析中,SPDMD可以识别复杂数据中的主要趋势和周期性模式,增强预测模型的性能。对于异常检测任务,SPDMD能够捕捉微妙的异常模式,在工业过程监控和网络安全等领域发挥重要作用。
金融数据分析领域同样受益于SPDMD的强大能力。在股票市场分析中,SPDMD可用于提取价格时间序列的关键特征,识别长期趋势和短期波动。风险评估模型利用SPDMD分析大量金融指标,更准确地预测信用风险。高频交易策略的优化也可借助SPDMD识别市场微观结构中的重要模式。在宏观经济预测方面,SPDMD能够捕捉多个经济指标间的复杂相互作用,提高预测准确性。
此外SPDMD在跨领域应用中也展现出巨大潜力。例如将SPDMD与自然语言处理技术结合,可以更有效地分析金融新闻的情感,为投资决策提供洞见。在新兴的区块链和加密货币领域,SPDMD可用于识别复杂的交易模式和潜在的欺诈活动。
SPDMD的优势
标准DMD通常会生成过多的模态,其中许多是冗余的或受噪声影响严重,这使得准确识别基本流动动力学变得具有挑战性。这种选择性的缺乏可能会模糊重要特征,并使结果的解释变得复杂,特别是在涉及大型数据集或高噪声水平系统的情况下。Jovanovic等人(2014)开发了稀疏促进动态模态分解(SPDMD)来解决这些挑战。通过整合稀疏优化技术,SPDMD能够有选择地只保留最重要的模态,有效地过滤掉不太相关的模态。这提高了分解的清晰度和可解释性,导致对底层物理的更简洁表示。稀疏约束还降低了计算成本,使SPDMD特别适合实时应用和大规模模拟。
SPDMD的核心思想
稀疏促进动态模态分解(SPDMD)的核心思想是如何找到最具代表性的DMD模态来捕捉系统的基本动力学。这个问题看似简单,但实际上比人们最初想象的更为深刻。传统上,动态模态分解(DMD)是由人类专家根据其经验和对数据的理解仔细选择DMD模态来执行的。但当我们希望自动化这个过程,消除人工干预的需求时,SPDMD就发挥了作用。
SPDMD提供了一种自动选择DMD模态的方法,类似于奇异值硬阈值(OSVHT)等方法为奇异值分解(SVD)提供自动化方法。SPDMD利用优化算法重新定义DMD中模态幅度的计算,旨在使用尽可能少的模态重建原始数据集。其目标是提取系统最关键的动力学。术语"稀疏促进"指的是偏好具有最少非零模态的解决方案,专注于最具影响力的动态特征。
SPDMD的数学基础
在经典DMD框架的基础上,SPDMD引入了一个稀疏约束,有选择地识别最重要的动态模态。该过程开始类似于传统DMD:给定流体流动或其他动力系统的一系列快照(时间序列数据),DMD寻求通过将数据分解为空间模态来对数据进行低秩近似,每个空间模态通过特征值表征其时间演化。
SPDMD的创新之处在于使用稀疏促进优化技术,通常包含L1范数正则化项。与传统方法中使用的L2范数不同,L1范数通过惩罚非零条目的数量来鼓励稀疏性。在DMD的背景下,这种方法允许优化算法识别最能代表系统动力学的最小模态子集,最小化不太重要或冗余模态的影响。
DMD模态幅度由以下公式给出:
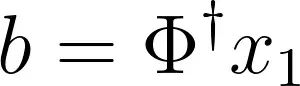
其中,Φ 表示DMD模态,定义为:
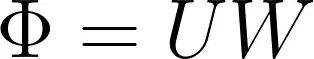
SPDMD的优化问题可以数学表述为:
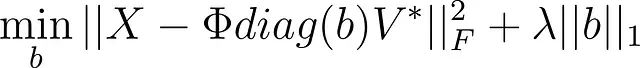
其中:
- X 是包含快照数据的矩阵
- Φ 是DMD模态矩阵
- b 是模态幅度向量
- λ 是控制重建精度和稀疏性平衡的稀疏参数
通过调整参数 λ,SPDMD 决定保留多少模态,实现了对数据更紧凑的表示。随着 λ 的增加,该方法促进了更大的稀疏性,导致选择更少的模态。这产生了一组更清晰和可解释的模态,捕捉系统最主要和物理上最有意义的特征。
为了解决这个优化问题,SPDMD 采用了交替方向乘子法(ADMM)算法。ADMM 对于具有大型数据集、约束或促进稀疏性的正则化项的问题特别有效。它迭代搜索最优的模态幅度向量 b,以最小化成本函数,同时确保向量是稀疏的,只包含很少的非零条目。
实例演示:简单的模型示例
为了说明SPDMD的概念,我们将使用一个简单示例。首先导入必要的Python库:
importmatplotlib.colors
importmatplotlib.pyplotasplt
importnumpyasnp
importpandasaspd
importscipyassp
frommatplotlib.colorsimportListedColormap
importos
importio
%matplotlibinline
plt.rcParams.update({'font.size' : 18, 'font.family' : 'Times New Roman', "text.usetex": True})
savePath='.'
