
一.前言
人脸表情识别依然是计算机视觉中的研究重点,那就意味着它还有水文章的可能性。本专题将专门讨论各种表情识别的研究方法,当然我们从最简单的单一卷积网络开始。本文中的代码直接复制到电脑端(python)或者服务器(ipython)上都可以**直接运行(ipython按顺序复制即可)**,如果有报错只需修改相应的版本或者留言交流。
软硬件配置介绍:
1.win10/11操作系统
2.python3.7以上
3.tensorflow2.4以上版本(2.0其它版本需要微调)
4.内存12G,显卡4G以上(没有独显倒是也能跑...)

(这个可爱的妹子就是JAFFE数据集中的图片)
二.数据预处理
在有些论文中,对于数据集的预处理不仅仅是导入之后做归一化处理。而是做特定的裁剪后只保留脸部,在这里我们不做特定的脸部裁剪(留到后续的文章)。JAFFE数据集的下载方式有很多种,你可以去其它的博客或者kaggle中白嫖。
我这里下载的JAFFE是以本地图片的形式保存的,如果你下载的是csv等其它格式,可以参考后续的博客。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
data_path = '../jaffe/'
data_dir_list = os.listdir(data_path)
# img_rows = 256
# img_cols = 256
# num_channel = 1
img_data_list = []
for dataset in data_dir_list:
img_list = os.listdir(data_path+'/'+dataset)
print('装载文件来自于文件'+'{}\n'.format(dataset))
for img in img_list:
input_img = cv2.imread(data_path+'/'+dataset+'/'+img)
input_img_resize = cv2.resize(input_img, (128, 128))
img_data_list.append(input_img_resize)
img_data = np.array(img_data_list)
img_data = img_data.astype('float32')
img_data = img_data/255
这里要注意的是在重构图像的时候,那个像素尺寸虽然可以自行调节,但也不要太小!否则你得到的将是一堆奇怪的马赛克,另外如果你想转灰度图像,可以在cv2.imread和cv2.resize中间添加相关代码。
接下来,我们进行手动分类和赋予每个类相应的表情名字,为了直观的表现,我这里用的是笨办法直接赋值。
num_classes = 7
num_of_samples = img_data.shape[0]
labels = np.ones((num_of_samples,), dtype='int64')
labels[0:29] = 0 # anger30,0-29
# print(len(labels[0:30]))
labels[30:58] = 1 # disgust,30-58
# print(len(labels[30:59]))
labels[59:90] = 2 # fear,59-90
# print(len(labels[59:91]))
labels[91:121] = 3 # happiness,91-121
# print(len(labels[91:122]))
labels[122:151] = 4 # neutral,122-152
# print(len(labels[122:152]))
labels[152:182] = 5 # sadness,152-182
# print(len(labels[152:183]))
labels[183:212] = 6
# print(len(labels[183:213]))
# print(len(labels[0:213]))
names = ['angry', 'disgust', 'fear', 'happy', 'neutral', 'sad', 'surprise']
def get_Label(id):
return ['angry', 'disgust', 'fear', 'happy', 'neutral', 'sad', 'surprise'][id]
最后一步,我们将标签转换为独热编码并将数据集分为训练集和测试集。额,关于劈叉数据集要实际看你最后改动的卷积状况了,一般来说0.1~0.3的效果较好一些。
from keras.utils import np_utils
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
Y = np_utils.to_categorical(labels, num_classes)
x, y = shuffle(img_data, Y, random_state=2)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2)
三.卷积网络的搭建
在单一的卷积神经网络结构中,卷积网络不仅肩负着提取表情特征的重任,还要对所提取的特征进行分类。本文构建的是一个自定义的卷积神经网络,由四个卷积快和两个全连接层组成。当然你可以将其替换成常见的VGG16等网络结构,或者在其基础上进行更深度的改编。一般来说,你如果可以在基本的网络中融入一些较为新颖的知识结构,足以水一篇一般的中文核心了。
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers import BatchNormalization
input_shape = img_data[0].shape
model = Sequential()
# 第一层
model.add(Convolution2D(8,(3,3), input_shape=input_shape, padding='same',strides=1))
# model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第二层
model.add(Convolution2D(16,(3,3), padding='same',strides=1))
# model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第三层
model.add(Convolution2D(32, (3,3),strides=1))
model.add(Activation('relu'))
# model.add(Dropout(0.25))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第四层
model.add(Convolution2D(64,(3, 3), strides=1))
model.add(Activation('relu'))
model.add(Dropout(0.25))
#全连接
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=["accuracy"])
model.summary()
这里简单说一下,不可以在同一层的卷积块中同时使用BN层和Dropout层,这会导致测试集损失压不住,最终使得准确率上不去。你可以通过summary查看网络结构(如下图所示),当然设定参数的时候不要忘记考虑运行程序的电脑所持有的配置!
