
一. Openpcdet的安装以及使用
- Openpcdet详细内容请看以下链接:
GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.
1.首先gitclone原文代码
- 这里我建议自己按照作者github上的docs/install文件夹下指示一步步安装,(之前根据csdn上教程一直有报错),然后下载spconv,以及cumm, github链接如下:
GitHub - traveller59/spconv: Spatial Sparse Convolution Library
GitHub - FindDefinition/cumm: CUda Matrix Multiply library.
打开spconv中的readme,并且严格按照readme步骤安装,一般需要编译一段时间。
打开cumm中readme,严格按照上面指示安装。
安装完成之后按照测试数据跑通检验一下。
二. Openpcdet训练自己的数据集
本人移植其他的数据集,由于我有自己的image数据,已经按照kitti数据集的格式转换为velodyne, calib, label, image四个文件,并且实现了评估,以及最终的检测结果,所以可能和其他博主不一样。
如果你只有velodyne,label,或者数据集格式还不知道如何转换,文件建议参考以下这几个博主的链接:
Training using our own dataset · Issue #771 · open-mmlab/OpenPCDet · GitHub
OpenPCDet 训练自己的数据集详细教程!_JulyLi2019的博客-CSDN博客_openpcdet 数据集
3D目标检测(4):OpenPCDet训练篇--自定义数据集 - 知乎
Openpcdet-(2)自数据集训练数据集训练_花花花哇_的博客-CSDN博客
win10 OpenPCDet 训练KITTI以及自己的数据集_树和猫的博客-CSDN博客_openpcdet训练
这里首先总结以下主要涉及到以下三个文件的修改
*** pcdet/datasets/custom/custom_dataset.py**
*** tools/cfgs/custom_models/pointpillar.yaml (也可以是其他模型)**
*** tools/cfgs/dataset_configs/custom_dataset.yaml**
*** demo.py**
1.pcdet/datasets/custom/custom_dataset.py
其实custom_dataset.py只需要大家去模仿kitti_dataset.py去删改就可以了,而且大部分内容不需要用户修改,这里我修改了:
1)get_lidar函数
- 获取激光雷达数据,其他的get_image也类似
2) __getitem__函数
这个函数最重要,是获取数据字典并更新的关键
如果有些字典不需要可以删改,如calib,image等
3)get_infos函数
- 生成字典信息infos
infos={'image':xxx,
'calib': xxx,
'annos': xxx}
annos = {'name': xxx,
'truncated': xxx,
'alpha':xxx,
.............}
其中annos就是解析你的label文件生成的字典, 如类别名,是否被遮挡,bbox的角度
同理有些字典信息不需要可以增删
- create_custom_infos函数
这个函数主要用来生成你的数据字典,一般以.pkl后缀,如果你不需要评估,可以将其中的评估部分删除,原理也很简单。
- main函数中的类别信息
修改后的代码如下:
import copy
import pickle
import os
from skimage import io
import numpy as np
from ..kitti import kitti_utils
from ...ops.roiaware_pool3d import roiaware_pool3d_utils
from ...utils import box_utils, common_utils, calibration_kitti, object3d_custom
from ..dataset import DatasetTemplate
class CustomDataset(DatasetTemplate):
def __init__(self, dataset_cfg, class_names, training=True, root_path=None, logger=None, ext='.bin'):
"""
Args:
root_path:
dataset_cfg:
class_names:
training:
logger:
"""
super().__init__(
dataset_cfg=dataset_cfg, class_names=class_names, training=training, root_path=root_path, logger=logger
)
self.split = self.dataset_cfg.DATA_SPLIT[self.mode]
self.root_split_path = self.root_path / ('training' if self.split != 'test' else 'testing')
split_dir = os.path.join(self.root_path, 'ImageSets', (self.split + '.txt')) # custom/ImagSets/xxx.txt
self.sample_id_list = [x.strip() for x in open(split_dir).readlines()] if os.path.exists(split_dir) else None # xxx.txt内的内容
self.custom_infos = []
self.include_data(self.mode) # train/val
self.map_class_to_kitti = self.dataset_cfg.MAP_CLASS_TO_KITTI
self.ext = ext
def include_data(self, mode):
self.logger.info('Loading Custom dataset.')