接下来生成一个由三个不同模态和附加噪声组成的示例信号。生成的数据将被去均值化并归一化,以更好地展示SPDMD捕获的动态:
x=np.linspace(-10, 10, 100)
t=np.linspace(0, 20, 200)
Xm, Tm=np.meshgrid(x, t)
M1=5.0/np.cosh(0.5*Xm) *np.tanh(0.5*Xm) *np.exp(1.5j*Tm) # 主要模态
M2=0.5*np.sin(2.0*Xm) *np.exp(2.0j*Tm) # 次要模态
M3=0.5*np.sin(3.2*Xm) *np.cosh(3.2j*Tm) # 三级模态
M4=0.5*np.random.randn(Xm.shape[0], Tm.shape[1]) # 噪声
data_matrix=M1+M2+M3+M4
我们可以使用以下代码可视化三个模态和噪声:
d=0.1
Ub=0.015
fig, axs=plt.subplots(2, 2, figsize=(15, 15))
ax=axs[0,0]
p=ax.contourf(t, x, M1.T, levels=501, cmap='RdBu')
ax.xaxis.set_tick_params(direction='in', which='both')
ax.yaxis.set_tick_params(direction='in', which='both')
ax.xaxis.set_ticks_position('both')
ax.yaxis.set_ticks_position('both')
ax.set_ylabel(r'$x$')
ax.set_xlabel(r'$t$')
ax.set_title('Mode 1')
ax=axs[0,1]
p=ax.contourf(t, x, M2.T, levels=501, cmap='RdBu')
ax.xaxis.set_tick_params(direction='in', which='both')
ax.yaxis.set_tick_params(direction='in', which='both')
ax.xaxis.set_ticks_position('both')
ax.yaxis.set_ticks_position('both')
ax.set_ylabel(r'$x$')
ax.set_xlabel(r'$t$')
ax.set_title('Mode 2')
ax=axs[1,0]
p=ax.contourf(t, x, M3.T, levels=501, cmap='RdBu')
ax.xaxis.set_tick_params(direction='in', which='both')
ax.yaxis.set_tick_params(direction='in', which='both')
ax.xaxis.set_ticks_position('both')
ax.yaxis.set_ticks_position('both')
ax.set_ylabel(r'$x$')
ax.set_xlabel(r'$t$')
ax.set_title('Mode 3')
ax=axs[1,1]
p=ax.contourf(t, x, M4.T, levels=501, cmap='RdBu')
ax.xaxis.set_tick_params(direction='in', which='both')
