【NLP】NLP基础知识
目录自然语言处理主要内容自然语言的构成自然语言处理的步骤1:词法分析1 分词:2 实体识别3 实体识别方法:序列标注4 序列标注关键算法:5 序列标注应用:5.1 新词发现:5.2 领域中文分词5.3 命名实体识别5.4 依存句法分析(帮助句法分析)自然语言处理的步骤2:句法分析1 主题
逻辑回归(Logistic Regression)原理及其应用
本内容主要从逻辑回归应用场景、逻辑回归原理、逻辑回归应用案例,主要是癌症分类预测,还有分类评估方法,主要包含精确率、召回率、F1-score、AUC曲线和ROC指标。
如何在亚马逊 SageMaker 进行 Stable Diffusion 模型在线服务部署
最近以AIGC带来巨大生产力提升的时尚宠儿不断进化升级,争相亮相。我们迎来ChatGPT 系列技术带给我们一波又一波的AI盛宴,而在计算机视觉领域,AI 绘画近两年正在逐渐走向图像生成舞台的中央。最近受邀参加了亚马逊云科技 『云上探索实验室』实践云上技术的系列活动,通过Amazon SageMake
【Flink】详解Flink的八种分区
本文详细介绍乐Flink中分区API以及底层分区器并给出图例,从源码角度分析各个分区器的原理,最后介绍了分区器的使用源码。
YOLO系列 --- YOLOV7算法(三):YOLO V7算法train.py代码解析
YOLO系列 --- YOLOV7算法(三):YOLO V7算法train.py代码解析
Pytroch进行模型权重初始化
Pytroch常见的模型参数初始化方法有apply和model.modules()。Pytroch会自动给模型进行初始化,当需要自己定义模型初始化时才需要这两个方法。
windows10操作系统 显卡MX150 安装CUDA+cuDNN+pytorch
windows10操作系统 显卡MX150 安装CUDA+cuDNN+pytorch
【Unity】AI实战应用——Unity接入ChatGPT和对游戏开发实际应用的展望
同事朋友们都在恐慌AI的发展,甚至有不少人开始抗拒。我的观点是:人工智能是大势所趋,势不可挡,那就驾驭它吧!我司已经在商业项目中实际使用了AI, 包括Stable Diffusion及其扩展插件,当然也有爆火的ChatGPT。Stable Diffusion + ControlNET + Lora以
Educode--机器学习基础模型与算法测试闯关实验
第1关:线性回归模型应用实现代码:#-*-coding:utf-8-*-'''油气藏的储量密度Y与生油门限以下平均地温梯度X1、生油门限以下总有机碳百分比X2、生油岩体积与沉积岩体积百分比X3、砂泥岩厚度百分比X4、有机转化率X5有关,数据文件为“1.xlsx”,字段如下:样本IDX1X2X3X4X
Cursor太强了,从零开始写ChatGLM大模型的微调代码
初试基于chatgpt4的写代码神器
yoloV5模型中,x,s,n,m,l分别有什么不同
YOLOv5 的不同变体(如 YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 和 YOLOv5n)表示不同大小和复杂性的模型。这些变体在速度和准确度之间提供了不同的权衡,以适应不同的计算能力和实时性需求。适用于需要极高准确度的任务,且具有强大计算能力(如 GPU)的设备。YOLOv5
可分离卷积(Separable convolution)详解
可分离卷积包括空间可分离卷积(Spatially Separable Convolutions)和深度可分离卷积(depthwise separable convolution)。
详解可变形注意力模块(Deformable Attention Module)
Deformable Attention(可变形注意力)首先在2020年10月初商汤研究院的《Deformable DETR: Deformable Transformers for End-to-End Object Detection》论文中提出,在2022CVPR中《Vision Transf
编程工具-GPT来AI编程代码
1、下载安装,重要的说三遍(目前免费!免费!免费!),支持多平台 Mac / Windows / Linux,亲测可用,Cursor 是一个基于人工智能技术的代码生成器,它可以根据程序员输入的代码上下文和要实现的功能,自动生成相应的代码。2、支持语言:默认打开后有两个文件js文件和python文件,
Pytorch 深度学习注意力机制的解析与代码实现
深度学习Attention注意力机制的解析及其Pytorch代码实现
踩雷日记:Pytorch mmcv-full简易安装
因为mmcv-full版本与pytorch和cuda版本不匹配,导致mmcv-full安装失败。提示:安装mmcv-full前,先把mmcv卸掉例如:以上就是今天要讲的内容,本文简单介绍了mmcv-full的安装,希望对你有所帮助。
【深度学习】详解 MAE
【深度学习】详解 MAE - Masked Autoencoders Are Scalable Vision Learners
Pycharm+qt-tools搭建界面实现界面交互
Pycharm+qt-tools搭建界面实现界面交互
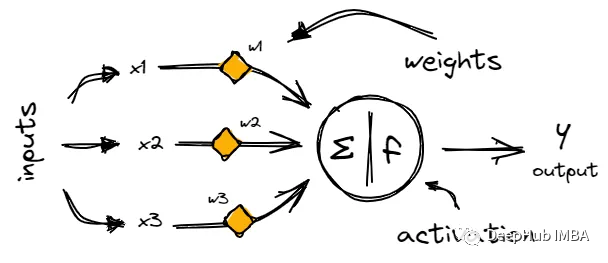
神经网络初学者的激活函数指南
如果你刚刚开始学习神经网络,激活函数的原理一开始可能很难理解。但是如果你想开发强大的神经网络,理解它们是很重要的。
IEEE Transactions模板中参考文献作者缩写、期刊名缩写
本文章记录如何在IEEE Transactions的模板中,解决参考文献的作者缩写、期刊名字缩写的问题。