custom_infos = []
for info_path in self.dataset_cfg.INFO_PATH[mode]:
info_path = self.root_path / info_path
if not info_path.exists():
continue
with open(info_path, 'rb') as f:
infos = pickle.load(f)
def get_label(self, idx):
label_file = self.root_split_path / 'label_2' / ('%s.txt' % idx)
assert label_file.exists()
return object3d_custom.get_objects_from_label(label_file)
def get_lidar(self, idx, getitem=True):
if getitem == True:
lidar_file = self.root_split_path + '/velodyne/' + ('%s.bin' % idx)
else:
lidar_file = self.root_split_path / 'velodyne' / ('%s.bin' % idx)
return np.fromfile(str(lidar_file), dtype=np.float32).reshape(-1, 4)
def get_image(self, idx):
"""
Loads image for a sample
Args:
idx: int, Sample index
Returns:
image: (H, W, 3), RGB Image
"""
img_file = self.root_split_path / 'image_2' / ('%s.png' % idx)
assert img_file.exists()
image = io.imread(img_file)
image = image.astype(np.float32)
image /= 255.0
return image
def get_image_shape(self, idx):
img_file = self.root_split_path / 'image_2' / ('%s.png' % idx)
assert img_file.exists()
return np.array(io.imread(img_file).shape[:2], dtype=np.int32)
def get_fov_flag(self, pts_rect, img_shape, calib):
"""
Args:
pts_rect:
img_shape:
calib:
Returns:
"""
pts_img, pts_rect_depth = calib.rect_to_img(pts_rect)
val_flag_1 = np.logical_and(pts_img[:, 0] >= 0, pts_img[:, 0] < img_shape[1])
val_flag_2 = np.logical_and(pts_img[:, 1] >= 0, pts_img[:, 1] < img_shape[0])
val_flag_merge = np.logical_and(val_flag_1, val_flag_2)
pts_valid_flag = np.logical_and(val_flag_merge, pts_rect_depth >= 0)
return pts_valid_flag
def set_split(self, split):
super().__init__(
dataset_cfg=self.dataset_cfg, class_names=self.class_names, training=self.training,
root_path=self.root_path, logger=self.logger
)
self.split = split
split_dir = self.root_path / 'ImageSets' / (self.split + '.txt')
self.sample_id_list = [x.strip() for x in open(split_dir).readlines()] if split_dir.exists() else None
custom_infos.extend(infos)
self.custom_infos.extend(custom_infos)
self.logger.info('Total samples for CUSTOM dataset: %d' % (len(custom_infos)))
def __len__(self):
if self._merge_all_iters_to_one_epoch:
return len(self.sample_id_list) * self.total_epochs
return len(self.custom_infos)
def __getitem__(self, index):
if self._merge_all_iters_to_one_epoch:
index = index % len(self.custom_infos)
info = copy.deepcopy(self.custom_infos[index])
sample_idx = info['point_cloud']['lidar_idx']
img_shape = info['image']['image_shape']
calib = self.get_calib(sample_idx)
get_item_list = self.dataset_cfg.get('GET_ITEM_LIST', ['points'])
input_dict = {
'frame_id': self.sample_id_list[index],
'calib': calib,
}
# 如果annos标签存在info的字典里
if 'annos' in info:
annos = info['annos']
annos = common_utils.drop_info_with_name(annos, name='DontCare')
loc, dims, rots = annos['location'], annos['dimensions'], annos['rotation_y']
gt_names = annos['name']
gt_boxes_camera = np.concatenate([loc, dims, rots[..., np.newaxis]], axis=1).astype(np.float32)