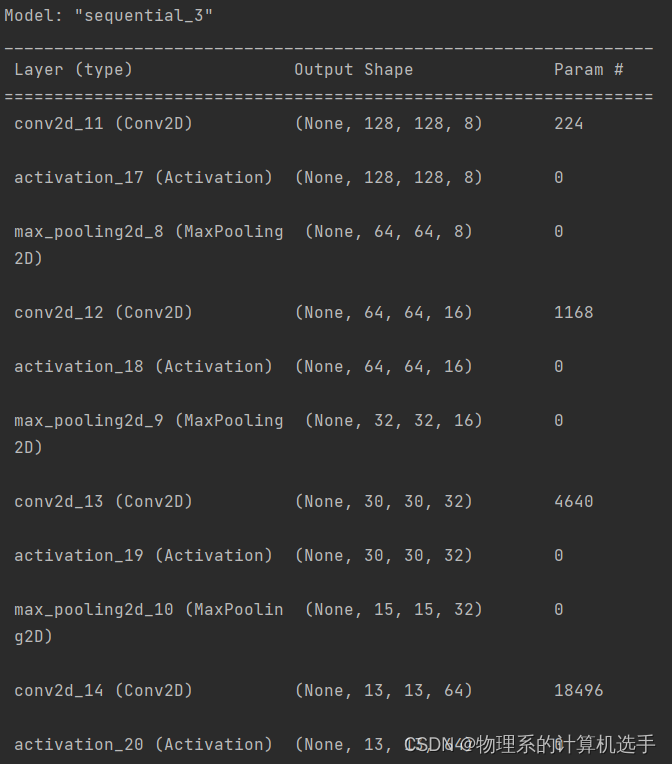
四.训练前的准备工作
首先,我们建立一个记录来记载训练过程中的损失和准确率的数据。同时定义一个h5文件来保存训练好的权重,这样在之后做成界面形式的时候就可以直接调用了。
from keras import callbacks
# 用CSV形式保存训练数据
filename='model_train_new.csv'
filepath='ZhaWen001.h5'
csv_log=callbacks.CSVLogger(filename, separator=',', append=False)
checkpoint = callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [csv_log,checkpoint]
由于JAFFE是一个小样本的数据集,在训练之前加一个数据增强来扩充那小的可怜的样本数据。(在后面的文章中,我会尝试用元学习中处理小样本的网络来尝试这个数据集的表情识别。)
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=5,
width_shift_range=0.01,
height_shift_range=0.01,
horizontal_flip=True,
shear_range=0.1,
zoom_range=0.1
).flow(X_train, y_train, batch_size=10)
fuck = ImageDataGenerator( rotation_range=5,
width_shift_range=0.01,
height_shift_range=0.01,
horizontal_flip=True,
shear_range=0.1,
zoom_range=0.1).flow(X_test, y_test, batch_size=10)
五.开始训练
直接model.fit,冲就完事了!(3050大概需要训练1分钟,迪迦感受光!!)
