2024年AI辅助研发:科技创新的引擎
2024的AI辅助研发的扩展相关信息
AI论文查重率怎么降低?七大策略助你突破困境
通过遵循这些策略,我们可以更好地应对AI论文查重率的问题,推动学术研究的发展和创新。如何有效降低AI论文的查重率,确保学术研究的原创性和创新性,成为了研究者和学者关注的焦点。通过正确引用他人的观点和数据,可以确保论文的权威性和可信度,同时避免被查重软件误判为重复内容。通过结合具体案例和实践经验,可以
一文了解OpenAi的发展历史
同时,OpenAI也将人工智能的安全性和可控性视为至关重要的问题,并通过自身的研究和倡导,推动全球人工智能的健康、安全和可持续发展。2019年,OpenAI推出了名为GPT-3的最新版本的语言模型,该模型的规模和能力远超以往,可以生成具有逻辑性和创造性的语言文本,被认为是人工智能领域的重大突破。20
AI入门之深度学习:基本概念篇
神经网络的每一个权重系数都是空间中的一个自由维度,为了对损失表面有更直观的认识,可以将沿着二维损失表面的梯度下降可视化,但你不可能将神经网络的真实训练过程可视化,因为无法用人类可以理解的方式来可视化1 000 000维空间。本例中的模型包含2个Dense层,每层都对输入数据做一些简单的张量运算(re
论文AI率怎么降:揭秘有效降低AI辅助写作比例的策略
综上所述,降低论文AI率需要我们从多个方面入手,包括明确写作目标与内容定位、提升作者的学术素养与写作能力、合理利用AI辅助工具、强化原创性意识与规范引用、建立论文审核机制与反馈循环、加强学术道德教育与监管以及利用技术手段降低AI辅助比例。只有这样,我们才能确保学术论文的质量和原创性,推动学术研究的健
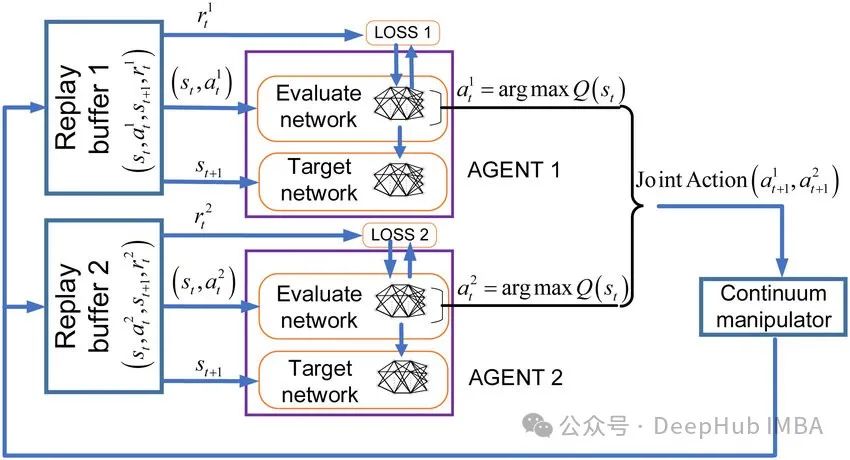
MADQN:多代理合作强化学习
在本文中我们将只关注合作多代理学习的问题,不仅因为它在我们日常生活中更常见,而对于我们学习来说也相对的简单一些。
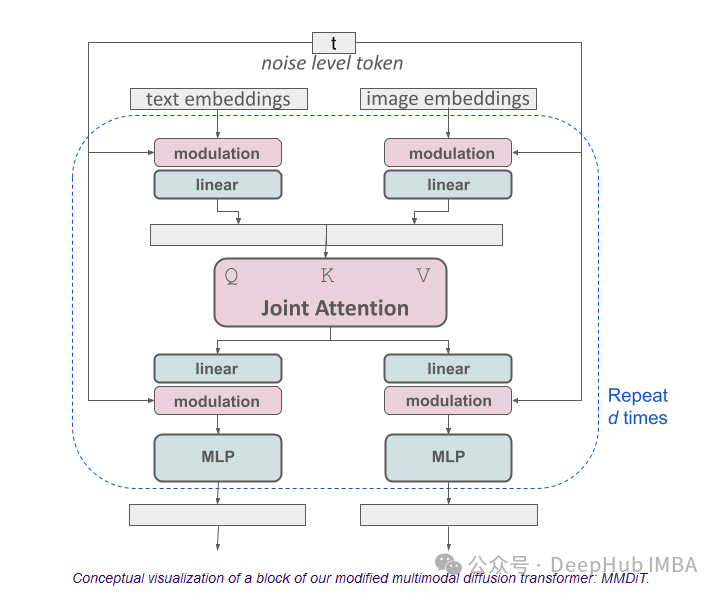
2024年3月最新的深度学习论文推荐
现在已经是3月中旬了,我们这次推荐一些2月和3月发布的论文。
免费ai论文生成器在线(ai论文生成器免费版)
AIPaperPass是AI原创论文写作平台,免费千字大纲,5分钟生成3万字初稿,提供答辩汇报ppt、开题报告、任务书等,40篇真实中英文知网参考文献,重复率超过10%包退费。AIPaperPass操作流程步骤:第一步、选择专业方向及拟定论文题目,第二步、AI智能生成论文大纲,第三步、下载论文文件。
