Real-ESRGAN超分辨网络
超分辨率论文阅读—Real-ESRGAN(2021ICCV) - 知乎Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data-----阅读阶段_MengYa_DreamZ的博客-CSDN博客虽然
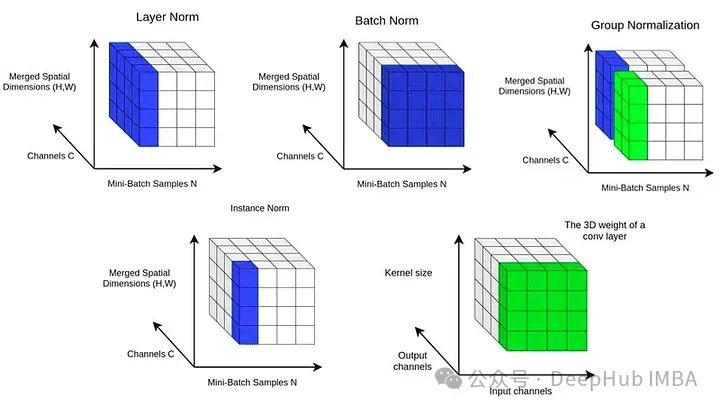
归一化技术比较研究:Batch Norm, Layer Norm, Group Norm
本文将使用合成数据集对三种归一化技术进行比较,并在每种配置下分别训练模型。记录训练损失,并比较模型的性能。
AI深度学习部署全记录
AI深度学习部署的全记录,给黑暗中前行的人一束烛光
毕业设计:基于深度学习的森林火灾预测系统 人工智能 算法
毕业设计:基于深度学习的森林火灾预测系统通过引入深度学习算法对森林环境数据进行高效处理,实现了对火灾发生的精准预测。该系统结合了计算机视觉技术和深度学习算法,对森林图像、气象数据等多源信息进行融合分析,有效提高了预测准确率。此外,该系统还具备良好的可扩展性和实时性,能够为森林火灾预警和防控提供有力支
AI模型部署实战:利用CV-CUDA加速视觉模型部署流程
随着深度学习技术在计算机视觉领域的发展,越来越多的AI算法模型被用于目标检测、图像分割、图像生成等任务中,如何高效地在云端或者边缘设备上部署这些模型是工程师迫切需要解决的问题。一个完整的AI模型部署流程一般分为三个阶段:预处理、模型推理、后处理,一般情况下会把模型推理放在GPU或者专用的硬件上进行处
基于深度学习的AI生成式人脸图像鉴别
AIGC(AI内容生成)技术的快速发展确实为创作者提供了高效生产力工具,但同时也引发了一些问题和挑战。这些技术可以生成以假乱真的图像、视频换脸等,给不法分子提供了滥用的机会。其中,一些不法分子可能利用AIGC技术制造虚假新闻、违反版权、绕过活体身份验证、散布谣言和诽谤他人、进行敲诈勒索等非法活动,以
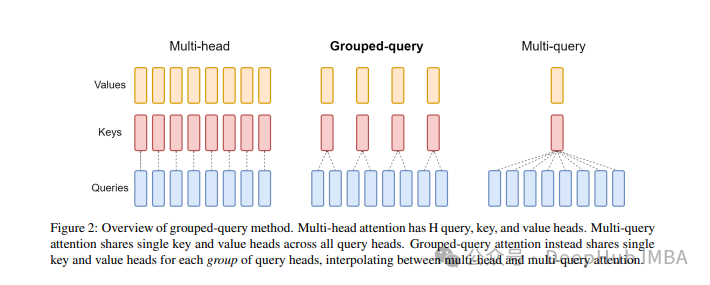
大模型中常用的注意力机制GQA详解以及Pytorch代码实现
分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和多头注意力 (MHA) 之间进行插值的方法,它的目标是在保持 MQA 速度的同时实现 MHA 的质量。
论文查重部分都包括哪些内容 神码ai
在学术领域,论文查重是保证学术诚信和论文质量的重要环节。随着互联网的发展,许多论文查重网站应运而生,提供了便捷的查重服务。这些查重网站一般使用的都是伪原创技术,如小发猫伪原创或小狗伪原创等软件,进行论文的检测。那么,论文查重部分都包括哪些内容呢?大家好,今天来聊聊论文查重部分都包括哪些内容,希望能给
想训练AI模型,实验室GPU显存不够怎么办
一般的高校实验室,的确是可能存在显存不足的情况,特别是全量训练或者微调时问题尤为突出。此时想让实验室新购置设备更是遥遥无期,估计开会还没讨论出结果,好多炼丹侠的deadline就到了。
AI大预言模型——ChatGPT在地学、GIS、气象、农业、生态、环境应用
AI大预言模型——ChatGPT在地学、GIS、气象、农业、生态、环境应用
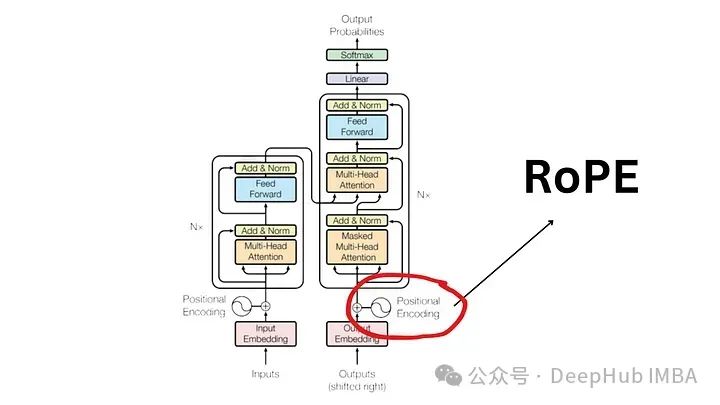
大语言模型中常用的旋转位置编码RoPE详解:为什么它比绝对或相对位置编码更好?