ax.yaxis.set_tick_params(direction='in', which='both')
ax.xaxis.set_ticks_position('both')
ax.yaxis.set_ticks_position('both')
ax.set_ylabel(r'$x$')
ax.set_xlabel(r'$t$')
ax.set_title('Noise')
plt.show()
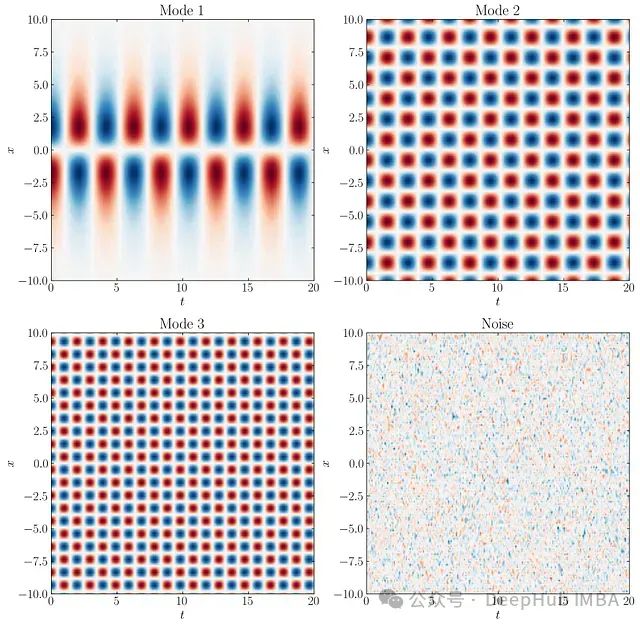
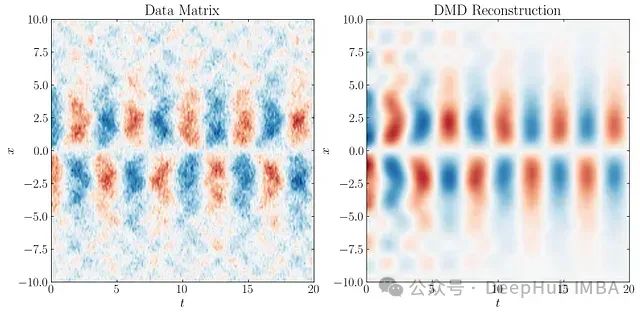
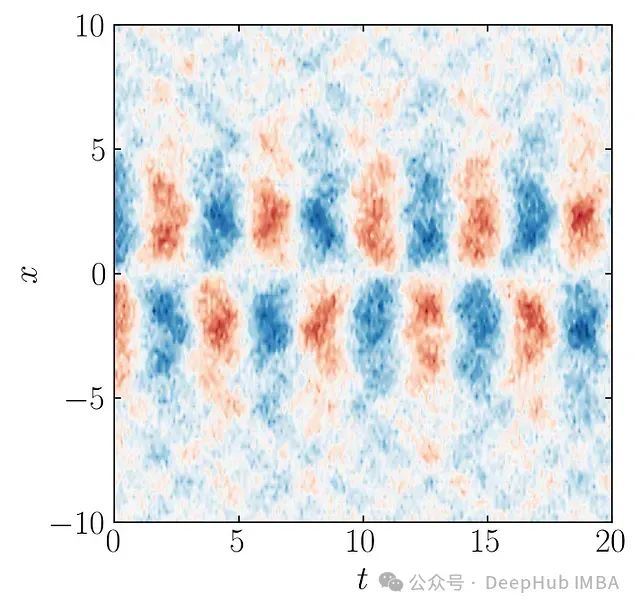
这三个模态与添加的噪声的组合形成了我们将输入到DMD算法中的数据矩阵。该数据矩阵如下所示:
在下一部分中,我们将详细介绍DMD算法的实现和SPDMD的应用。
DMD算法实现
首先实现标准动态模态分解(DMD)算法。以下是Python实现:
defDMD(X1, X2, r, dt):
U, s, Vh=np.linalg.svd(X1, full_matrices=False)
# 截断SVD矩阵
Ur=U[:, :r]
Sr=np.diag(s[:r])
Vr=Vh.conj().T[:, :r]
# 构建Atilde并计算其特征值和特征向量
Atilde=Ur.conj().T@X2@[email protected](Sr)
Lambda, W=np.linalg.eig(Atilde)
# 计算DMD模态
Phi=X2@[email protected](Sr) @W
omega=np.log(Lambda)/dt # 连续时间特征值
# 计算幅度
alpha1=np.linalg.lstsq(Phi, X1[:, 0], rcond=None)[0] # DMD模态幅度
b=np.linalg.lstsq(Phi, X2[:, 0], rcond=None)[0] # DMD模态幅度
returnPhi, omega, Lambda, alpha1, b
将数据矩阵传入上述DMD算法:
# 时间移位快照矩阵
X1=data_matrix.T[:, :-1]
X2=data_matrix.T[:, 1:]
r=30 # 截断的秩
dt=t[1] -t[0]
# 执行DMD
Phi, omega, Lambda, alpha1, b=DMD(X1, X2, r, dt)
DMD重构
DMD工作流程的下一步是重构表示系统时间演化的矩阵。计算时间动态并获得DMD重构。系统在x_0处的初始条件用于创建时间演化矩阵,可以使用一个利用范德蒙德矩阵的替代公式:
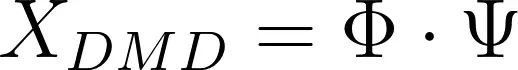
其中V_mu是范德蒙德矩阵,†符号表示矩阵的Moore-Penrose伪逆。
实现代码如下:
# 计算时间演化
Vand=np.vander(Lambda, len(t), True)
Psi= (Vand.T*b).T # 等价于 Psi = dot(diag(b), Vand)
# 重构数据
D_dmd=np.dot(Phi, Psi)
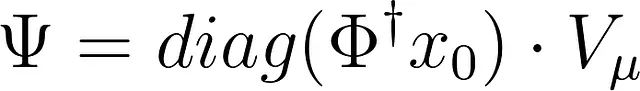
SPDMD优化问题
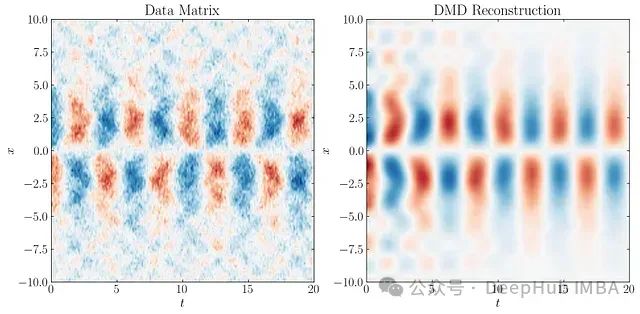
SPDMD的关键在于重新定义DMD模态幅度的计算方法。传统上幅度向量b定义为:
