
paper:MobileOne: An Improved One millisecond Mobile Backbone
**official implementation:https://github.com/apple/ml-mobileone **
third-party implementation:mmpretrain/mobileone.py at main · open-mmlab/mmpretrain · GitHub
前言
针对移动设备的高效深度学习架构的设计和部署已经取得了很大进展,很多轻量模型在减少浮点操作(floating-point operations, FLOPS)和参数量(parameter count)的同时不断提高精度。但是就延迟latency而言,这些指标没有很好的与模型的效率关联起来,像FLOPs这样的指标没有考虑到内存访问成本memory access cost和模型并行的程度degree of parallelism,而后者在推理时可能会对延迟产生很大的影响。参数量也与延迟没有很好的相关性,比如共享参数可以减小模型大小但会使FLOPs增大。此外,像skip-connections和braching这种参数量小的操作会产生大量的内存访问成本。
本文的目标是找到影响延迟的关键瓶颈并进行优化,降低延迟成本同时提高模型精度。优化optimization是另一个瓶颈特别是在训练较小的网络时,这可以通过解耦训练和推理的网络结构来缓解,即结构重参数化技术。此外通过在训练过程中动态的减缓正则化进一步缓解了优化瓶颈,防止已经很小的模型被过度正则化。
基于找到的结构和优化瓶颈,本文设计了一个新的网络结构MobileOne,其变体在iPhone12上以小于1ms的延迟获得了SOTA的精度。MobileOne和之前的结构重参数化模型的关键区别在于引入了过参数化分支over-parameterization branch和模型缩放策略。
本文的贡献
- 本文设计了MobileOne,这是一种在移动设备上延迟小于1 ms内的新架构,并在高效的模型架构中实现了最先进的图像分类精度。该模型的表现也可以推广到桌面CPU。
- 本文分析了激活activations和分支结构branching中的性能瓶颈,这导致了移动设备上的高延迟成本。