旋转位置嵌入是最先进的 NLP 位置嵌入技术。大多数流行的大型语言模型(如 Llama、Llama2、PaLM 和 CodeGen)已经在使用它。在本文中,我们将深入探讨什么是旋转位置编码,以及它们如何巧妙地融合绝对位置嵌入和相对位置嵌入的优点。
AI:155-基于深度学习的股票价格预测模型
AI:155-基于深度学习的股票价格预测模型股票价格预测一直是金融领域中备受关注的话题之一。随着人工智能技术的不断发展,特别是深度学习的兴起,利用神经网络进行股票价格预测成为了一种热门方法。本文将介绍如何利用深度学习构建股票价格预测模型,并提供一个简单的代码实例。
AI:152- 利用深度学习进行手势识别与控制
AI:152- 利用深度学习进行手势识别与控制随着人工智能技术的不断发展,深度学习在手势识别与控制领域的应用越来越广泛。本文将介绍深度学习在手势识别与控制中的原理和方法,并提供一个基于深度学习的手势识别与控制的简单代码示例。人工智能技术的快速发展为人们带来了许多新的应用场景,其中之一便是手势识别与控
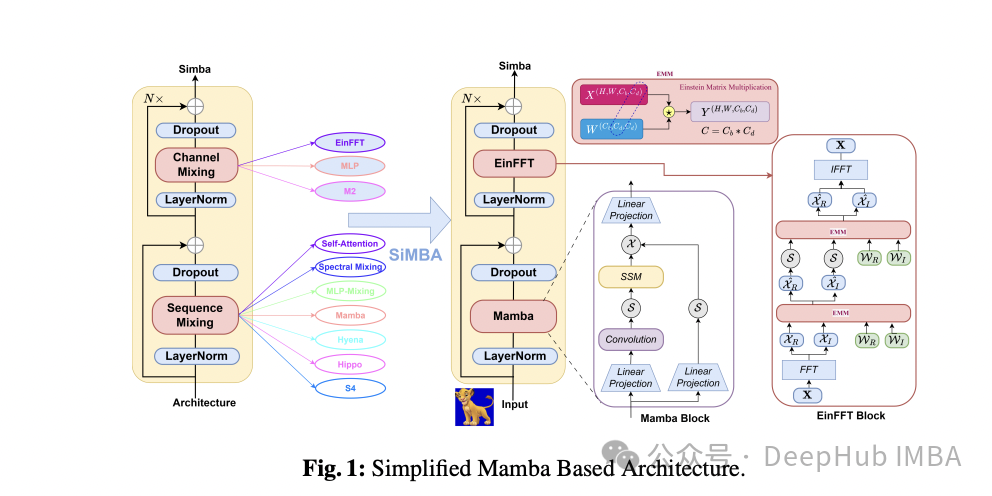
SiMBA:基于Mamba的跨图像和多元时间序列的预测模型
这是3月26日新发的的论文,微软的研究人员简化的基于mamba的体系结构,并且将其同时应用在图像和时间序列中并且取得了良好的成绩。
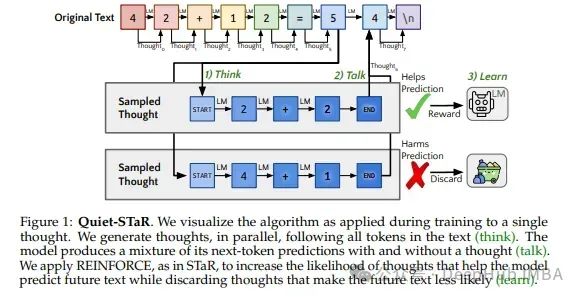
Quiet-STaR:让语言模型在“说话”前思考
本文将介绍一篇3月的论文Quiet-STaR:这是一种新的方法,通过鼓励LLM发展一种“内心独白”的形式来解决这一限制,这种基本原理生成有助于LLM通过完成任务或回答问题所涉及的步骤进行推理,最终获得更准确和结构良好的输出。
入局AI时代,先从了解AI工具入手(200 个免费的 AI 工具分享)
Clipdrop - AI 驱动的插件程序,帮助你从计算机或移动设备快速剪辑和编辑图像 ,在几分钟内将一流的 AI 集成到您的应用程序中(PS、Figma、IOS、安卓)。Character.io - 一种使用 AI 从用户照片生成自定义头像的工具 (https://characterio.neel
【Transformer系列(1)】encoder(编码器)和decoder(解码器)
一文带你学会encoder-decoder框架

使用MergeKit创建自己的专家混合模型:将多个模型组合成单个MoE
在本文中,我们将详细介绍MoE架构是如何工作的,以及如何创建frankenmoe。最后将用MergeKit制作自己的frankenMoE,并在几个基准上对其进行评估。
详解AI Agent系列|(1)AI Agent到底是什么
从high-level来简明概括地介绍一下AI Agent
进阶课5——人工智能数据分类
数据类型是指数据在计算机中的存储方式,根据数据的不同特征和表示方式,可以将数据分为不同的类型。在IT领域中,随着数字化信息技术的应用不断扩大,数据的种类和格式也越来越多。从人机交互数据类型的视角来看,人工智能数据主要分为文本数据、语音数据、图像数据和视频数据等几大类别。



