
统计数据集中目标大、中、小个数
最近看到一篇论文,其中在数据集介绍部分统计了大、中、小目标信息。因此,为了获取数据集的统计信息,我参考了作者写的代码基于tensorpack统计coco数据集中大、中、小目标的数量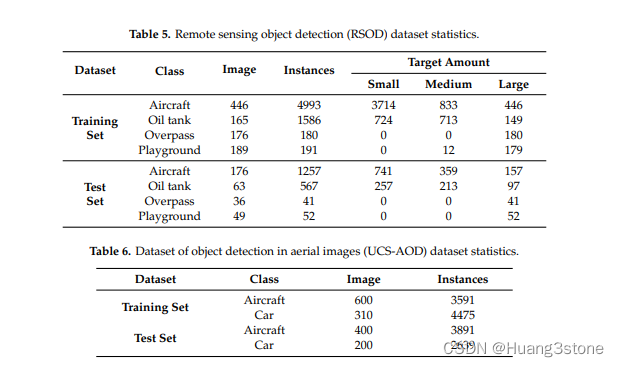
精简版代码如下(内有多个参数需要修改,仔细查看注释)
# 1、统计数据集中小、中、大 GT的个数# 2、统计某个类别小、中、大 GT的个数# 3、统计数据集中ss、sm、sl GT的个数import os
from pathlib import Path
import matplotlib.pyplot as plt
# 设置中文字体为微软雅黑
plt.rcParams['font.sans-serif']='SimHei'defgetGtAreaAndRatio(label_dir):"""
得到不同尺度的gt框个数
:params label_dir: label文件地址
:return data_dict: {dict: 3} 3 x {'类别':{’area':[...]}, {'ratio':[...]}}
"""
data_dict ={}assert Path(label_dir).is_dir(),"label_dir is not exist"
txts = os.listdir(label_dir)# 得到label_dir目录下的所有txt GT文件for txt in txts:# 遍历每一个txt文件withopen(os.path.join(label_dir, txt),'r')as f:# 打开当前txt文件 并读取所有行的数据
lines = f.readlines()for line in lines:# 遍历当前txt文件中每一行的数据
temp = line.split()# str to list{5}
coor_list =list(map(lambda x: x, temp[1:]))# [x, y, w, h]
area =float(coor_list[2])*float(coor_list[3])# 计算出当前txt文件中每一个gt的面积# center = (int(coor_list[0] + 0.5*coor_list[2]),# int(coor_list[1] + 0.5*coor_list[3]))
ratio =round(float(coor_list[2])/float(coor_list[3]),2)# 计算出当前txt文件中每一个gt的 w/hif temp[0]notin data_dict:
data_dict[temp[0]]={}
data_dict[temp[0]]['area']=[]
data_dict[temp[0]]['ratio']=[]
data_dict[temp[0]]['area'].append(area)
data_dict[temp[0]]['ratio'].append(ratio)return data_dict
defgetSMLGtNumByClass(data_dict, class_num):"""
计算某个类别的小物体、中物体、大物体的个数
params data_dict: {dict: 3} 3 x {'类别':{’area':[...]}, {'ratio':[...]}}
params class_num: 类别 0, 1, 2
return s: 该类别小物体的个数 0 < area <= 0.5%
m: 该类别中物体的个数 0.5% < area <= 1%
l: 该类别大物体的个数 area > 1%
"""
s, m, l =0,0,0# 图片的尺寸大小 注意修改!!!
h =960
w =540for item in data_dict['{}'.format(class_num)]['area']:if item * h * w <= h * w *0.005:
s +=1elif item * h * w <= h * w *0.010:
m +=1else:
l +=1return s, m, l
defgetAllSMLGtNum(data_dict, isEachClass=False):"""
数据集所有类别小、中、大GT分布情况
isEachClass 控制是否按每个类别输出结构
"""
S, M, L =0,0,0# 需要手动初始化下,有多少个类别就需要写多个
classDict ={'0':{'S':0,'M':0,'L':0},'1':{'S':0,'M':0,'L':0},'2':{'S':0,'M':0,'L':0},'3':{'S':0,'M':0,'L':0}}print(classDict['0']['S'])# range(class_num)类别数 注意修改!!!if isEachClass ==False:for i inrange(4):
s, m, l = getSMLGtNumByClass(data_dict, i)
S += s
M += m
L += l
return[S, M, L]else:for i inrange(4):
S =0
M =0
L =0
s, m, l = getSMLGtNumByClass(data_dict, i)
S += s
M += m
L += l
classDict[str(i)]['S']= S
classDict[str(i)]['M']= M
classDict[str(i)]['L']= L
return classDict
# 画图函数defplotAllSML(SML):
x =['S:[0, 32x32]','M:[32x32, 96x96]','L:[96*96, 640x640]']
fig = plt.figure(figsize=(10,8))# 画布大小和像素密度
plt.bar(x, SML, width=0.5, align="center", color=['skyblue','orange','green'])for a, b, i inzip(x, SML,range(len(x))):# zip 函数
plt.text(a, b +0.01,"%d"%int(SML[i]), ha='center', fontsize=15, color="r")# plt.text 函数
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.xlabel('gt大小', fontsize=16)
plt.ylabel('数量', fontsize=16)
plt.title('广佛手病虫害训练集小、中、大GT分布情况(640x640)', fontsize=16)
plt.show()# 保存到本地# plt.savefig("")if __name__ =='__main__':
labeldir =r'E:\project\py-project\network\dataset\UA-DETRAC-G2\labels\val'
data_dict = getGtAreaAndRatio(labeldir)# 1、数据集所有类别小、中、大GT分布情况# 控制是否按每个类别输出结构
isEachClass =False
SML = getAllSMLGtNum(data_dict, isEachClass)print(SML)ifnot isEachClass:
plotAllSML(SML)
本文转载自: https://blog.csdn.net/lafsca5/article/details/129203698
版权归原作者 Huang3stone 所有, 如有侵权,请联系我们删除。
版权归原作者 Huang3stone 所有, 如有侵权,请联系我们删除。