AI论文速读 | TimeXer:让 Transformer能够利用外部变量进行时间序列预测
最近的研究已经展现了时间序列预测显着的性能。然而,由于现实世界应用的部分观察性质,仅仅关注感兴趣的目标,即所谓的内部变量(endogenous variables),通常不足以保证准确的预测。值得注意的是,一个系统通常被记录为多个变量,其中外部序列可以为内部变量提供有价值的外部信息。因此,与之前成熟
论文已提交,如何添加或修改作者名单?(附信件模板)
不管这篇论文是已经提交在审稿阶段,还是文章已被接受在Proof阶段,再或者是已经在线发表了,都可以尝试联系期刊进行作者名单修改。在这封信中,应详细说明需要进行变更的原因,并请求编辑对这一变更予以批准。科研论文变更作者名单是一件非常严肃的事情,大家投稿之前一定要再三确认好作者名单,避免出现更改作者的情
Labelme加载AI(Segment-Anything)模型进行图像标注
labelme是使用python写的基于QT的跨平台图像标注工具,可用来标注分类、检测、分割、关键点等常见的视觉任务,支持VOC格式和COCO等的导出,代码简单易读,是非常利用上手的良心工具。(2)在labelme/labelme/文件夹下自建一个文件夹model_file。(3)依次输入以下几个网
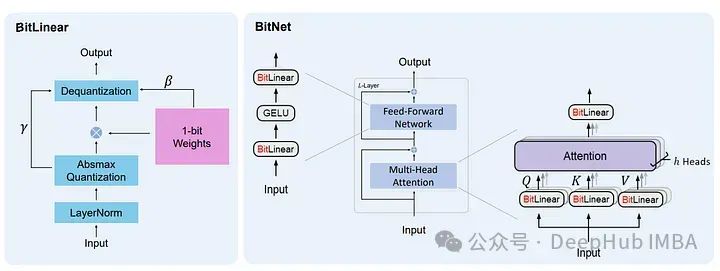
从16-bit 到 1.58-bit :大模型内存效率和准确性之间的最佳权衡
在本文中,我们将通过使用GPTQ对Mistral 7B、Llama 27b和Llama 13B进行8位、4位、3位和2位量化实验,还要介绍一个大模型的最新研究1.58 Bits,它只用 -1,0,1来保存权重
人工智能、机器学习、深度学习的关系、智能分类的执行流程、IK分词器的使用
人工智能与机器学习人工智能与机器学习谈谈人工智能人工智能),英文缩写为AI。它是研究开发用于模拟延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语
人工智能的深度学习如何入门
其中,Python是最受欢迎的编程语言之一,在深度学习领域有着广泛的应用和丰富的库支持。在实践过程中,遇到的问题和挑战可以促使自己学习更多的知识,并提高自己的解决问题的能力。要保持对最新的研究成果和技术动态的了解,并不断学习和掌握新的知识和技能。首先,了解深度学习的基本概念是入门的第一步。在深度学习
什么是上游任务、下游任务?