- 本文分析了结构重参数化和动态减缓正则化的影响,这两者结合有助于缓解训练小模型时遇到的优化瓶颈。
- 本文设计的MobileOne,可以很好的推广到其它下游任务,比如目标检测和语义分割,性能优于此前的SOTA模型。
方法介绍
Metric Correlations
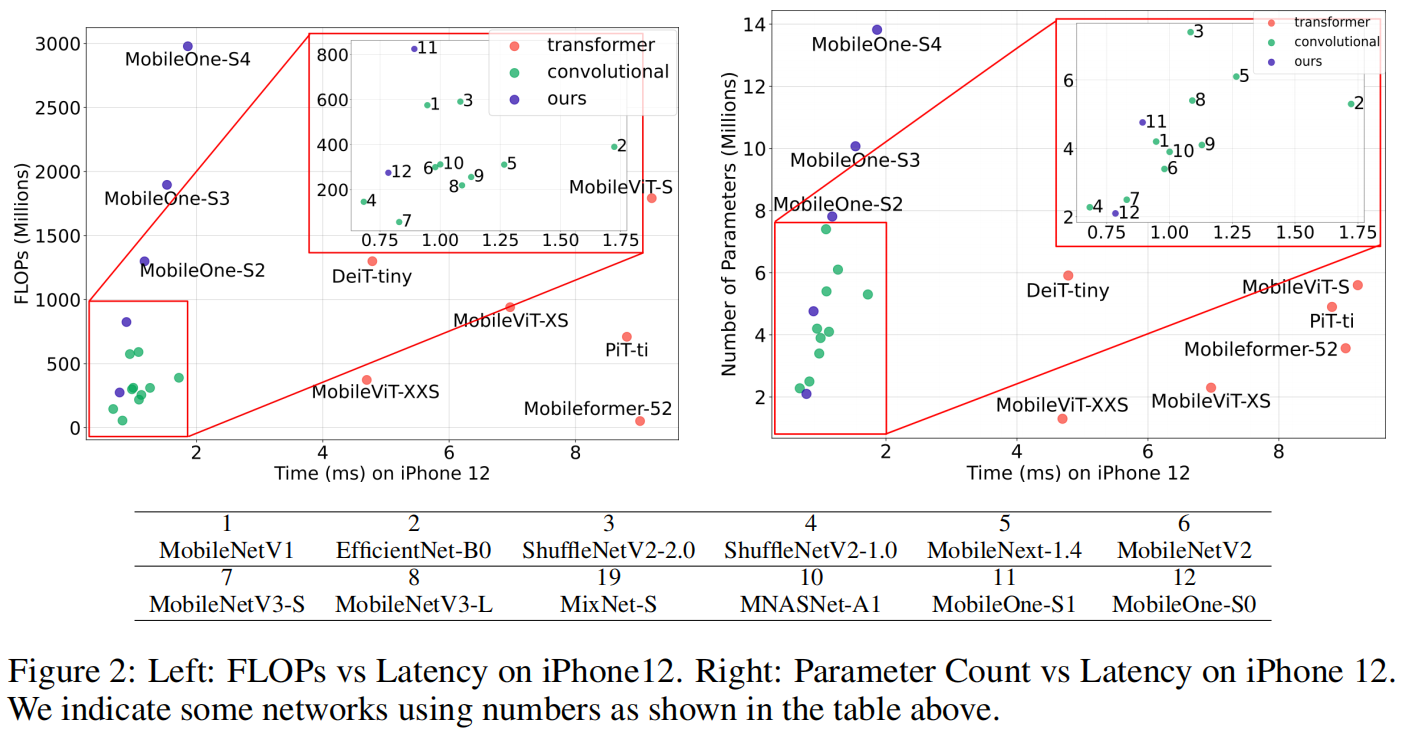
作者首先分析了常用的两个指标FLOPs和参数量与移动设备上延迟的相关性,一些常见的轻量模型的FLOPs和参数量与在iPhone12上的延迟的关系如下图所示,可以看出低FLOPs或低参数量并不代表实际的延迟就低。
Key Bottlenecks
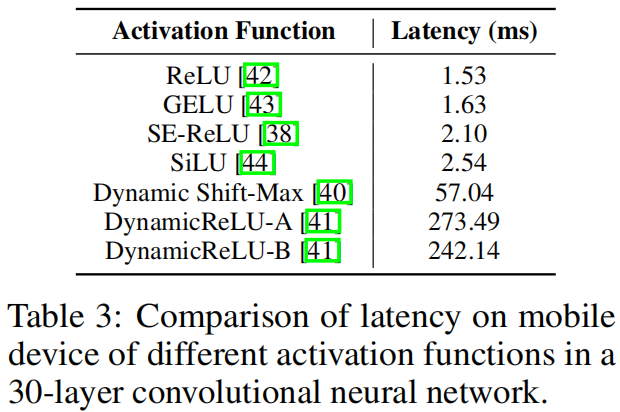
作者从网络结构上分析了延迟的瓶颈,首先是激活函数。为了分析激活函数对延迟的影响,作者构建了一个30层的神经网络,并使用不同的激活函数在iPhone12上进行基准测试,结果如表3所示,可以看出ReLU的延迟最低,因此作者在MobileOne中只使用ReLU激活函数。
作者又分析了Block结构对延迟的影响。影响延迟的两个关键因素是内存访问成本和模型并行程度,在多分支结构中,内存访问成本显著增加,因为每个分支的激活都需要存储起来计算图graph中的下一个张量。如果网络的分支较少就可以避免这种内存瓶颈。此外必须进行同步synchronization操作的block结构比如SE block中的全局平均池化操作,同步成本也会影响延迟。因此作者采用了一种推理时没有分支的结构,从而降低内存访问成本。此外只在MobileOne最大的variant中使用SE block来提高精度。
MobileOne Architecture
MobileOne Block
MobileOne block的结构被分解成depthwise层和pointwise层,此外还引入了over-parameterization分支。basic block的结构基于MobileNet-V1的设计,3x3 depthwise卷积后接1x1 pointwise卷积,然后作者又加入可重参数化的skip-connection分支,具体包括一个batchnorm分支和一个可复制多次的分支,如图3所示

其中over-parameterization factor (k) 是超参,在推理阶段,通过结构重参数化将多分支合并只保留单分支结构。
