基于PP-YOLOE-SOD实现遥感场景下的小目标检测
目标边界框的宽高与图像的宽高比例小于一定值目标边界框面积与图像面积的比值开方小于一定值分辨率小于32*32像素的目标。如MS-COCO数据集像素值范围在[10,50]之间的目标。如DOTA/WIDER FACE数据集paddle从数据集整体层面提出了如下定义:目标边界框的宽高与图像的宽高比例的中位数
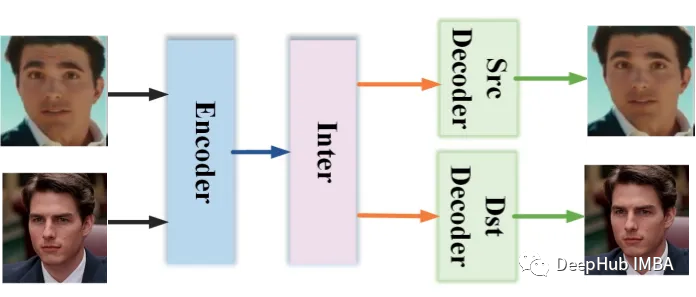
使用Pytorch和OpenCV实现视频人脸替换
“DeepFaceLab”项目已经发布了很长时间了,作为研究的目的,本文将介绍他的原理,并使用Pytorch和OpenCV创建一个简化版本。
探索人工智能 | 模型训练 使用算法和数据对机器学习模型进行参数调整和优化
模型训练是指使用算法和数据对机器学习模型进行参数调整和优化的过程。模型训练一般包含以下步骤:数据收集、数据预处理、模型选择、模型训练、模型评估、超参数调优、模型部署、持续优化。
【Java】智慧工地SaaS平台源码:AI/云计算/物联网/智慧监管
智慧工地源码包含:数据统计分析、项目人员监管、视频监控监管、危大工程监管、绿色施工监管、现场物料监管、安全隐患监管、项目人员管理、视频监控管理、危大工程管理、现场物料管理、绿色施工管理、安全隐患排查、施工质量管理、施工进度管理、工地设备管理等模块。
【AIGC 讯飞星火 | 百度AI|ChatGPT| 】智能对比
ai多角度对比各种ai软件的智能程度
『吴秋霖赠书活动 | 第一期』《强化学习:原理与Python实战》
『吴秋霖赠书活动 | 第一期』《强化学习:原理与Python实战》
人工智能引领图文扫描新趋势
基于智能OCR技术的不规则弱约束文档图片识别系统,首次应用在手绘括号思维导图数据几乎没有的情况下,按照机器学习的分阶段拆解任务的思路,融合了目标检测算法、像素域的聚类算法和目标计数算法,创新了一种层次逻辑生成算法,弥补当前模式识别在处理手绘括号图识别问题时的缺失。在获取三种信息后,训练一个较大的语言
探索大语言模型垂直化训练技术和应用-陈运文
产品化的是请垂直领域的专家,针对每项垂直任务,来设计用于生成 prompt 的产品,由专家编写大量不同的 prompt,评估或输出好的 prompt 后,进行片段切分,形成相应的产品,这对未来 AIGC 任务会起到很好的作用。由上往下,当计算机做一个长文档的规划协作生成的内容,我们让相应的其他模型做
对yolov5的数据集进行划分【训练集、验证集、测试集】7:2:1和【训练集、验证集】8:2
对yolov5的数据集进行划分【训练集、验证集、测试集】7:2:1和【训练集、验证集】8:2
模型优化之模型剪枝
(2)非结构化剪枝:把权重矩阵中某个神经元节点去掉,则和神经元相连接的突触也要全部去除。可以通过计算神经元对应的行和列的权重值的平方和的根的大小进行排序,把排序在后面一定比例的神经元节点去掉。Pytorch中模型的剪枝方法有三种,局部剪枝、全局剪枝和自定义剪枝。接下来开始演示三种剪枝在LeNet网络
人工智能术语翻译(五)
人工智能术语翻译第四部分,包括Q、R、S、T开头的词汇!