但是我们可以通过最小化重构误差来选择b,从而产生更接近原始数据的时间演化。SPDMD通过最小化以下目标函数来重新定义DMD模态幅度:
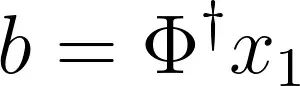
利用矩阵迹的性质可以简化第一项,如Jovanovic等人(2014)所述:
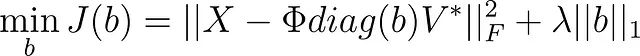
其中:
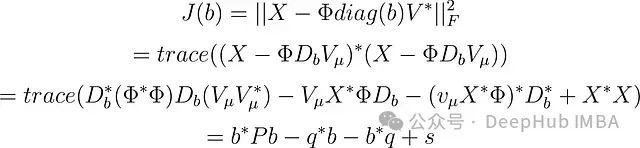
为了促进向量b的稀疏性,可以引入了L1惩罚项。这个惩罚项的目的是鼓励b向量稀疏只包含很少的非零条目。
ADMM算法实现
使用交替方向乘子法(ADMM)算法来解决这个优化问题。以下是ADMM算法的Python实现,这是Jovanovic等人(2014)MATLAB代码的直接翻译:
fromnumpyimportdot, multiply, diag
fromnumpy.linalgimportinv, eig, pinv, norm, solve, cholesky
fromscipy.linalgimportsvd, svdvals
fromscipy.sparseimportcsc_matrixassparse
fromscipy.sparseimportvstackasspvstack
fromscipy.sparseimporthstackassphstack
fromscipy.sparse.linalgimportspsolve
defadmm_for_dmd(P, q, s, gamma_vec, rho=1, maxiter=1000, eps_abs=1e-6, eps_rel=1e-4):
# 初始化返回值对象
answer=type('ADMMAnswer', (object,), {})()
# 输入验证
P=np.squeeze(P)
q=np.squeeze(q)[:,np.newaxis]
gamma_vec=np.squeeze(gamma_vec)
ifP.ndim!=2:
raiseValueError('invalid P')
ifq.ndim!=2:
raiseValueError('invalid q')
ifgamma_vec.ndim!=1:
raiseValueError('invalid gamma_vec')
# 优化变量的数量
n=len(q)
# 单位矩阵
I=np.eye(n)
# 为依赖于gamma的输出变量分配内存
answer.gamma=gamma_vec
answer.Nz =np.zeros([len(gamma_vec),]) # 非零幅度的数量
answer.Jsp =np.zeros([len(gamma_vec),]) # Frobenius范数的平方(抛光前)
answer.Jpol =np.zeros([len(gamma_vec),]) # Frobenius范数的平方(抛光后)
answer.Ploss=np.zeros([len(gamma_vec),]) # 最优性能损失(抛光后)
answer.xsp =np.zeros([n, len(gamma_vec)], dtype='complex') # 幅度向量(抛光前)
answer.xpol =np.zeros([n, len(gamma_vec)], dtype='complex') # 幅度向量(抛光后)
# 矩阵P + (rho/2)*I的Cholesky分解
Prho=P+ (rho/2) *I