hist = model.fit(datagen, epochs=100, verbose=1, validation_data=fuck,
callbacks=callbacks_list)
六.训练结果展示与测试
import matplotlib.pyplot as plt
train_loss=hist.history['loss']
val_loss=hist.history['val_loss']
train_acc=hist.history['accuracy']
val_acc=hist.history['val_accuracy']
epochs = range(len(train_acc))
plt.plot(epochs,train_loss,'r', label='train_loss')
plt.plot(epochs,val_loss,'b', label='val_loss')
plt.title('train_loss vs val_loss')
plt.legend()
plt.figure()
plt.plot(epochs,train_acc,'r', label='train_acc')
plt.plot(epochs,val_acc,'b', label='val_acc')
plt.title('train_acc vs val_acc')
plt.legend()
plt.figure()
下面是在ipython运行的结果图,这可以为后续的模型修改提供思路。
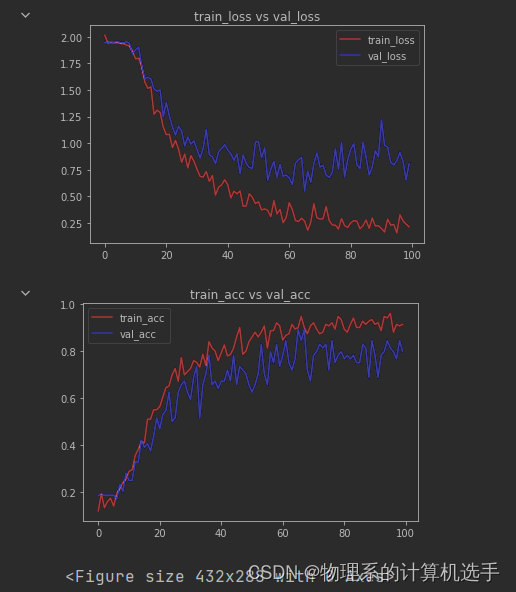
可以看出测试集的准确率大概在80%左右,从60轮之后损失已经不在下降了,该模型调参之后最好的效果大概在90%左右,之后需要添加其它的东西,比如说注意力机制等。不管那么多,我们先用这个模型训练好的权重来测试真实的人脸表情。
test_data_list=[]
test_img=cv2.imread('men_happy.jpg')
test_img_resize=cv2.resize(test_img,(128,128))
test_data_list.append(test_img_resize)
test_data = np.array(test_data_list)
test_data = test_data.astype('float32')
test_data = test_data/255 # 归一化处理
# 输出结果
# results = model.predict_classes(testimg_data)
predict_3 = model.predict(test_data)
print(predict_3)
predict_3_class = np.argmax(predict_3, axis=1)
print(predict_3_class)
plt.imshow(test_img,cmap=plt.get_cmap('Set2'))
plt.gca().get_xaxis().set_ticks([])
plt.gca().get_yaxis().set_ticks([])
plt.xlabel('prediction = %s' % get_Label(predict_3_class[0]), fontsize=25)
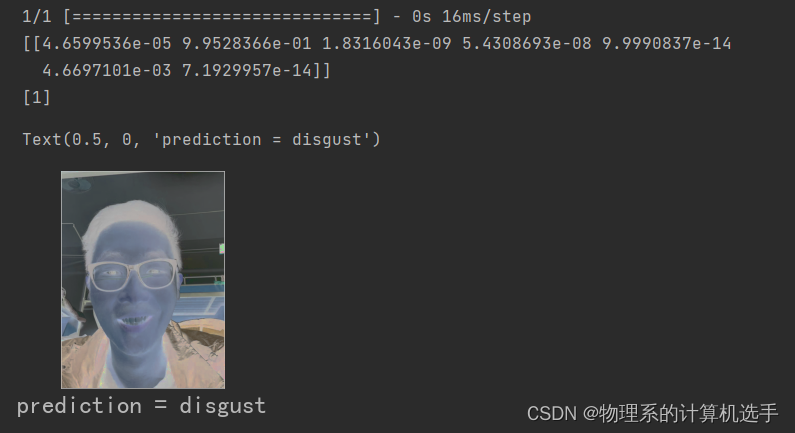
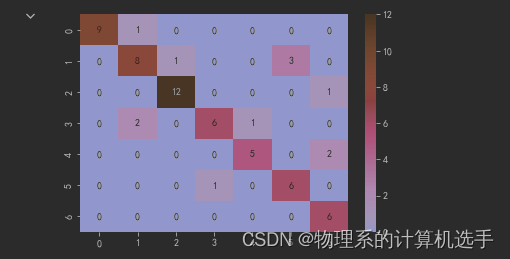
但是从测试结果看,模型将高兴识别成了厌恶,这.....,输出了一下验证集的热力图,我们可以看见9张高兴竟然有三张是识别成错误的类!(后来发现不带眼镜后的识别正常了,好欸!)
本文转载自: https://blog.csdn.net/qq_40981869/article/details/127190760
版权归原作者 物理系的计算机选手 所有, 如有侵权,请联系我们删除。
版权归原作者 物理系的计算机选手 所有, 如有侵权,请联系我们删除。