gt_boxes_lidar = box_utils.boxes3d_kitti_camera_to_lidar(gt_boxes_camera, calib)
# 更新gtbox
input_dict.update({
'gt_names': gt_names,
'gt_boxes': gt_boxes_lidar
})
if "gt_boxes2d" in get_item_list:
input_dict['gt_boxes2d'] = annos["bbox"]
# 获取fov视角的points
if "points" in get_item_list:
points = self.get_lidar(sample_idx, False)
if self.dataset_cfg.FOV_POINTS_ONLY:
pts_rect = calib.lidar_to_rect(points[:, 0:3])
fov_flag = self.get_fov_flag(pts_rect, img_shape, calib)
points = points[fov_flag]
input_dict['points'] = points
input_dict['calib'] = calib
data_dict = self.prepare_data(data_dict=input_dict)
data_dict['image_shape'] = img_shape
return data_dict
def evaluation(self, det_annos, class_names, **kwargs):
if 'annos' not in self.custom_infos[0].keys():
return 'No ground-truth boxes for evaluation', {}
def kitti_eval(eval_det_annos, eval_gt_annos, map_name_to_kitti):
from ..kitti.kitti_object_eval_python import eval as kitti_eval
from ..kitti import kitti_utils
kitti_utils.transform_annotations_to_kitti_format(eval_det_annos, map_name_to_kitti=map_name_to_kitti)
kitti_utils.transform_annotations_to_kitti_format(
eval_gt_annos, map_name_to_kitti=map_name_to_kitti,
info_with_fakelidar=self.dataset_cfg.get('INFO_WITH_FAKELIDAR', False)
)
kitti_class_names = [map_name_to_kitti[x] for x in class_names]
ap_result_str, ap_dict = kitti_eval.get_official_eval_result(
gt_annos=eval_gt_annos, dt_annos=eval_det_annos, current_classes=kitti_class_names
)
return ap_result_str, ap_dict
eval_det_annos = copy.deepcopy(det_annos)
eval_gt_annos = [copy.deepcopy(info['annos']) for info in self.custom_infos]
if kwargs['eval_metric'] == 'kitti':
ap_result_str, ap_dict = kitti_eval(eval_det_annos, eval_gt_annos, self.map_class_to_kitti)
else:
raise NotImplementedError
return ap_result_str, ap_dict
def get_calib(self, idx):
calib_file = self.root_split_path / 'calib' / ('%s.txt' % idx)
assert calib_file.exists()
return calibration_kitti.Calibration(calib_file)
def get_infos(self, num_workers=4, has_label=True, count_inside_pts=True, sample_id_list=None):
import concurrent.futures as futures
def process_single_scene(sample_idx):
# 生成point_cloud字典
print('%s sample_idx: %s' % (self.split, sample_idx))
info = {}
pc_info = {'num_features': 4, 'lidar_idx': sample_idx}
info['point_cloud'] = pc_info
# 生成image字典
image_info = {'image_idx': sample_idx, 'image_shape': self.get_image_shape(sample_idx)}
info['image'] = image_info
# 生成calib字典
calib = self.get_calib(sample_idx)
P2 = np.concatenate([calib.P2, np.array([[0., 0., 0., 1.]])], axis=0)
R0_4x4 = np.zeros([4, 4], dtype=calib.R0.dtype)
R0_4x4[3, 3] = 1.
R0_4x4[:3, :3] = calib.R0
V2C_4x4 = np.concatenate([calib.V2C, np.array([[0., 0., 0., 1.]])], axis=0)
calib_info = {'P2': P2, 'R0_rect': R0_4x4, 'Tr_velo_to_cam': V2C_4x4}
info['calib'] = calib_info
if has_label:
# 生成annos字典
obj_list = self.get_label(sample_idx)
annotations = {}
annotations['name'] = np.array([obj.cls_type for obj in obj_list])
annotations['truncated'] = np.array([obj.truncation for obj in obj_list])
