
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词(英语)指导下产生图生图的翻译。
DreamStudio 现已推出了 Stable Diffusion XL Preview 版本,你可以在官方画抢先体验:DreamStudio官方画板
Stable Diffusion的代码和模型权重已公开发布,可以在大多数配备有适度GPU的电脑硬件上运行。而以前的专有文生图模型(如DALL-E和Midjourney)只能通过云计算服务访问。
想要在自己的设备上部署 Stable Diffusion 您可以根据部署平台来获取帮助:Windows Mac
Stable Diffusion模型支持通过使用提示词来产生新的图像,描述要包含或省略的元素,以及重新绘制现有的图像,其中包含提示词中描述的新元素(该过程通常被称为“指导性图像合成”(guided image synthesis)通过使用模型的扩散去噪机制(diffusion-denoising mechanism)。此外,该模型还允许通过提示词在现有的图中进内联补绘制和外补绘制来部分更改,当与支持这种功能的用户界面使用时,其中存在许多不同的开源软件。
Windows版本安装指南:
硬件要求
对硬件最低要求是需要一个 8GB 显存以上的 Nvidia 1000 系显卡,最好是 RTX 系列显卡,会快不少。 AMD和 Intel 显卡不可以。 达不到的同学可以白嫖 Google Colab 的计算资源(显存16GB+)。
安装过程
网盘下载链接:百度网盘 请输入提取码 提取码:17ai
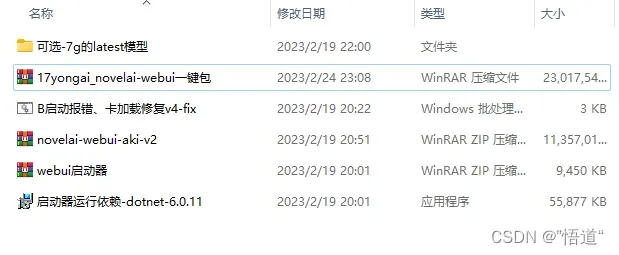
2、解压novelai-webui-aki-v2压缩包
3、解压webui启动器压缩包
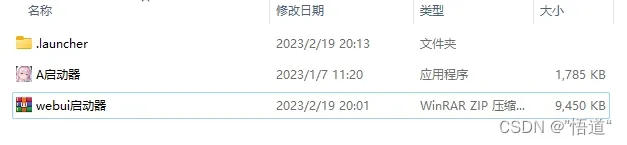
4、将webui启动器中文件放入novelai-webui-aki-v2文件夹中
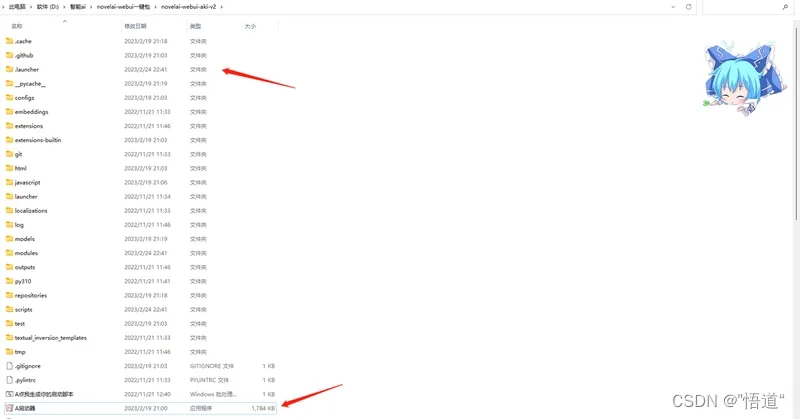
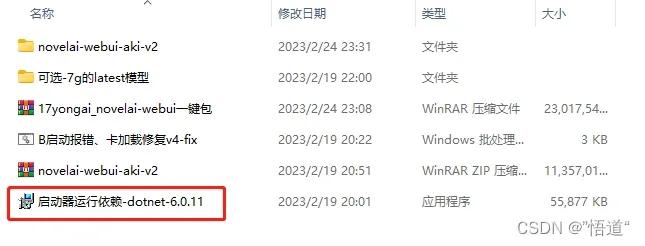
5、运行安装启动器运行依赖-dotnet-6.0.11
6、运行启动器
**7、等待安装(需要10到20分钟) **
8、安装完成,进入界面
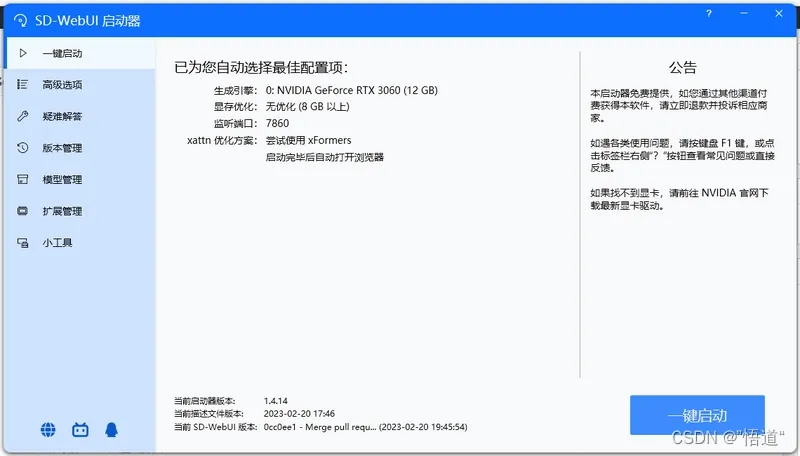
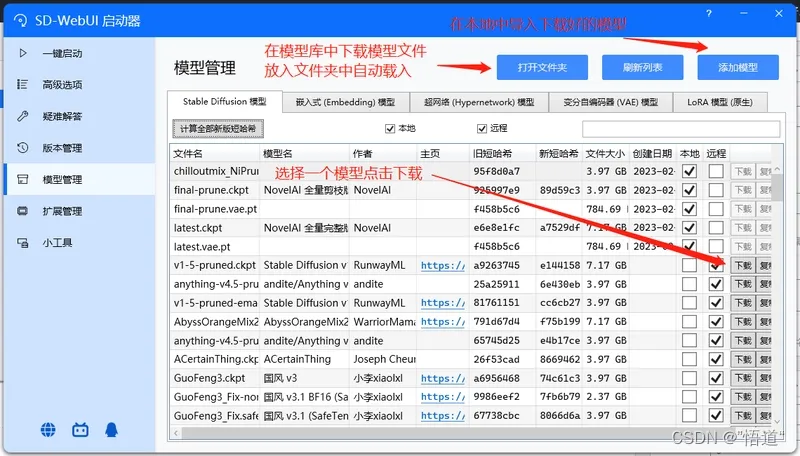
9、进入模型管理中“变分自编码器(VAE) 模型”,下载SD模板

