
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的视频目标检测
课题背景和意义
视频目标检测是为了解决每一个视频帧中出现的目标如何进行定位和识别的问题。相比于图像目标
检测,视频具有高冗余度的特性,其中包含了大量的时空局部信息。随着深度卷积神经网络在静态图像目标检测领域的迅速普及,在性能上相较于传统方法显示出了非常大的优越性,并逐步在基于视频的目标检测任务上也发挥了应有的作用。但现有的视频目标检测算法仍然面临改进与优化主流目标检测算法的性能、保持视频序列的时空一致性、检测模型轻量化等关键技术的挑战。视频目标检测已成为众多的计算机视觉领域学者追逐的热点,将来会有更加高效、精度更高的算法被相继提出,其发展方向也会越来越好。视频目标检测在无人驾驶、视频监控和物联网等领域中一项重要的任务,与静态图像的目标检测相比更具挑战性和实用性。与静态图像目标检测不同的是,目标在视频中是动态变化的,即其自身属性诸如外观、形状、尺寸会动态地改变,检测过程中视频序列需要在时间和空间维度保持一致以防检测目标丢失成为了视频目标检测任务的研究难点。
实现技术思路
** 对近几年基于深度学习的视频目标检测工作进行了梳理和总结,将其分为以下几个核心问题:**
(1)目标在视频序列中的位置变化会产生相应的运动信息,而通过这些运动信息便可以进行目标
检测。(2)检测算法首先对视频序列中每一个视频帧进行检测,然后应用相关的跟踪算法对目标检测框进行跟踪,最后将跟踪得到的结果与检测结果进行对比修正以此达到视频目标检测的目的。 (3)视频目标检测模型的轻量化。(4)检测模型的跨界问题。(5)保持目标在视频序列中的时空一致性。具体的挑战可分为以下五类:运动模糊、虚焦、遮挡、外观变化、外观变化。

一、基于深度学习的视频目标检测
基于运动信息的视频目标检测算法
1)光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻物体之间的运动信息的一种方法。

2)DFF 的网络结构大致可分为特征提取网络和检测网络。特征网络只作用于关键帧的特征提取,利用光流将关键帧的特征聚集到非关键帧,获得非关键帧的特征图,最后将这些特征图送入检测网络进行计算来获得结果。
3)FGFA 主要由特征提取和特征融合两大模块组成。首先是通过光流网络对当前帧与相邻帧提取光流,并将提取到的光流与当前帧的特征组合在一起, 组合完成后将组合后的特征与相邻帧的多个特征进行聚合。

4)在THP中提出了使用稀疏递归聚合的方法估计特征网络, 特征聚合只在挑选出来的关键帧上进行,即用上一个关键帧的特征来增强当前关键帧的特征,增强后的关键帧再去增强下一个关键帧,如此递归进行。