annotations['occluded'] = np.array([obj.occlusion for obj in obj_list])
annotations['alpha'] = np.array([obj.alpha for obj in obj_list])
annotations['bbox'] = np.concatenate([obj.box2d.reshape(1, 4) for obj in obj_list], axis=0)
annotations['dimensions'] = np.array([[obj.l, obj.h, obj.w] for obj in obj_list]) # lhw(camera) format
annotations['location'] = np.concatenate([obj.loc.reshape(1, 3) for obj in obj_list], axis=0)
annotations['rotation_y'] = np.array([obj.ry for obj in obj_list])
annotations['score'] = np.array([obj.score for obj in obj_list])
annotations['difficulty'] = np.array([obj.level for obj in obj_list], np.int32)
num_objects = len([obj.cls_type for obj in obj_list if obj.cls_type != 'DontCare'])
num_gt = len(annotations['name'])
index = list(range(num_objects)) + [-1] * (num_gt - num_objects)
annotations['index'] = np.array(index, dtype=np.int32)
loc = annotations['location'][:num_objects]
dims = annotations['dimensions'][:num_objects]
rots = annotations['rotation_y'][:num_objects]
loc_lidar = calib.rect_to_lidar(loc)
l, h, w = dims[:, 0:1], dims[:, 1:2], dims[:, 2:3]
loc_lidar[:, 2] += h[:, 0] / 2
gt_boxes_lidar = np.concatenate([loc_lidar, l, w, h, -(np.pi / 2 + rots[..., np.newaxis])], axis=1)
annotations['gt_boxes_lidar'] = gt_boxes_lidar
info['annos'] = annotations
if count_inside_pts:
points = self.get_lidar(sample_idx, False)
calib = self.get_calib(sample_idx)
pts_rect = calib.lidar_to_rect(points[:, 0:3])
fov_flag = self.get_fov_flag(pts_rect, info['image']['image_shape'], calib)
pts_fov = points[fov_flag]
corners_lidar = box_utils.boxes_to_corners_3d(gt_boxes_lidar)
num_points_in_gt = -np.ones(num_gt, dtype=np.int32)
for k in range(num_objects):
flag = box_utils.in_hull(pts_fov[:, 0:3], corners_lidar[k])
num_points_in_gt[k] = flag.sum()
annotations['num_points_in_gt'] = num_points_in_gt
return info
sample_id_list = sample_id_list if sample_id_list is not None else self.sample_id_list
with futures.ThreadPoolExecutor(num_workers) as executor:
infos = executor.map(process_single_scene, sample_id_list)
return list(infos)
def create_groundtruth_database(self, info_path=None, used_classes=None, split='train'):
import torch
database_save_path = Path(self.root_path) / ('gt_database' if split == 'train' else ('gt_database_%s' % split))
db_info_save_path = Path(self.root_path) / ('custom_dbinfos_%s.pkl' % split)
database_save_path.mkdir(parents=True, exist_ok=True)
all_db_infos = {}
with open(info_path, 'rb') as f:
infos = pickle.load(f)
for k in range(len(infos)):
print('gt_database sample: %d/%d' % (k + 1, len(infos)))
info = infos[k]
sample_idx = info['point_cloud']['lidar_idx']
points = self.get_lidar(sample_idx, False)
annos = info['annos']
names = annos['name']
difficulty = annos['difficulty']
bbox = annos['bbox']
gt_boxes = annos['gt_boxes_lidar']
num_obj = gt_boxes.shape[0]
point_indices = roiaware_pool3d_utils.points_in_boxes_cpu(
torch.from_numpy(points[:, 0:3]), torch.from_numpy(gt_boxes)
).numpy() # (nboxes, npoints)