10、进入Stable Diffusion 模型中下载安装模型文件(可以将压缩包中的模型导入到其中)
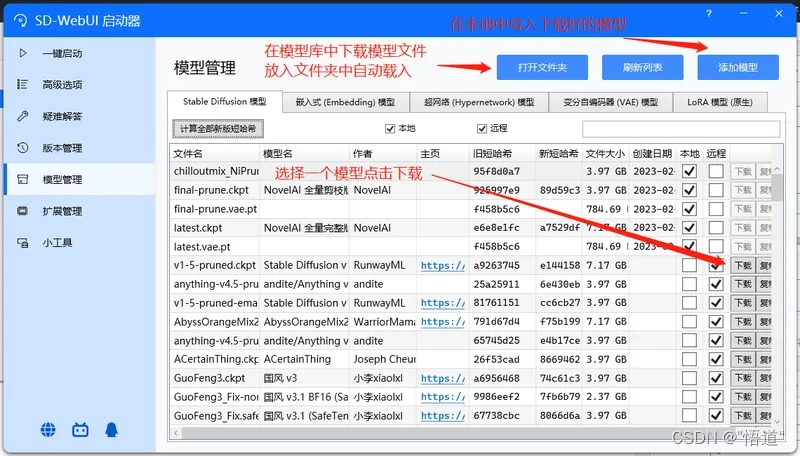
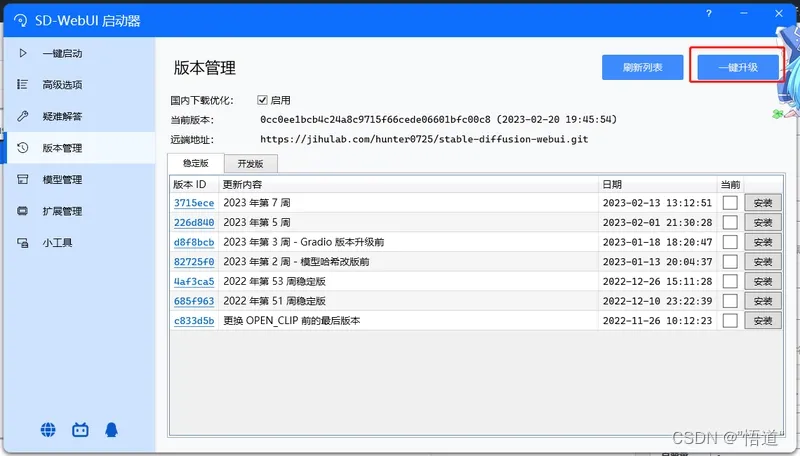
11、可在版本管理中下载自己想要的版本,一键升级可升级至最新版本
 编辑
编辑
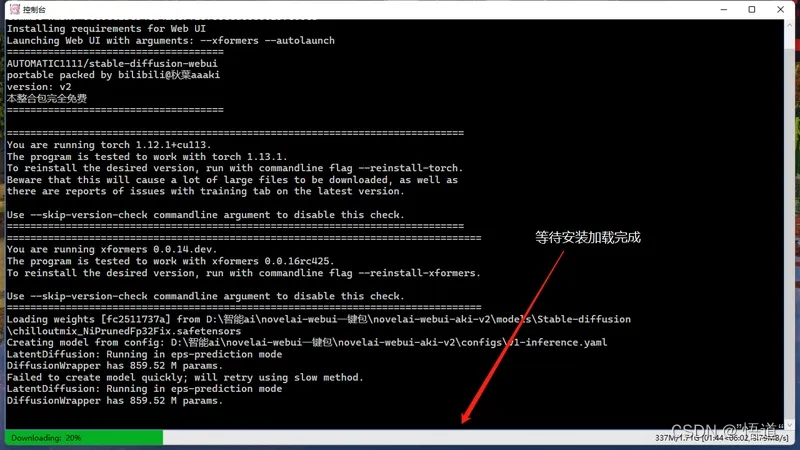
12、现在就可以开始启动SD了(启动时请关闭代理)

