torch安装找不到版本报错
torch安装找不到版本报错的4种解决办法,可按顺序来
whisper 语音识别AI 声音To文字
是一个由 OpenAI 训练并开源的,功能是语音识别,能把转换为,在英语语音识别方面的稳健性和准确性接近人类水平。1、Whisper支持语音转录和翻译两项功能并接受各种语音格式,模型中、英、法、德、意、日等主流语言上取得85%以上的准确率,完全符合工业准确率标准,未来有望打开商业化空间;2、Whis
统计数据集中目标大、中、小个数【需要用到yolo的txt标注文件数据,其他格式数据不一定适用】
统计数据集中目标大、中、小个数
〖程序员的自我修养 - 认知剖析篇②〗- 学习编程之前你需要知道这些
放在现实的角度上,语言的选择是非常非常重要的,也许一个不经意的选择影响的可能就是我们的一生。在于一些小伙伴沟通之后,我将他们所提出的问题进行了了解与思考,并记录下来,希望能够给刚刚开始或者准备学习编程的小伙伴伴带去一些启发或者帮助。
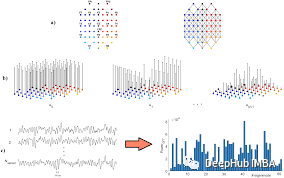
理解图傅里叶变换和图卷积
图神经网络(GNN)代表了一类强大的深度神经网络架构。本文将介绍图卷积的理论基础。深入研究图傅立叶变换的复杂性及其与图卷积的联系
AI 时代,程序员无需焦虑
AI 时代,程序员无需焦虑
【AI】即使AI 时代,程序员也无需焦虑
ChatGPT 横空出世后,“AI 即将取代程序员” 的观点一度引发热议,至今尚未完全冷却。那么AI时代程序员该何去何从呢?
扩散模型原理+DDPM案例代码解析
扩散模型 DDPM 代码实现 从数学公式到代码一步步理解
Java智慧工地APP源码带AI识别
智慧工地管理平台将施工现场业务系统和硬件设备集成到云平台,与视频监控、工地实名制、工地考勤闸机、安全帽识别、反光背心、识别火焰、抽烟等多端口对接同步,并将产生的数据汇总形成数据中心。
pytorch分布式训练报错RuntimeError: Socket Timeout
pytorch分布式训练中出现socket timeout情况

微调llama2模型教程:创建自己的Python代码生成器
本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。
java openCV 简单使用
Java OpenCV 是一个用于图像处理和计算机视觉的开源库。要使用 Java OpenCV,您需要先安装 OpenCV 库并将其与 Java 环境配合使用。安装 OpenCV:在终端中输入以下命令以在 Linux 或 Mac 系统上安装 OpenCV:sudo apt-get install o
软件测试下的AI之路(1)
随着科技日新月异的发展,人工智能正逐渐渗透到我们生活的各方各面,从智能语音助手到自动驾驶汽车,从智能家居到人脸识别技术,AI正以其卓越的智能和学习能力引领着新时代的发展方向。在这个快速演进的时代中,软件测试领域也受到了不小的冲击。虽然在当下,传统的软测技术仍然是绝对的主力,但是身为IT行业中的一员,
【Opencv】CV_* was not declared in this scope 的部分解决方法
Opencv CV* was not declared in this scope 的部分解决方法
了解NVIDAI显卡驱动(包括:CUDA、CUDA Driver、CUDA Toolkit、CUDNN、NCVV)
比如:需要安装TensorFlow2.1(使用GPU),要求我们只能安装CUDATOOLKIT=10.1,那么我们就从7.6.4、7.6.3、7.6.2这三个版本中,选择一个最新的7.6.4版本来安装CUDNN。每个版本的CUDA Toolkit 都对应一个最低版本的CUDA Driver,也就是说
【域泛化综述-2022 TPAMI】Domain Generalization: A Survey
2022TPAMI 域泛化综述阅读
Py之face_alignment:人脸对齐库face_alignment的完整安装与使用攻略
然而,由于面部在不同的姿势、光照条件和表情下会产生许多变化,因此准确的面部对齐仍然是一个具有挑战性的任务。Face Alignment技术的目标就是在更好地描述人脸形状的基础上,实现更精准、更可靠的面部对齐。Face Alignment是对齐人脸上的一些关键点,如嘴唇、眼睛、眉毛等,使得这些点在所有
ClearML入门:简化机器学习解决方案的开发和管理
ClearML 是一个开源平台(之前叫TRAINS),可为全球数千个数据科学团队自动化并简化机器学习解决方案的开发和管理。它被设计为端到端的MLOps套件,允许您专注于开发ML代码和自动化,而ClearML确保您的工作可重复和可扩展。仅用 2 行代码跟踪和上传指标和模型创建一个机器人,每当模型的准确
yolov8之导出onnx(二)
yolov8之导出onnx
医学图像的 AI 框架 MONAI 详细教程(一)
最近在读 CVPR 2023 上和医学图像方向相关的论文,发现其中的 Label-Free Liver Tumor Segmentation 这篇论文使用了 MONAI 这个框架。之前关注过的一些医学图像的期刊论文上,也有 MONAI 的出现,加之前的导师有过推荐,所以了解学习了下。简单检索后,发现