for i in range(num_obj):
filename = '%s_%s_%d.bin' % (sample_idx, names[i], i)
filepath = database_save_path / filename
gt_points = points[point_indices[i] > 0]
gt_points[:, :3] -= gt_boxes[i, :3]
with open(filepath, 'w') as f:
gt_points.tofile(f)
if (used_classes is None) or names[i] in used_classes:
db_path = str(filepath.relative_to(self.root_path)) # gt_database/xxxxx.bin
db_info = {'name': names[i], 'path': db_path, 'image_idx': sample_idx, 'gt_idx': i,
'box3d_lidar': gt_boxes[i], 'num_points_in_gt': gt_points.shape[0],
'difficulty': difficulty[i], 'bbox': bbox[i], 'score': annos['score'][i]}
if names[i] in all_db_infos:
all_db_infos[names[i]].append(db_info)
else:
all_db_infos[names[i]] = [db_info]
# Output the num of all classes in database
for k, v in all_db_infos.items():
print('Database %s: %d' % (k, len(v)))
with open(db_info_save_path, 'wb') as f:
pickle.dump(all_db_infos, f)
@staticmethod
def create_label_file_with_name_and_box(class_names, gt_names, gt_boxes, save_label_path):
with open(save_label_path, 'w') as f:
for idx in range(gt_boxes.shape[0]):
boxes = gt_boxes[idx]
name = gt_names[idx]
if name not in class_names:
continue
line = "{x} {y} {z} {l} {w} {h} {angle} {name}\n".format(
x=boxes[0], y=boxes[1], z=(boxes[2]), l=boxes[3],
w=boxes[4], h=boxes[5], angle=boxes[6], name=name
)
f.write(line)
@staticmethod
def generate_prediction_dicts(batch_dict, pred_dicts, class_names, output_path=None):
"""
Args:
batch_dict:
frame_id:
pred_dicts: list of pred_dicts
pred_boxes: (N, 7), Tensor
pred_scores: (N), Tensor
pred_labels: (N), Tensor
class_names:
output_path:
Returns:
"""
def get_template_prediction(num_samples):
ret_dict = {
'name': np.zeros(num_samples), 'truncated': np.zeros(num_samples),
'occluded': np.zeros(num_samples), 'alpha': np.zeros(num_samples),
'bbox': np.zeros([num_samples, 4]), 'dimensions': np.zeros([num_samples, 3]),
'location': np.zeros([num_samples, 3]), 'rotation_y': np.zeros(num_samples),
'score': np.zeros(num_samples), 'boxes_lidar': np.zeros([num_samples, 7])
}
return ret_dict
def generate_single_sample_dict(batch_index, box_dict):
pred_scores = box_dict['pred_scores'].cpu().numpy()
pred_boxes = box_dict['pred_boxes'].cpu().numpy()
pred_labels = box_dict['pred_labels'].cpu().numpy()
pred_dict = get_template_prediction(pred_scores.shape[0])
if pred_scores.shape[0] == 0:
return pred_dict
calib = batch_dict['calib'][batch_index]
image_shape = batch_dict['image_shape'][batch_index].cpu().numpy()
pred_boxes_camera = box_utils.boxes3d_lidar_to_kitti_camera(pred_boxes, calib)
pred_boxes_img = box_utils.boxes3d_kitti_camera_to_imageboxes(
pred_boxes_camera, calib, image_shape=image_shape
)
pred_dict['name'] = np.array(class_names)[pred_labels - 1]
pred_dict['alpha'] = -np.arctan2(-pred_boxes[:, 1], pred_boxes[:, 0]) + pred_boxes_camera[:, 6]
pred_dict['bbox'] = pred_boxes_img
pred_dict['dimensions'] = pred_boxes_camera[:, 3:6]
pred_dict['location'] = pred_boxes_camera[:, 0:3]
pred_dict['rotation_y'] = pred_boxes_camera[:, 6]