13、等待安装加载完毕,默认浏览器中生成SDweb端界面
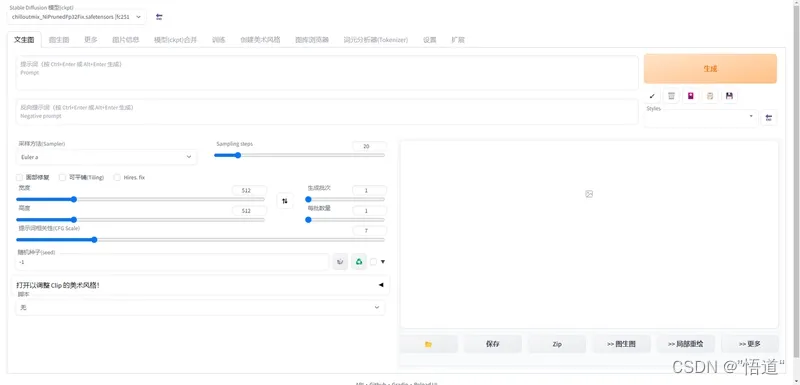
14、进入设置中选择SD模版

15、选择你想要使用的模型,输入关键词就可生成图片
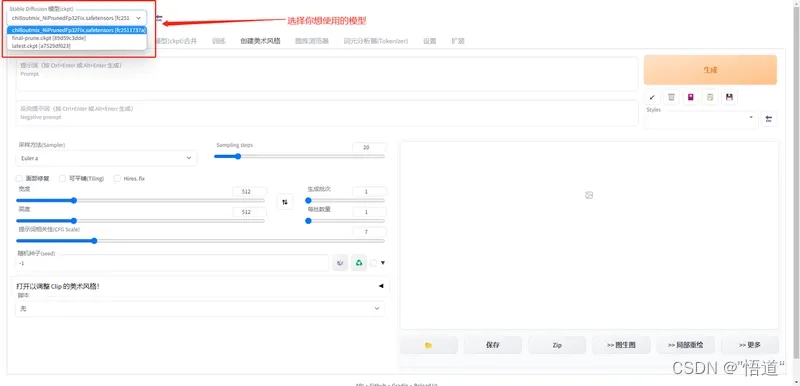

16、现在可以使用SD来生成你想要的图片了,查看更多模型转至civitai
MAC系统安装指南

软硬件需求
- 一台Mac电脑,系统是M1或M2,内存 8G 以上(越大越好,越大越快)。
- 硬盘可用空间最低 10G 以上,最好 30G 以上。
- 需要能够流畅访问内外网。
安装过程
**1、安装 homebrew *打开 terminal 终端(command + 空格键,输入terminal,回车打开),安装homebrew。(如果已经安装,可跳到下一步)*
2、在terminal内复制执行下面这段代码(官方版):
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
如果网络问题一直没反应或者报错,可以用国内镜像版:
/bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.sh)"
检测是否安装成功homebrew
brew -v
如果会显示homebrew的版本信息,则安装成功。
如果显示
zsh: command not found: brew
则需要将 Homebrew 添加到环境变量 PATH 中,并给出了相应的操作步骤。用户需要按照给出的建议配置环境变量,以便在终端中正常使用 Homebrew。立即在当前终端/Shell 中执行
eval "$(/opt/homebrew/bin/brew shellenv)"
**3、安装python **打开一个新的terminal终端窗口并运行:
brew install cmake protobuf rust python@3.10 git wget
4、安装stable-diffusion-webui如果未安装git的,先安装git。 Terminal内运行:
brew install git
接着用 git 把 stable diffusion webui的github 开源程序全部克隆到自己的 Mac 电脑本地,terminal 内执行:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
**5、下载ai绘图基础模型 **这里以 Stable Diffusion 2.0 训练模型为例在stabilityai/stable-diffusion-2 · Hugging Face页面的“file” tag里面找到并下载 768-v-ema.ckpt。 下载好后,把下载好的 ckpt 文件放在“你的用户名”> Stable-diffusion-webui>Models>Stable-diffusion文件夹里。 **6、运行stable-diffusion-webui **用terminal进入stable-diffusion-webui的文件夹。 运行
cd stable-diffusion-webui
打开stable-diffusion-webui,运行
./webui.sh
这一步可能需要花费较长时间,因为会下载几个 SD 必需的应用。如果长时间没有进展,各种报错,则用访达(finder)打开 stable-diffusion-webui 文件夹,找到 launch.py 等文件,用系统自带的文本编辑软件打开,在大概 200-300 行左右,找到类似
“gfpgan_package = os.environ.get('GFPGAN_PACKAGE', "git+
https://github.com/TencentARC/GFPGAN.git@8d2447a2d918f8eba5a4a01463fd48e45126a379")”
的段落。并在“https://github.com/xxx”的最前面,加上:“https://ghproxy.com/”这样系统下载相关应用就会修改为在国内镜像站下载,会稳定和快速一些。加上之后,就会变成类似:
“gfpgan_package = os.environ.get('GFPGAN_PACKAGE', "git+
https://ghproxy.com/https://github.com/TencentARC/GFPGAN.git@8d2447a2d918f8eba5a4a01463fd48e45126a379")”
的文段。把 gfpgan 前后的几行,带 github 网址的段落,都加上。类似下图:

保存并关闭launch.py文件。重新运行./webui.sh,这时候等几分钟估计就能好了。直到terminal 显示
“Running on local URL:
http://127.0.0.1:7860To create a public link, setshare=Truein
launch(). ”
**7、打开stable-diffusion-webui网页版 **注意不要关闭terminal小窗,打开浏览器(Safari或者Chrome)后输入http://127.0.0.1:7860,即可访问本地网页版的 stable diffusion webui

接下来可以在 prompt 框里面输入提示词后,就能点 Generate 生成 AI 绘图了。
版权归原作者 ”悟道“ 所有, 如有侵权,请联系我们删除。