基于mediapipe的人体33个关键点坐标(BlazePose)
获取mediapipe中人体33个关键点的坐标(BlazePose)
编织人工智能:机器学习发展历史与关键技术全解析
关注TechLead,分享AI领域与云服务领域全维度开发技术。本文全面回顾了机器学习的发展历史,从早期的基本算法到当代的深度学习模型,再到未来的可解释AI和伦理考虑。文章深入探讨了各个时期的关键技术和理念,揭示了机器学习在不同领域的广泛应用和潜力。
中文CLIP快速上手指南
当前OpenAI提出的CLIP是AI领域内最火热的多模态预训练模型,简单的图文双塔结构让多模态表征学习变得异常简单。此前CLIP只有官方英文版本,如果想在中文领域尤其是业务当中使用这种强大的表征模型,需要非常麻烦的翻译工作。近期达摩院提出中文版本CLIP,Chinese CLIP系列,在ModelS
python峰谷值算法:findpeaks
python峰谷值算法:findpeaks
Mx_yolov3的安装并使用GPU训练
小白为了使用GPU训练模型,从各位大佬那里找来的解决方法,希望可以给大家提供帮助。
机器学习算法:UMAP 深入理解(通俗易懂!)
UMAP 是 McInnes 等人开发的新算法。与t-SNE相比,它具有许多优势,最显着的是提高了计算速度并更好地保留了数据的全局结构。降维是机器学习从业者可视化和理解大型高维数据集的常用方法。最广泛使用的可视化技术之一是 t-SNE,但它的性能受到数据集规模的影响,并且正确使用它可能需要一定学习成
反光板导航SLAM(三)反光柱导航开发与实验
在上一章中简单了解了VEnus算法对于反光柱导航的基本思路。其主要分为了高反点提取、高反点聚类查找中心、高反点与已知反光柱位姿匹配以及调用ceres库进行位姿优化等步骤。然后在这个算法的基础上,再进行一定的开发达到一个比较稳定且可视化的版本。简单录制一下运行效果,类似于这样:out这里使用的是自己录
参数估计方法总结(超全!!!)
本文介绍了常见的参数估计方法,包括点估计、区间估计、假设检验和模型选择等。
【周末闲谈】“深度学习”,人工智能也要学习?
人们在日常生活中接触人工智能的频率越来越高。有可以帮用户买菜的京东智能冰箱;可以做自动翻译的机器;还有Siri、Alexa和Cortana这样的机器人助理;以及无人车、AlphaGo等已经把人工智能技术带到了“看得到摸得着”的境地。我们也许会好奇,它是怎么做到的?今天我们就来谈谈人工智能的学习方式—
python人工智能技术
人工智能(AI)已成为当今世界的热门话题,它的应用范围越来越广泛。其中,Python成为AI开发中最受欢迎的编程语言之一。Python提供了许多功能强大的库和框架,大大简化了开发人员的工作。在本文中,我们将介绍Python在人工智能领域中的三个主要应用。
yolov5训练时的dataset not found
关于这个问题,大都是因为数据集的路径问题,需要主要的是自己的数据集的下的data.yaml文件,这个文件里的两个相对路径改成绝对路径(写的潦草,只为自己有点印象。
【集群】Slurm作业调度系统的使用
【集群】Slurm作业调度系统的使用
海康线阵相机调试指导
前段时间应公司结构要求,需评估结构和硬件,主要围绕线阵相机图像质量上,在此记录下调试过程中的一些经验,希望能给同行一些方向,互相学习。
Neuralangelo AI - 视频生成3D模型
通过 Neuralangelo,NVIDIA Research 展示了 AI 在将 2D 视频转换为身临其境的 3D 场景方面的巨大潜力。它捕捉复杂细节和纹理的能力为各个行业开辟了新的可能性,从游戏和艺术到机器人和工业数字孪生。Neuralangelo 彻底改变了创意工作流程,使专业人士能够以无与伦
relu函数的作用
relu函数的作用
GCNet: Global Context Network(ICCV 2019)原理与代码解析
本文通过观察发现non-local block针对每个query position计算的attention map最终结果是独立于查询位置的,那么就没有必要针对每个查询位置计算了,因此提出计算一个通用的attention map并应用于输入feature map上的所有位置,大大减少了计算量的同时又
人工智能的最新进展:2024年将会发生什么?
