
Ollama 是一个专注于简化大规模机器学习模型开发的框架。它提供了一系列工具来帮助开发者轻松地定义、训练和部署大型语言模型。
优点:
• 提供了简洁的API,易于上手。
• 支持多种硬件加速选项,如GPU和TPU。
• 内置了许多预训练模型,方便快速开始实验。
缺点:
• 对一些高级功能支持有限,需要手动实现。
• 高并发性能受限,更新中
1、安装Ollama
Linux自动安装很简单,直接执行:
curl -fsSL https://ollama.com/install.sh | sh

手动安装,其他环境安装,参考:地址
成功界面如下: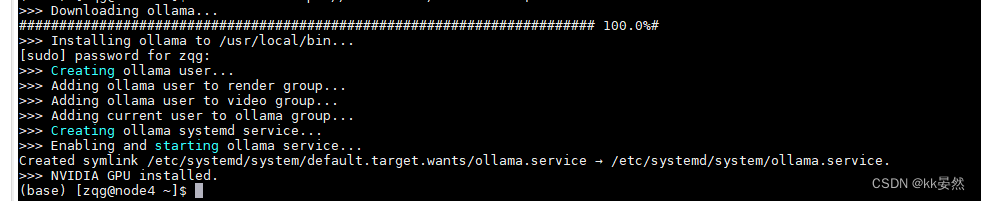
2、下载模型
ollama pull gemma2
公司环境,代理服务器不够稳定,无法从库中直接拉取。
报错,且暂时没找到解决方法,采用3、手动下载模型
3、手动下载模型
创建一个文件夹存放权重文件gguf(比较大),去hugging face下载gguf。放在新建文件夹。创建构造文件gemma-9b.modelfile(自由命名),内容FROM ./gemma-2-9b-it-Q4_K_L.gguf(实际权重存放位置)。完整结构如下: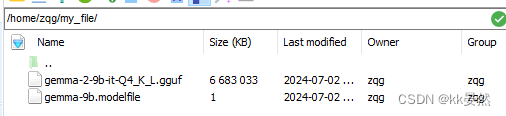
构造:
ollama create gemma-9b -f gemma-9b.modelfile
测试:
ollama run gemma-9b "hi who are u?"

4、使用调用
上面命令行调用方式是一种。
url访问调用:
curl http://localhost:11434/api/chat -d '{
"model": "gemma-9b",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'

python代码调用:
import requests
import json
def send_message_to_ollama(message, port=11434):
url = f"http://localhost:{port}/api/chat"
payload = {
"model": "gemma-9b",
"messages": [{"role": "user", "content": message}]
}
response = requests.post(url, json=payload)
if response.status_code == 200:
response_content = ""
for line in response.iter_lines():
if line:
response_content += json.loads(line)["message"]["content"]
return response_content
else:
return f"Error: {response.status_code} - {response.text}"
if __name__ == "__main__":
user_input = "why is the sky blue?"
response = send_message_to_ollama(user_input)
print("Ollama's response:")
print(response)

参考地址:https://zhuanlan.zhihu.com/p/688811216
openui:https://blog.csdn.net/spiderwower/article/details/138463635
使用参考:https://zhuanlan.zhihu.com/p/695040359
本文转载自: https://blog.csdn.net/yuuuuuuuk/article/details/140143975
版权归原作者 kk晏然 所有, 如有侵权,请联系我们删除。
版权归原作者 kk晏然 所有, 如有侵权,请联系我们删除。