基于检测和跟踪的视频目标检测算法
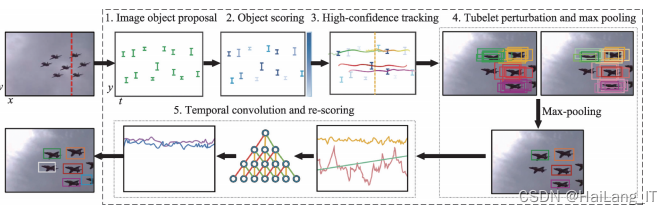
1)T-CNN
解决视频中目标的时空一致性问题最直接的方法就是进行跟踪,这其中具有代表性的工作便是 T-CNN(tubelets with convolutional neural networks)。 其核心思想是用跟踪算法学习视频序列中目标变化 的时间信息,用检测算法学习单帧图像中目标的空间信息,之后将二者有机结合起来提升视频目标检测的性能。T-CNN 提出了一种目标检测和跟踪的多阶段框架,该框架分别由管道提取模块、管道分类和重记分模块三部分组成。
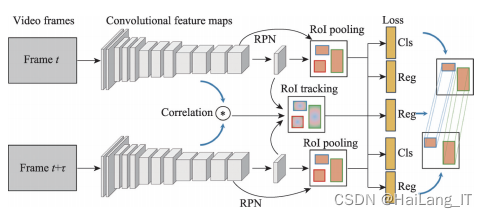
2)D&T
D&T(detect to track and track to detect)通过使用一个简单的卷积网络模型——ConvNet 在视频序列中实现了多目标的跟踪和检测,设计了一个新颖的损失函数,里面既包含了单帧检测的多任务损失,也包含了多帧间的跟踪回归损失;引入了同一目标在不同帧中同时出现时的相关特征来增强跟踪效果。
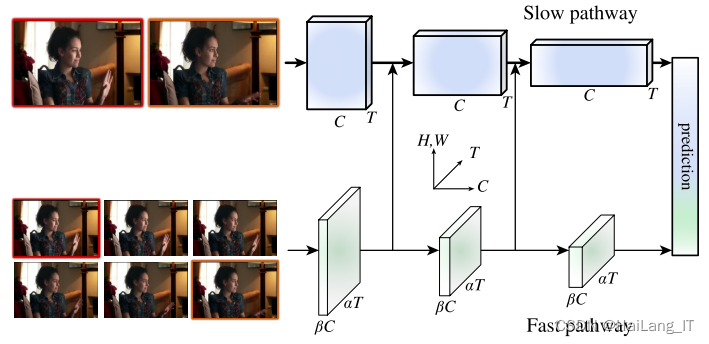
视频目标检测模型的轻量化
尽管视频目标检测模型已经成功部署在桌面GPU(graphics processing unit)上,但是距离移动端的发展还尚有一段距离。通过使用 Slownetwork和 Fastnetwork分别提取不同帧的特征,减少计算冗余,使用 Conv-LSTM(convolutional long short-term memory)特征融合后生成检测框来实现检测的实时性,并通过基于Q-learning学习自适应交替策略,取得速度和准确率的平衡,在移动端设备上达到了当时视频目标检测已知的最快速度。
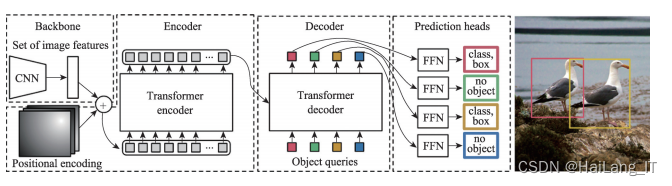
跨界模型在视频目标检测中的应用
Transformer从分类、检测、分割等各个任务上所替代。Transformer 以其优越的性能被越来越多地用来改进各种视觉任务的算法模型。把Transformer用到了目标检测任务中,其效果可以和Faster R-CNN相媲美,即 Transformer 的视觉版本——DETR(detection transformer)DETR 的出现从 根本上改变了 CNN 模型的算法架构,基于 Trans-former 的端到端目标检测,没有 NMS(non-maximum suppression)后处理步骤,真正的没有 anchor,其性能 对标Faster R-CNN。
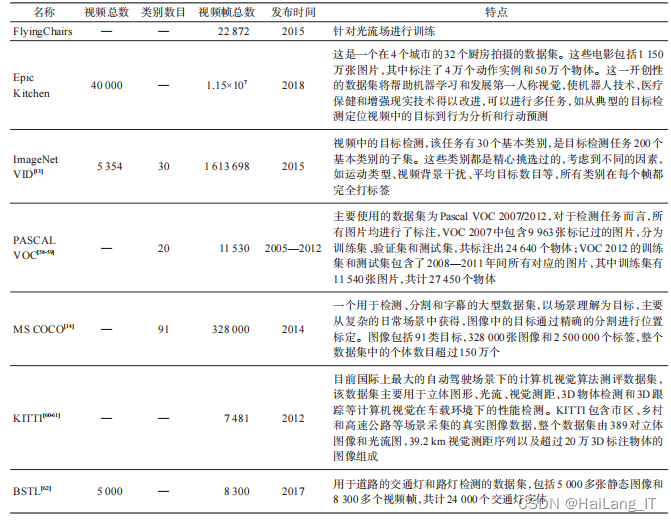
二、 相关数据集
数据集不仅为衡量和比较视频目标检测算法的性能提供了依据,同时也为视频目标检测算法越
来越高效和越来越实用提供了强大的支撑力。视频目标检测中所使用的通用数据集主要包括FlyingChairs、 Epic Kitchen 和 ImageNet VID 等。
三、算法性能比较
目标检测中的性能指标主要包括精确率(preci-sion rate)、召回率(recall rate)、平均精度(average pre-cision,AP)、平均精度均值(mean average precision, mAP)和速度(frame per second,FPS)。通过对相关挑战中的很多算法以及相应的数据集和目标检测中的性能介绍,下面从基础检测器、主干网络、数据集、检测精度等相关信息进行对比分析。


由以上可知(1)随着深度学习在静态图片的目标检测逐步延伸到视频的目标检测,使得视频目标检测的质量有了很大的提升。(2)在视频目标检测的算法的相关改进中,由于光流的计算费时费力,在后续的发展中光流的作用被逐渐弃用(3)在视频目标检测算法的发展过程中,以追求精度提升的检测算法中,其主干网络大都采用ResNet 系列的网络架构。(4)加入了 NMS 后处理的方法比原来没有加入 的算法精度都有了不同程度的提升;(5)随着算法性能的不断提高,检测精度不断提升,在基于光流的算法中,如RDN、OGEMN、SELSA在ImageNet VID数据集上将检测精度提上了一个新的高度
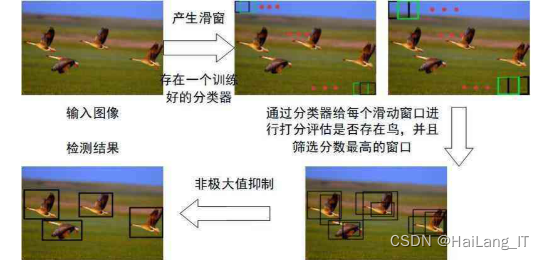
实现效果图样例
最先进的目标检测算法主要基于深度神经网络,基于深度学习的视频目标检测:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。