Plow=cholesky(Prho)
Plow_star=Plow.conj().T
# 稀疏P(用于KKT系统)
Psparse=sparse(P)
fori, gammainenumerate(gamma_vec):
# 初始条件
y=np.zeros([n, 1], dtype='complex') # 拉格朗日乘子
z=np.zeros([n, 1], dtype='complex') # x的副本
# 使用ADMM求解gamma参数化问题
forstepinrange(maxiter):
# x-最小化步骤
u=z- (1/rho) *y
xnew=solve(Plow_star, solve(Plow, q+ (rho/2) *u))
# z-最小化步骤
a= (gamma/rho) *np.ones([n, 1])
v=xnew+ (1/rho) *y
# v的软阈值处理
znew=multiply(multiply(np.divide(1-a, np.abs(v)), v), (np.abs(v) >a))
# 原始和对偶残差
res_prim=norm(xnew-znew, 2)
res_dual=rho*norm(znew-z, 2)
# 拉格朗日乘子更新步骤
y+=rho* (xnew-znew)
# 停止准则
eps_prim=np.sqrt(n) *eps_abs+eps_rel*np.max([norm(xnew, 2), norm(znew, 2)])
eps_dual=np.sqrt(n) *eps_abs+eps_rel*norm(y, 2)
if (res_prim<eps_prim) and (res_dual<eps_dual):
break
else:
z=znew
# 记录输出数据
answer.xsp[:,i] =z.squeeze() # 幅度向量
answer.Nz[i] =np.count_nonzero(answer.xsp[:,i]) # 非零幅度的数量
answer.Jsp[i] = (
np.real(dot(dot(z.conj().T, P), z))
-2*np.real(dot(q.conj().T, z))
+s) # Frobenius范数(抛光前)
# 非零幅度的抛光
# 形成约束矩阵E,使得E^T x = 0
ind_zero=np.flatnonzero(np.abs(z) <1e-12) # 找到z的零元素的索引
m=len(ind_zero) # 零元素的数量
ifm>0:
# 形成最优条件的KKT系统
E=I[:,ind_zero]
E=sparse(E, dtype='complex')
KKT=spvstack([
sphstack([Psparse, E], format='csc'),
sphstack([E.conj().T, sparse((m, m), dtype='complex')], format='csc'),
], format='csc')
rhs=np.vstack([q, np.zeros([m, 1], dtype='complex')]) # 垂直堆叠
# 求解KKT系统
sol=spsolve(KKT, rhs)
else:
sol=solve(P, q)
# 抛光后(最优)的幅度向量
xpol=sol[:n]
# 记录输出数据
answer.xpol[:,i] =xpol.squeeze()
