Mindspore体验dcgan生成漫画头像
在第一篇中我们实现了昇思平台的安装与初体验,这一次我们可以进行对它深入的了解与尝试。想要了解安装部署的同学请去看我的第一篇哈。本文对通过昇思框架实现对抗神经网络实现动漫头像识别以及会遇到的问题进行了简单的介绍。最后自己生成的动漫头像也是非常的有意义,值得一试。欢迎大家加入昇思社区,一起讨论昇思框架的
【OpenCV】 人脸识别
C++ 版 OpenCV 人脸识别案例 步骤详解教程
高级人工智能(国科大2021-2022秋季学期课程)-基础概念及算法
高级人工智能-沈华伟-国科大2021-2022秋季学期课程
【OpenCV 例程 300篇】251. 特征匹配之暴力匹配
基于特征描述符的特征点匹配是通过对两幅图像的特征点集合内的关键点描述符的相似性比对来实现的。暴力匹配(Brute-force matcher)是最简单的二维特征点匹配方法。在OpenCV中提供了cv::BFMatcher类实现暴力匹配。
国科大.高级人工智能.期末复习笔记手稿+复习大纲
写在最前这是博主复习《高级人工智能》这门课程时的手稿。2021-2022年秋季学期的考试真题可以参考这篇文章。本文基本覆盖了这门课程的所有知识点,认真复习的话90分以上没有什么问题,如果有哪里的字体难以辨认,请评论区留言。另外,需要历年考试真题的同学可以在评论区留言,祝考试顺利!归结原理完备性证明:

从视频到音频:使用VIT进行音频分类
在本文中,我们将利用ViT - Vision Transformer的是一个Pytorch实现在音频分类数据集GTZAN数据集-音乐类型分类上训练它。
ubuntu18.04安装cuda和cudnn
一、安装 cuda1. 首先查看自身电脑最高支持的cuda版本为多少,在终端输入以下指令nvidia-smi可以看到我的最高支持 cuda 11.4 。2. 打开英伟达官网 下载官方cuda此处我下载的是cuda 11.0.3 版本,并选择相应配置,复制指令至终端下载3. 运行官网安装指令4. 依次
国科大.模式识别与机器学习.期末复习笔记手稿+复习大纲
这是博主复习《模式识别与机器学习》这门课程时的手稿。本文基本覆盖了这门课程的所有知识点,认真复习的话90分以上没有什么问题,如果有哪里的字体难以辨认,请评论区留言。
寒假本科创新学习——机器学习(一)
机器学习的概念、基本术语
2022数模国赛C题思路解析(可供训练用 源码可供参考)
2022数模国赛C题思路解析 有代码和论文 可供参考和训练用
Python中的时间序列数据操作总结
在本文中,我们介绍时间序列数据的索引和切片、重新采样和滚动窗口计算以及其他有用的常见操作,这些都是使用Pandas操作时间序列数据的关键技术。
【Android App】人脸识别中借助摄像头和OpenCV实时检测人脸讲解及实战(附源码和演示 超详细)
【Android App】人脸识别中借助摄像头和OpenCV实时检测人脸讲解及实战(附源码和演示 超详细)
猿创征文|【Python数据科学快速入门系列 | 05】常用科学计算函数
本文以鸢尾花的数据预处理为例,描述了科学计算在机器学习使用的示例。
Python进阶——网课不愁系列AI换脸技术
AI换脸,网课期间你就是最靓的崽
ChatGPT 体验和思考
ChatGPT 体验和思考
ChatGPT:构建与人类聊天一样自然的机器人
ChatGPT:构建与人类聊天一样自然的机器人
one-hot编码
one-hot编码,又称独热编码、一位有效编码。one hot在特征提取上属于词袋模型(bag of words)优缺点分析优点:- 一是解决了分类器不好处理离散数据的问题- 二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)缺点:- 它是一个词袋模型,不考虑词与词之间的顺序-
【Android App】人脸识别中使用Opencv比较两张人脸相似程度实战(附源码和演示 超详细)
【Android App】人脸识别中使用Opencv比较两张人脸相似程度实战(附源码和演示 超详细)
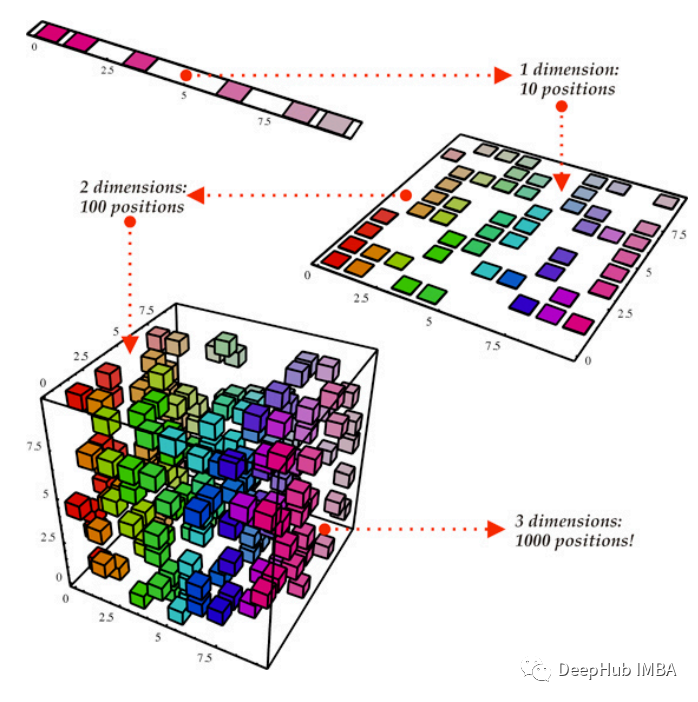
常见的降维技术比较:能否在不丢失信息的情况下降低数据维度
本文将比较各种降维技术在机器学习任务中对表格数据的有效性。
改进YOLOv5 | 头部解耦 | 将YOLOX解耦头添加到YOLOv5 | 涨点杀器
在目标检测中,分类任务和回归任务之间的冲突是一个众所周知的问题。因此...