pred_dict['score'] = pred_scores
pred_dict['boxes_lidar'] = pred_boxes
return pred_dict
annos = []
for index, box_dict in enumerate(pred_dicts):
frame_id = batch_dict['frame_id'][index]
single_pred_dict = generate_single_sample_dict(index, box_dict)
single_pred_dict['frame_id'] = frame_id
annos.append(single_pred_dict)
if output_path is not None:
cur_det_file = output_path / ('%s.txt' % frame_id)
with open(cur_det_file, 'w') as f:
bbox = single_pred_dict['bbox']
loc = single_pred_dict['location']
dims = single_pred_dict['dimensions'] # lhw -> hwl
for idx in range(len(bbox)):
print('%s -1 -1 %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f'
% (single_pred_dict['name'][idx], single_pred_dict['alpha'][idx],
bbox[idx][0], bbox[idx][1], bbox[idx][2], bbox[idx][3],
dims[idx][1], dims[idx][2], dims[idx][0], loc[idx][0],
loc[idx][1], loc[idx][2], single_pred_dict['rotation_y'][idx],
single_pred_dict['score'][idx]), file=f)
return annos
def create_custom_infos(dataset_cfg, class_names, data_path, save_path, workers=4):
dataset = CustomDataset(
dataset_cfg=dataset_cfg, class_names=class_names, root_path=data_path,
training=False, logger=common_utils.create_logger()
)
train_split, val_split = 'train', 'val'
num_features = len(dataset_cfg.POINT_FEATURE_ENCODING.src_feature_list)
train_filename = save_path / ('custom_infos_%s.pkl' % train_split)
val_filename = save_path / ('custom_infos_%s.pkl' % val_split)
print('------------------------Start to generate data infos------------------------')
dataset.set_split(train_split)
custom_infos_train = dataset.get_infos(
num_workers=workers, has_label=True, count_inside_pts=True
)
with open(train_filename, 'wb') as f:
pickle.dump(custom_infos_train, f)
print('Custom info train file is saved to %s' % train_filename)
dataset.set_split(val_split)
custom_infos_val = dataset.get_infos(
num_workers=workers, has_label=True, count_inside_pts=True
)
with open(val_filename, 'wb') as f:
pickle.dump(custom_infos_val, f)
print('Custom info train file is saved to %s' % val_filename)
print('------------------------Start create groundtruth database for data augmentation------------------------')
dataset.set_split(train_split)
dataset.create_groundtruth_database(train_filename, split=train_split)
print('------------------------Data preparation done------------------------')
if __name__ == '__main__':
import sys
if sys.argv.__len__() > 1 and sys.argv[1] == 'create_custom_infos':
import yaml
from pathlib import Path
from easydict import EasyDict
dataset_cfg = EasyDict(yaml.safe_load(open(sys.argv[2])))
ROOT_DIR = (Path(__file__).resolve().parent / '../../../').resolve()
create_custom_infos(
dataset_cfg=dataset_cfg,
class_names=['Car', 'Pedestrian', 'Van'],
data_path=ROOT_DIR / 'data' / 'custom',
save_path=ROOT_DIR / 'data' / 'custom',
)
2. tools/cfgs/custom_models/pointpillar.yaml
这个函数主要是网络模型参数的配置
我主要修改了以下几个点:
CLASS_NAMES(替换成你自己的类别信息)
_BASE_CONFIFG(custom_dataset.yaml的路径,建议用详细的绝对路径)
POINT_CLOUD_RANGE和VOXEL_SIZE
