Datawhale AI 夏令营 第四期 AIGC Task1
Datawhale AI 夏令营(第四期)Task 1 从零入门AI生图原理&实践链接里的教程非常详细,很适合小白上手,从使用服务器平台到配置环境再到跑模型,手把手教!具体细节我就不赘述了,参看教程即可,下面我主要就此次Task1任务学到了哪些内容作一个总结。我开始接触图像生成呢,就是在进入2020
深入理解变分图自编码器(VGAE):原理、特点、作用及实现
图神经网络(Graph Neural Networks, GNNs)在处理图结构数据方面展现出强大的能力。其中,变分图自编码器(Variational Graph Auto-Encoder, VGAE)是一种无监督学习模型,广泛用于图嵌入和图聚类任务。本文将深入探讨VGAE的原理、特点、作用及其具体
Ilya新公司获10亿美元融资;支付宝将发布AI独立App支小宝 | AI头条
前 OpenAI 联合创始人新公司获 10 亿美元融资支付宝将发布 AI 独立 App 支小宝Transformer 作者创业公司 Sakana.AI 获 1 亿美元 A 轮融资2024 外滩大会开幕,凯文・凯利谈 AI 时代三大趋势零一万物发布 Yi-Coder 系列模型微软 Win11 中发现国
AI学习指南深度学习篇-门控循环单元(GRU)简介
门控循环单元(GRU)作为一种灵活而高效的RNN变体,已经成为深度学习领域的重要组成部分。通过引入门控机制,GRU能够在长序列数据的学习中有效地缓解梯度消失和梯度爆炸的问题,并在多个应用场景中展现出了良好的性能。在实际应用中,GRU相对于传统的RNN和LSTM,具有更少的参数和更快的收敛速度,因此在
ViT论文详解
ViT是谷歌团队在2021年3月发表的一篇论文,论文全称是《AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》一张图片分成16x16大小的区域:使用Transformer进行按比例的图像识别。ViT是V
8 个超好用的 AI 图片无损放大工具推荐
设计师与创作者常遇困境:寻图耗时长,得图却不佳——分辨率低、尺寸错,加之紧迫Deadline,难觅替代或修复时间。此境虽非大患,却令设计人头疼不已。急时既不愿妥协次选,又无力耗时修缮,何解?答案是AI图片放大工具。科技进步,市场涌现众多自动优化图像、放大尺寸的利器,或鲜为设计界所知。今日特荐10款笔
ComfyUI插件:ComfyUI layer style 节点(三)
前言:学习ComfyUI是一场持久战,而ComfyUI layer style 是一组专为图片设计制作且集成了Photoshop功能的强大节点。该节点几乎将PhotoShop的全部功能迁移到ComfyUI,诸如提供仿照Adobe Photoshop的图层样式、提供调整颜色功能(亮度、饱和度、对比度等
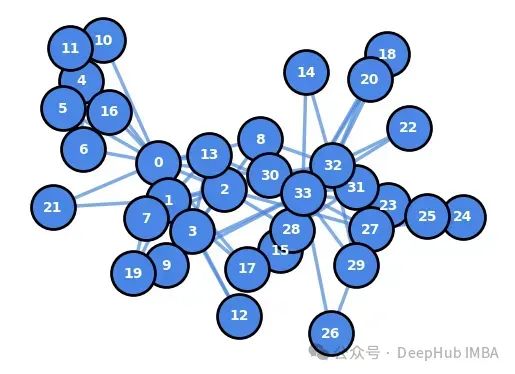
图特征工程实践指南:从节点中心性到全局拓扑的多尺度特征提取
本文将介绍如何利用NetworkX在不同层面(节点、边和整体图)提取重要的图特征。
第三届人工智能与智能信息处理国际学术会议(AIIIP 2024)
第三届人工智能与智能信息处理国际学术会议(AIIIP 2024)将于2024年10月25日-27日在中国-天津举行。新一代人工智能理论的快速发展为信息处理技术的提供了新方法,促进了智能信息处理的发展与应用。智能信息处理是信号与信息领域一个前沿、热点的具有广阔应用前景的研究领域。它以人工智能理论为基础
2023年自动化保研之路(已上岸南开大学ai院)
2023年9月29日,下午1点点击待录取确认,我的保研之旅终于结束啦,成功上岸南开大学人工智能学院!分享和记录一下自己的保研经历~
AI模型的未来之路:全能与专精的博弈与共生
在人工智能(AI)技术日新月异的今天,AI模型的设计与发展方向成为了业界内外广泛讨论的话题。特别是随着OpenAI等巨头公司不断推出新的全能型AI模型,如即将面世的“草莓”模型,这一讨论更加热烈。那么,AI模型是应该追求全面的“万能钥匙”,还是专注于某一领域的“匠人精神”?
