基于YOLOv5的中式快餐店菜品识别系统
本文基于YOLOv5v6.1提出了一套适用于中式快餐店的菜品识别自助支付系统,综述了食品识别领域的发展现状,简要介绍了YOLOv5模型的历史背景、发展优势和网络结构。在数据集预处理过程中,通过解析UNIMIB2016,构建了一套行之有效的标签格式转换与校验流程,解决了YOLOv5中文件路径问题、标签
3D卷积神经网络详解
1 3d卷积的官方详解2 2D卷积与3D卷积1)2D卷积 2D卷积:卷积核在输入图像的二维空间进行滑窗操作。2D单通道卷积 对于2维卷积,一个3*3的卷积核,在单通道图像上进行卷积,得到输出的动图如下所示:2D多通道卷积 在之前的2D单通道的例子中,我们在一张图像上使用卷积核进行扫描,得
毕业设计-基于深度学习的视频目标检测
毕业设计-基于深度学习的视频目标检测:视频目标检测是为了解决每一个视频帧中出现的目标如何进行定位和识别的问题。相比于图像目标检测,视频具有高冗余度的特性,其中包含了大量的时空局部信息。随着深度卷积神经网络在静态图像目标检测领域的迅速普及,在性能上相较于传统方法显示出了非常大的优越性,并逐步在基于视频
DynaSLAM超详细安装配置运行ubantu20.0.4+opencv2.4.11+tensorflow1.4.0
DynaSLAM超详细安装配置运行ubantu20.0.4+opencv2.4.11+tensorflow1.4.0
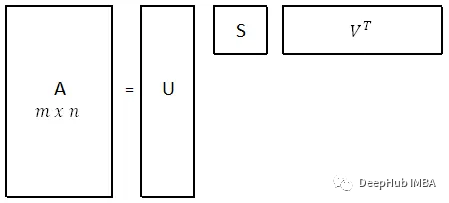
奇异值分解(SVD)和图像压缩
在本文中,我将尝试解释 SVD 背后的数学及其几何意义,还有它在数据科学中的最常见的用法,图像压缩。
【计算机视觉】目标检测—yolov5自定义模型的训练以及加载
yolov5如何自定义训练模型?如何加载模型并进行解读
目标检测算法——YOLOv5/YOLOv7改进之结合特征提取网络RFBNet(涨点明显)
计算机视觉——致力于目标检测领域科研Tricks改进与推荐 | 主要包括Backbone、Neck、Head、普通注意力机制、自注意力机制Transformer,各种IoU Loss损失函数、NMS及各类激活函数替换、轻量化网络改进、数据增强策略以及其他视觉顶会创新点改进等等。
Opencv学习之:将图片的值进行范围调整 cv2.normalize()
cv2.normalize()指定将图片的值放缩到 0-255 之间array = cv2.normalize(array,None,0,255,cv2.NORM_MINMAX)cv2.NORM_MINMAX :使用的放缩方式是 min_max 的方式其对应的原理是:x^=x−minmax−min∗
【半监督医学图像分割 2022 CVPR】S4CVnet 论文翻译
由于医学影像界缺乏高质量标注,半监督学习方法在图像语义分割任务中受到高度重视。为了充分利用视觉转换器(ViT)和卷积神经网络(CNN)在半监督学习中的强大功能,本文提出了一种基于一致性感知伪标签的自集成方法。我们提出的框架包括一个由ViT和CNN相互增强的特征学习模块,以及一个用于一致性感知目的的健
YOLOX改进之损失函数修改(上)
文章内容:如何在YOLOX官网代码中修改置信度预测损失环境:pytorch1.8损失函数修改内容:(1)置信度预测损失更换:二元交叉熵损失替换为FocalLoss或者VariFocalLoss(2)定位损失更换:IOU损失替换为GIOU、CIOU、EIOU以及a-IOU系列提示:使用之前可以先了解Y
非常详细的相机标定原理、步骤(一)
主要说明了 世界坐标系到相机坐标系,相机的外参与内参
基于卷积神经网络的人脸表情识别(JAFFE篇)
1.win10/11操作系统2.python3.7以上3.tensorflow2.4以上版本(2.0其它版本需要微调)4.内存12G,显卡4G以上(没有独显倒是也能跑...)(这个可爱的妹子就是JAFFE数据集中的图片)
多模态情感识别数据集和模型(下载地址+最新综述2021.8)
引用论文:Zhao, Sicheng, et al. “Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies.” arXiv preprint arXiv:2108.10152 (2021).PDF链
detectron2安装详细教程+demo测试
win10 下 detectron2 安装详细教程,手把手教你配置!!
CVPR 2022 | 最全25+主题方向、最新50篇GAN论文汇总
一顿午饭外卖,成为CV视觉前沿弄潮儿35个主题!ICCV 2021最全GAN论文汇总超110篇!CVPR 2021最全GAN论文梳理超100篇!CVPR 2020最全GAN论文梳理在最新的视觉顶会CVPR2022会议中,涌现出了大量基于生成对抗网络GAN的论文,广泛应用于各类视觉任务;下述论文已分类
【VisionMaster SDK开发】第一讲 环境配置篇(C#/C++)
VM二次开发常用于机器视觉应用中对界面、日志、产品管理、通讯或数据库等有特定需求的场合。相比于直接使用VM软件,VM二次开发更加灵活;相比于使用算子包开发,VM二次开发具有开发简单、开发效率高等优势,故成为视觉开发人员的首选开发方式。......
【论文笔记】IEEE | 一种新卷积 DSConv: Efficient Convolution Operator
我们引入了一种称为 DSConv(分布移位卷积)的卷积层变体,它可以很容易地替换到标准神经网络架构中,并实现更低的内存使用和更高的计算速度。DSConv 将传统的卷积核分解为两个组件:可变量化核 (VQK) 和分布偏移。通过在 VQK 中仅存储整数值来实现更低的内存使用和更高的速度,同时通过应用基于
PF-Net基于深度学习的点云补全网络
cvpr2020 PF-Net点云补全技术
一起自学SLAM算法:10.1 RTABMAP算法
连载文章,长期更新,欢迎关注:同前面介绍过的大多数算法一样,RTABMAP也采用基于优化的方法来求解SLAM问题,系统框架同样遵循前端里程计、后端优化和闭环检测的三段式范式。这里重点讨论RTABMAP两大亮点,一个亮点是支持视觉和激光融合,另一个亮点是内存管理机制。下面将从原理分析、源码解读和安装与
CutMix原理与代码解读
其中\(M\in\left\{0,1\right\}^{W\timesH}\)是一个binarymask表明从两张图中裁剪的patch的位置,和mixup一样,\(lambda\)也是通过\(\beta(\alpha,\alpha)\)分布得到的,在文章中作者设置\(\alpha=1\),因此\(l