这两者很重要,直接影响后面模型的传播,如果设置不对很容易报错
官方建议 Voxel设置:X,Y方向个数是16的倍数。Z方向为40。
之前尝试设置了一些还是不行,这个我也没太明白到底怎么回事,索性我就不修改
- ANCHOR_GENERATOR_CONFIG
我修改了自己的类别属性以及feature_map_stride,去除了gt_sampling
完整的代码如下:
CLASS_NAMES: ['Car', 'Pedestrian', 'Van']
DATA_CONFIG:
_BASE_CONFIG_: /home/gmm/下载/OpenPCDet/tools/cfgs/dataset_configs/custom_dataset.yaml
POINT_CLOUD_RANGE: [0, -39.68, -3, 69.12, 39.68, 1]
DATA_PROCESSOR:
- NAME: mask_points_and_boxes_outside_range
REMOVE_OUTSIDE_BOXES: True
- NAME: shuffle_points
SHUFFLE_ENABLED: {
'train': True,
'test': False
}
- NAME: transform_points_to_voxels
VOXEL_SIZE: [0.16, 0.16, 4]
MAX_POINTS_PER_VOXEL: 32
MAX_NUMBER_OF_VOXELS: {
'train': 16000,
'test': 40000
}
DATA_AUGMENTOR:
DISABLE_AUG_LIST: ['placeholder']
AUG_CONFIG_LIST:
# - NAME: gt_sampling
# USE_ROAD_PLANE: True
# DB_INFO_PATH:
# - custom_dbinfos_train.pkl
# PREPARE: {
# filter_by_min_points: ['Car:5', 'Pedestrian:5', 'Van:5']
# }
#
# SAMPLE_GROUPS: ['Car:15', 'Pedestrian:15', 'Van:15']
# NUM_POINT_FEATURES: 4
# DATABASE_WITH_FAKELIDAR: False
# REMOVE_EXTRA_WIDTH: [0.0, 0.0, 0.0]
# LIMIT_WHOLE_SCENE: False
- NAME: random_world_flip
ALONG_AXIS_LIST: ['x']
- NAME: random_world_rotation
WORLD_ROT_ANGLE: [-0.78539816, 0.78539816]
- NAME: random_world_scaling
WORLD_SCALE_RANGE: [0.95, 1.05]
MODEL:
NAME: PointPillar
VFE:
NAME: PillarVFE
WITH_DISTANCE: False
USE_ABSLOTE_XYZ: True
USE_NORM: True
NUM_FILTERS: [64]
MAP_TO_BEV:
NAME: PointPillarScatter
NUM_BEV_FEATURES: 64
BACKBONE_2D:
NAME: BaseBEVBackbone
LAYER_NUMS: [3, 5, 5]
LAYER_STRIDES: [2, 2, 2]
NUM_FILTERS: [64, 128, 256]
UPSAMPLE_STRIDES: [1, 2, 4]
NUM_UPSAMPLE_FILTERS: [128, 128, 128]
DENSE_HEAD:
NAME: AnchorHeadSingle
CLASS_AGNOSTIC: False
USE_DIRECTION_CLASSIFIER: True
DIR_OFFSET: 0.78539
DIR_LIMIT_OFFSET: 0.0
NUM_DIR_BINS: 2
ANCHOR_GENERATOR_CONFIG: [
{
'class_name': 'Car',
'anchor_sizes': [[1.8, 4.7, 1.8]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [0],
'align_center': False,
'feature_map_stride': 2,
'matched_threshold': 0.55,
'unmatched_threshold': 0.45
},
{
'class_name': 'Pedestrian',
'anchor_sizes': [[0.77, 0.92, 1.83]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [0],
'align_center': False,
'feature_map_stride': 2,
'matched_threshold': 0.5,
'unmatched_threshold': 0.45
},
{
'class_name': 'Van',
'anchor_sizes': [[2.5, 5.7, 1.9]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [0],
'align_center': False,
'feature_map_stride': 2,
'matched_threshold': 0.5,
'unmatched_threshold': 0.45
},
]
TARGET_ASSIGNER_CONFIG:
NAME: AxisAlignedTargetAssigner
POS_FRACTION: -1.0
SAMPLE_SIZE: 512
NORM_BY_NUM_EXAMPLES: False
MATCH_HEIGHT: False
BOX_CODER: ResidualCoder
LOSS_CONFIG:
LOSS_WEIGHTS: {
'cls_weight': 1.0,
'loc_weight': 2.0,
'dir_weight': 0.2,
'code_weights': [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
}
POST_PROCESSING:
RECALL_THRESH_LIST: [0.3, 0.5, 0.7]
SCORE_THRESH: 0.1
OUTPUT_RAW_SCORE: False
EVAL_METRIC: kitti
NMS_CONFIG:
MULTI_CLASSES_NMS: False
NMS_TYPE: nms_gpu
NMS_THRESH: 0.01
NMS_PRE_MAXSIZE: 4096