国内最新的ChatGpt4模型可用介绍镜像CODE-MJ 分析 报道
总而言之,白泽AIGPT镜像CODE在VS Code中的应用非常广泛,它为开发者提供了智能化的代码提示、自动完成、重构建议等功能,提高了开发效率和代码质量。随着技术的不断演进和白泽AIGPT的不断优化,我们可以期待在VS Code中更多智能化的功能和应用场景的出现。此外,通过与白泽AIGPT的互动,
人工智能术语翻译(四)
人工智能术语翻译第四部分,包括M、N、O、P开头的词汇!
【K210】K210学习笔记二——image
本文着重于 image 模块中的一个函数 find_blobs 也就是寻找色块的函数,因为多次比赛使用下来,给我的感觉就是 image 模块中最好用的便是寻找色块这个函数。其他的函数做的都比较差(个人感觉),比如识别形状的那几个函数,但其实找色块也是可以识别形状的。我这两年来做无人机题的识别都靠的是
基于JAVA和百度智能AI的车牌识别系统的设计与实现
用户信息:姓名、联系方式、邮箱、头像、简介、介绍等,支持随时修改;车辆评论:阅读车辆信息的时候,登录的用户,可以发表评论;资讯评论:阅读资讯的时候,登录的用户,可以发表评论;审核后的信息用户才可见。车辆评论:列出参与评论的车辆信息、评论内容、审核状态。
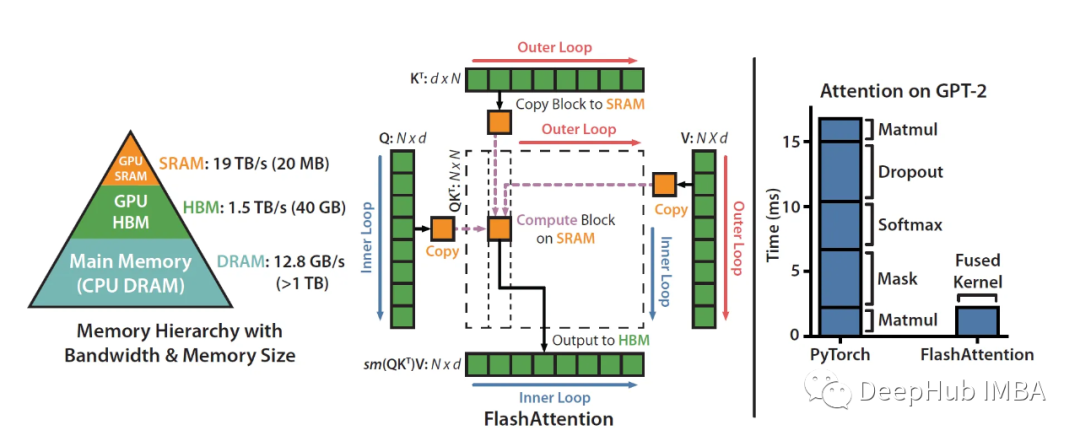
FlashAttention算法详解
这篇文章的目的是详细的解释Flash Attention,它无需任何近似即可加速注意力计算并减少内存占用
控制领域顶级学术会议有哪些?
控制领域是一个广泛的学科,其涵盖的研究范围包括系统控制、智能控制、自适应控制、优化控制等多个方面,本文提供一些控制领域顶级学术会议。
解决d2l包下载不了的问题
d2l包是李沐老师等人开发的《动手深度学习》配套的包,最初的时候,我并没有安装的想法,可在代码实现方面,常常要自己写函数实现同样的效果,且因为用于Tensor数据的一些转换,让人颇感吃力(比如显示图片)。所以,今天在尝试安装,具体的方法李沐老师也给出了,但我的频繁报错,所有大家不妨先去看看李沐老师提
基于spiceserver实现的GPU方案
本文通过实现win7、win10下的WDDM过滤驱动,以及将原先的虚机显卡设备驱动qxl驱动改装成PCI驱动,成功解决了spice对GPU直通、vGPU场景的支持问题,且支持不同厂商类型的GPU,不再过度依赖显卡厂商的支持,例如虚拟显示器、高效截屏。
【深入探究人工智能】:常见机器学习算法总结
本篇文章对一些常见的机器学习算法做了归纳总结