# 抛光后(最优)的最小二乘残差
answer.Jpol[i] = (
np.real(dot(dot(xpol.conj().T, P), xpol))
-2*np.real(dot(q.conj().T, xpol))
+s)
# 抛光后(最优)的性能损失
answer.Ploss[i] =100*np.sqrt(answer.Jpol[i]/s)
print(i)
returnanswer
SPDMD应用
为了应用SPDMD,首先需要执行奇异值分解(SVD)并计算必要的矩阵P、q和s:
U, s, Vh=np.linalg.svd(data_matrix.T, full_matrices=False)
Vand=np.vander(Lambda, len(t), True)
P=multiply(dot(Phi.conj().T, Phi), np.conj(dot(Vand, Vand.conj().T)))
q=np.conj(diag(dot(dot(Vand, (dot(dot(U, diag(s)), Vh)).conj().T), Phi)))
s=norm(diag(s), ord='fro')**2
然后定义一个γ值的范围来检查它们对最优b向量的影响:
gamma_vec=np.logspace(np.log10(0.05), np.log10(200), 150)
最后使用ADMM算法求解优化问题:
bNew=admm_for_dmd(P, q, s, gamma_vec, rho=1, maxiter=1000, eps_abs=1e-6, eps_rel=1e-4)
结果分析
完成优化后,我们可以探索
bNew
对象,该对象包含了SPDMD的结果。可以使用以下命令获取可用的属性:
dir(bNew)
### 输出
# ['Jpol', 'Jsp', 'Nz', 'Ploss', 'gamma', 'xpol', 'xsp']
这里:
Nz表示解中非零模态的数量PLoss表示性能损失 - 一个归一化的度量,反映了使用最优b导致的整体模型误差xpol包含对应于特定gamma值的最优b的值
例如,当γ = 0.073时,我们在最优b向量中获得30个非零元素。使用这个最优b重构DMD降阶模型得到以下结果:
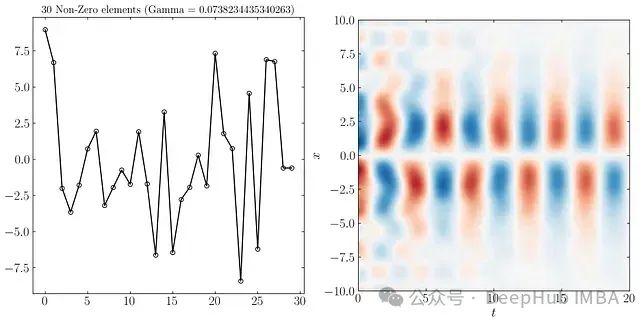
同样可以只使用9个、3个和2个最重要的DMD模态重构系统动态,如下所示:
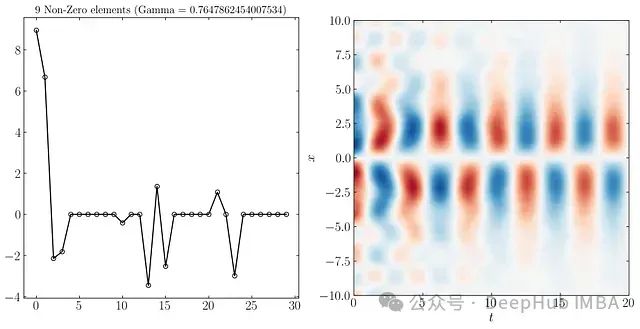
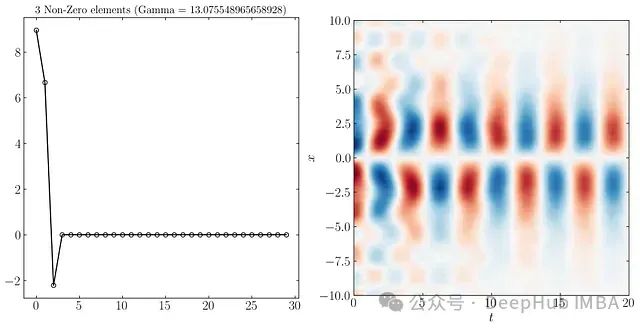
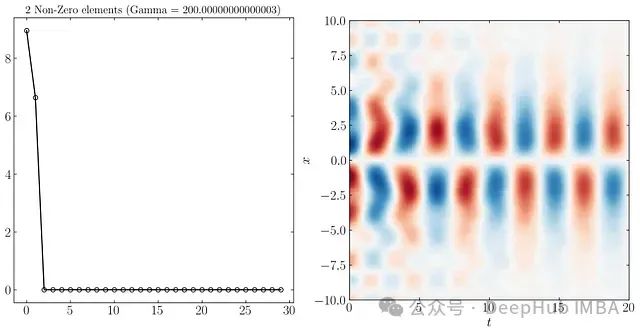
在更高的分辨率下,由于噪声水平的不同,前三个模态更容易区分。SPDMD允许仅使用单个模态进行重构 - 最主要的模态,有效地捕捉了系统的整体动态。
结论
SPDMD的强大之处在于其能够有选择地保留最主要的模态,同时促进稀疏性。这种方法确保重构的模型保持紧凑,同时代表系统的基本动态。通过自动选择最相关的模态,SPDMD提供了一种强大的工具来分析复杂的动力系统,特别是在处理大规模数据集和实时应用时。
PCA和DMD都是数据降维方法,两者在本质上相同,只不过后者是用来处理动力系统数据的,相比主成分分析,动态模态分解给出的“模态”,相比主成分分析中的“特征向量”,一般有更强的可解释性(具有一定的物理意义)。所以DMD不仅提高了数据分析的效率,还为相关领域的研究和实践提供了新的工具和视角。