NMS_POST_MAXSIZE: 500
OPTIMIZATION:
BATCH_SIZE_PER_GPU: 4
NUM_EPOCHS: 80
OPTIMIZER: adam_onecycle
LR: 0.003
WEIGHT_DECAY: 0.01
MOMENTUM: 0.9
MOMS: [0.95, 0.85]
PCT_START: 0.4
DIV_FACTOR: 10
DECAY_STEP_LIST: [35, 45]
LR_DECAY: 0.1
LR_CLIP: 0.0000001
LR_WARMUP: False
WARMUP_EPOCH: 1
GRAD_NORM_CLIP: 10
3. tools/cfgs/dataset_configs/custom_dataset.yaml
修改了DATA_PATH, POINT_CLOUD_RANGE和MAP_CLASS_TO_KITTI还有其他的一些类别属性。
修改后的代码如下:
DATASET: 'CustomDataset'
DATA_PATH: '/home/gmm/下载/OpenPCDet/data/custom'
POINT_CLOUD_RANGE: [0, -40, -3, 70.4, 40, 1]
DATA_SPLIT: {
'train': train,
'test': val
}
INFO_PATH: {
'train': [custom_infos_train.pkl],
'test': [custom_infos_val.pkl],
}
GET_ITEM_LIST: ["points"]
FOV_POINTS_ONLY: True
MAP_CLASS_TO_KITTI: {
'Car': 'Car',
'Pedestrian': 'Pedestrian',
'Van': 'Cyclist',
}
DATA_AUGMENTOR:
DISABLE_AUG_LIST: ['placeholder']
AUG_CONFIG_LIST:
- NAME: gt_sampling
USE_ROAD_PLANE: False
DB_INFO_PATH:
- custom_dbinfos_train.pkl
PREPARE: {
filter_by_min_points: ['Car:5', 'Pedestrian:5', 'Van:5'],
}
SAMPLE_GROUPS: ['Car:20', 'Pedestrian:15', 'Van:20']
NUM_POINT_FEATURES: 4
DATABASE_WITH_FAKELIDAR: False
REMOVE_EXTRA_WIDTH: [0.0, 0.0, 0.0]
LIMIT_WHOLE_SCENE: True
- NAME: random_world_flip
ALONG_AXIS_LIST: ['x']
- NAME: random_world_rotation
WORLD_ROT_ANGLE: [-0.78539816, 0.78539816]
- NAME: random_world_scaling
WORLD_SCALE_RANGE: [0.95, 1.05]
POINT_FEATURE_ENCODING: {
encoding_type: absolute_coordinates_encoding,
used_feature_list: ['x', 'y', 'z', 'intensity'],
src_feature_list: ['x', 'y', 'z', 'intensity'],
}
DATA_PROCESSOR:
- NAME: mask_points_and_boxes_outside_range
REMOVE_OUTSIDE_BOXES: True
- NAME: shuffle_points
SHUFFLE_ENABLED: {
'train': True,
'test': False
}
- NAME: transform_points_to_voxels
VOXEL_SIZE: [0.05, 0.05, 0.1]
MAX_POINTS_PER_VOXEL: 5
MAX_NUMBER_OF_VOXELS: {
'train': 16000,
'test': 40000
}
- demo.py
之前训练之后检测框并没有出来,后来我才发现可能是自己的数据集太少,出来的检测框精度太低,于是我在V.draw_scenes部分作了一点修改,并在之前加入一个mask限制条件,结果果然出来检测框了。
demo.py修改部分的代码:
with torch.no_grad():
for idx, data_dict in enumerate(demo_dataset):
logger.info(f'Visualized sample index: \t{idx + 1}')
data_dict = demo_dataset.collate_batch([data_dict])
load_data_to_gpu(data_dict)
pred_dicts, _ = model.forward(data_dict)
scores = pred_dicts[0]['pred_scores'].detach().cpu().numpy()
mask = scores > 0.3
V.draw_scenes(
points=data_dict['points'][:, 1:], ref_boxes=pred_dicts[0]['pred_boxes'][mask],
ref_scores=pred_dicts[0]['pred_scores'], ref_labels=pred_dicts[0]['pred_labels'],
)
if not OPEN3D_FLAG:
mlab.show(stop=True)
三. 运行过程
1. 生成数据字典
python -m pcdet.datasets.custom.custom_dataset create_custom_infos tools/cfgs/dataset_configs/custom_dataset.yaml
** 2. 训练**
这里我偷懒只训练10轮,自己可以自定义
python tools/train.py --cfg_file tools/cfgs/custom_models/pointpillar.yaml --batch_size=1 --epochs=10

这里有个警告不知道怎么回事,暂时忽略[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
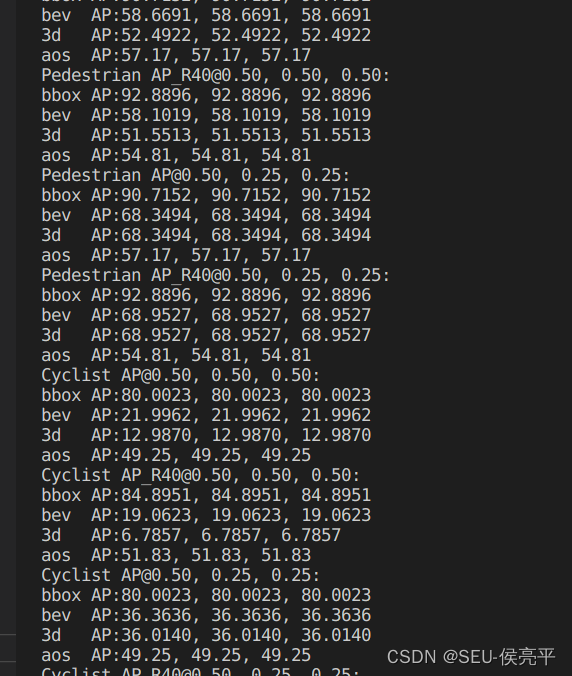
- 评估
由于数据集样本设置比较少,而且训练次数比较少,可以看出评估结果较差
- 结果

还好能有显示,如果没有出现检测框可以把demo.py的score调低
版权归原作者 SEU-侯亮平 所有, 如有侵权,请联系我们删除。