人工智能(AI)是一种快速发展的技术,它正在不断改变我们的生活。在过去几年中,AI取得了重大进展,我们可以预计在2024年将会看到更多突破。
自动驾驶级别划分(SAE分级)
目前被国内外广为接受的自动驾驶级别划分标准是 SAE(国际汽车工程学会)分级,从 Level-0~Level-5 总计6 个级别,Level-0 为最低级别,Level-5 为最高级别。如下图,从无自动化,到“解放双脚”,“解放双手”,“解放双眼”,“解放大脑”,最终达到完全的“无驾驶员”化。
WPS Office AI实战:智能表格化身智能助理
前面我们已经拿 WPS AI 对Word文字、PPT幻灯片、PDF 做了开箱体验,还没有看过的小伙伴,请翻看以前的文章,本文开始对【智能表格】进行AI开箱测验。表格在日常的数据处理中占绝对地位,但表格处理并不是每一个人都擅长,特别是涉及到函数、公式等相关的高级应用,基本上就劝退大部分人了,WPS A
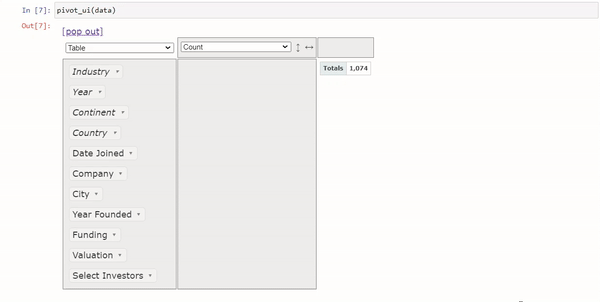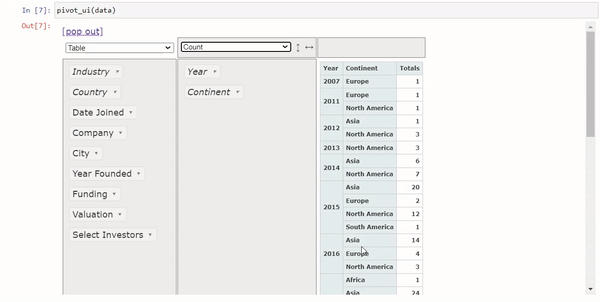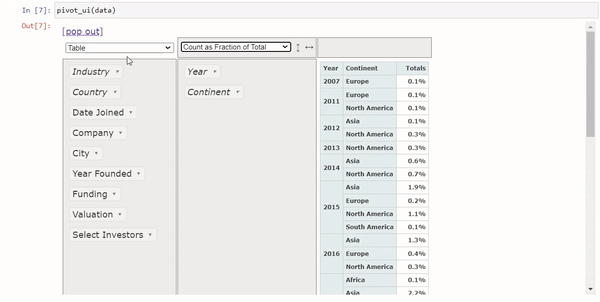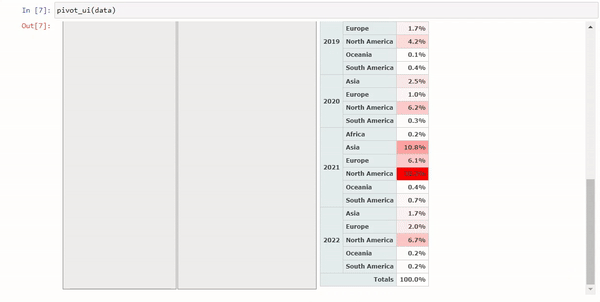
4个将Pandas换为交互式表格Python包
Pandas是我们日常处理表格数据最常用的包,但是对于数据分析来说,Pandas的DataFrame还不够直观,所以今天我们将介绍4个Python包,可以将Pandas的DataFrame转换交互式表格,让我们可以直接在上面进行数据分析的操作。