LangChain实现文档检索和增强生成的示例
在这篇博客中,我们将介绍如何使用LangChain和Chroma来实现文档的检索和增强生成。我们将以一个具体的实例来展示这一过程,具体代码如下(修改自官方文档。
AAAI论文截稿
AAAI会议属于CCF-A类,CE-A类,2024年,AAAI投稿量显著增加至12100篇,总体录用率高达23.75%,创下了历史新高,反映出AAAI会议的持续吸引力和人工智能领域迅猛发展的势头,有学者估计2025年AAAI投稿量预估突破1.5w!费城(Philadelphia),是全球闻名的美国民
AI:250-YOLOv8结合ShuffleNetV2的轻量级优化与实战指南(附代码+修改教程)
ShuffleNetV2是一种通过分组卷积(Group Convolution)和通道洗牌(Channel Shuffle)技术来减少计算量和内存访问成本的轻量级网络。分组卷积:通过减少卷积核的计算量来降低整体的计算复杂度。通道洗牌:通过交换不同分组中的通道来促进信息流动,提升模型的表达能力。Shu
【全能型AI“草莓”来袭】探索未来AI市场的多元化与边界
总之,全能型AI“草莓”的推出,无疑是AI技术发展史上的一个重要里程碑。它展现了AI技术的无限可能性和广阔应用前景。然而,面对未来的挑战和机遇,我们仍需保持清醒的头脑,不断探索和创新,以实现AI技术的可持续发展和广泛应用。
腾讯云AI代码助手:智能编程的新篇章,大家的代码开发伙伴
随着人工智能技术的飞速发展,其在各个领域的应用也日益广泛。编程作为技术领域的核心,自然也迎来了AI的助力。陆陆续续的AI代码助手已向我们走来,像 github(也就是微软)发布github copilot,通义千问以及腾讯推出的腾讯云AI代码助手在帮助程序员进行代码开发方面都已取得了较大的成功。其中
【AI大模型】时代,周鸿祎回应360儿童手表问答不当,想了想,我是这么做的
使用七牛和美数(Meisu)来实现图片的合规审核,可以分为两步:首先将图片上传到七牛云,然后使用美数的内容审核服务对图片进行合规性检测
透明性和解释性AI:概念与应用
透明性AI指的是AI系统的操作过程、决策机制、数据流动和模型行为是可理解和可追踪的。换句话说,透明性AI使得人们可以清楚地看到AI系统是如何做出决策的,这一过程包括输入数据的处理方式、模型的内部计算过程、以及最终决策的产生机制。解释性AI是指AI系统不仅能够给出决策结果,还能够提供关于该决策如何产生
滴滴不再设总裁岗;央视网发文批“AI女友”;理想大裁员;OpenAI CEO:将取消“封口协议”
Mark Gurman评论说,苹果公司面对在人工智能领域的落后情况,最终必须摆脱合作方式,建立自己的聊天机器人,并将其深度集成到公司的产品中。火山引擎强调通过大规模使用量来不断优化模型,其大模型自上线以来,每天处理的token数量高达1200亿,生成图片3000万张,并在50多个场景中进行实践和验证
HookNet- 用于病理全切片图像的多分辨率语义分割模型|顶刊精析·24-08-08
今天分享的这篇文章是关于一种名为HookNet的新型语义分割模型,它专为病理学全切片图像设计,于2021年发表于《Med Image Anal》,目前IF=10.7。HookNet结合了编码器-解码器卷积神经网络的多个分支,通过不同分辨率的同心区域来捕获上下文信息和细节。这种模型通过一种称为“钩连”