下游任务:真正想要解决的任务。如果你想训练一个网络无论是生成任务还是检测任务,你可能会使用一些公开的数据集进行训练,例如coco,imagenet之类的公共数据集进行训练,而这些数据集可能不会很好完成你真正想完成的内容,这就意味着在解决的实际问题的数据集上,要微调这个预训练模型,而这个任务称为下游任
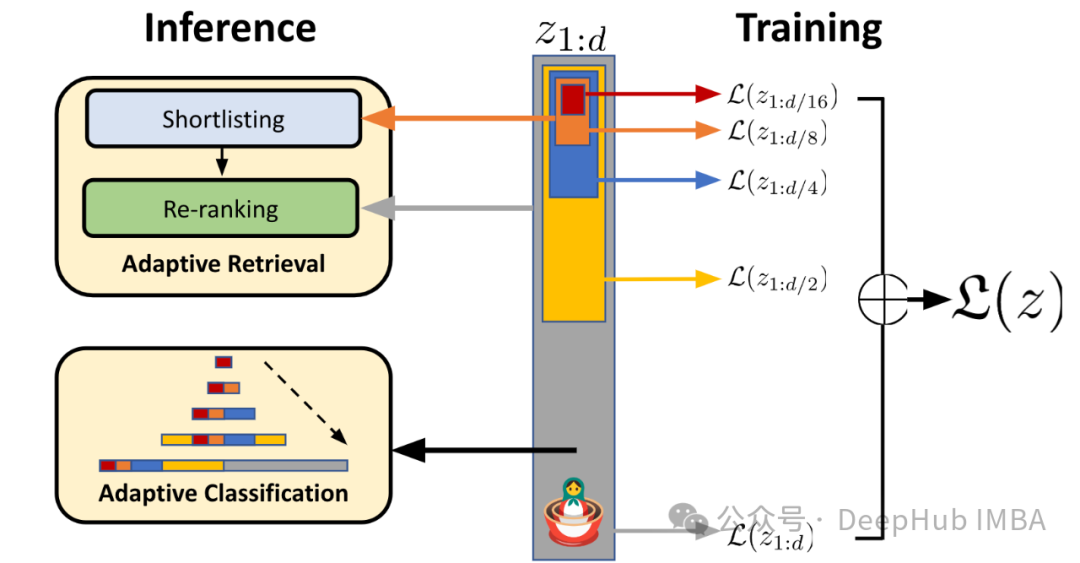
Nomic Embed:能够复现的SOTA开源嵌入模型
Nomic-embed-text是2月份刚发布的,并且是一个完全开源的英文文本嵌入模型,上下文长度为8192.该模型有137M个参数在现在可以算是非常小的模型了。
AI大模型在金融科技领域的应用与创新
1.背景介绍随着人工智能技术的不断发展,人工智能大模型在各个领域的应用也越来越广泛。金融科技领域也不例外。在这篇文章中,我们将探讨 AI 大模型在金融科技领域的应用与创新。金融科技领域的发展主要集中在金融服务、金融风险管理、金融市场和金融产品等方面。随着数据规模的增加,计算能力的提升以及算法的创新,
【探索AI】十八 深度学习之第3周:卷积神经网络(CNN)(二)-常见的卷积层、池化层与全连接层
全连接层(Fully Connected Layer)是卷积神经网络(CNN)中的一个关键组件,它通常位于网络的末端,负责将前面层提取的特征整合并映射到最终的输出结果上。全连接层的作用是将前面层(如卷积层和池化层)提取的特征进行加权求和,并通过激活函数得到最终的输出结果。
sora参考文献整理及AI论文工作流完善(更新中)
OpenAI最新发布的Sora效果惊为天人,除了阅读研究原文(openai.com/research/video-generation-models-as-world-simulators)之外,其引用的32篇参考文献也是了解对应技术路线的重要信息。借此机会,也顺便探索一下整个AI论文的工作应该是什
AI引爆算力需求,思腾推出支持大规模深度学习训练的高性能AI服务器
可见AIGC技术对社会的变革性影响,同时也引爆了AI行业对训练和推理的大模型需求。英伟达是行业翘楚,而A800又是英伟达的明星产品,其算力更是行业望其项背的存在,思腾合力IW4221-8GRs这款产品,任意两个 GPU 之间可以直接进行数据 P2P 交互,GPU 间 P2P 通信速率为 400GB/