Model Scaling
最近的一些工作通过缩放scale模型的width、depth、resolution来提高性能。MobileOne深度缩放的策略和MobileNet-V2类似,即浅层early stage采用较少的层,因为浅层的特征图分辨率更大,相比于分辨率较小的深层要慢得多。对于宽度,作者采用了5种不同的尺度,如表2所示。

对于分辨率,作者并没有进行缩放,因为不利于移动设备上的运行性能。
Training
与大模型相比,小模型只需要较少的正则化来对抗过拟合。对于学习率,作者采用cosine schedule策略,对于weight decay系数,也采用相同的策略。此外作者还采用了渐进式课程学习progressive learning curriculum的思想,表5是不同的训练设置对精度的提升

实验结果
作者在ImageNet-1K上评估MobileOne的分类效果,模型的具体细节如下:采用了label smooth正则化,smoothing factor设置为0.1;初始学习率0.1,采用余弦退火schedule调整学习率。weight decay coeffificient设置为(10^{-4}),同样采用cosine schedule减小到(10^{-5});只在训练MobileOne较大的变体即S2、S3、S4时采用AutoAugment数据增强;autoaugment的强度和输入分辨率大小采用EfficientNetv2的方法,在训练过程中逐渐增加;对于较小的变体即S0、S1,采用基本的数据增强方法 - 随机缩放裁剪和水平翻转;对于所有变体,都采用EMA(Exponential Moving Average),decay constant设置为0.9995。实验结果如下

结果按照延迟进行了分组,可以看到MobileOne的不同版本都以最低的延迟得到了最高的精度。
作者还用MobileOne作为backbone,比较了在目标检测和语义分割任务上的性能,结果如下所示
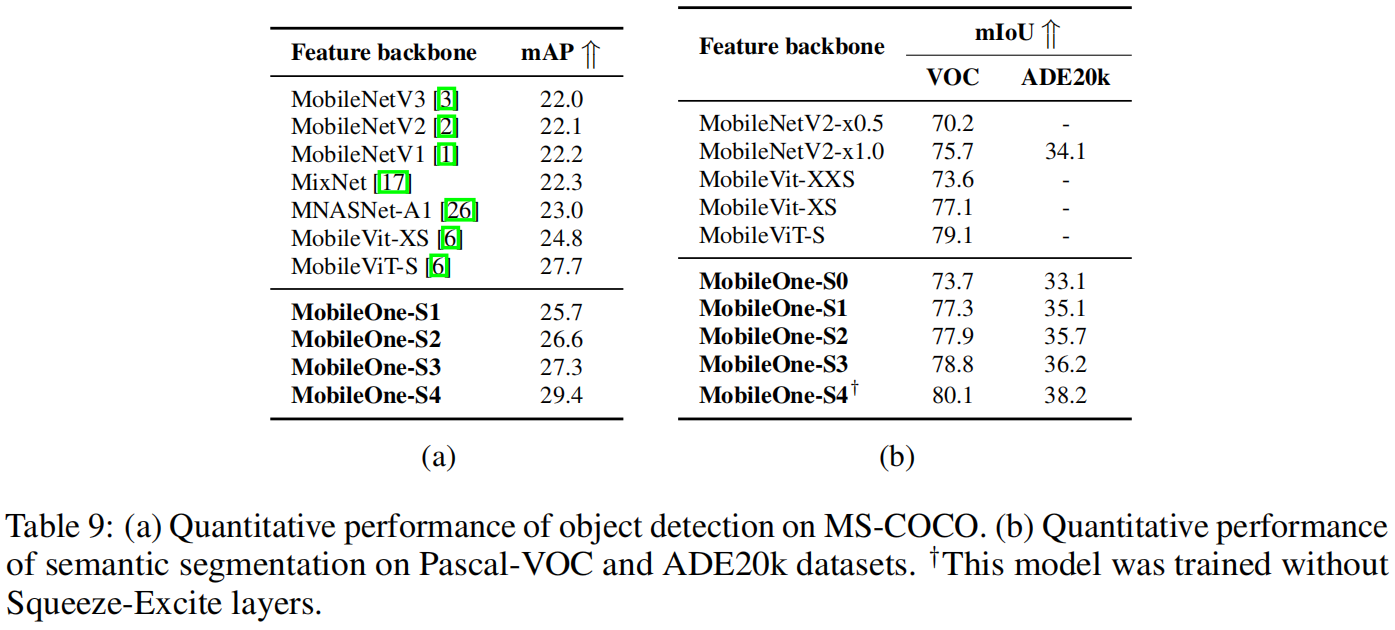
可以看出,MobileOne作为backbone在目标检测和语义分割任务上的性能都优于其它轻量模型,表现除了优异的泛化性能。
代码解析
这里以mmdetection中的实现为例,下面分别是S0~S4的规格,可结合表2一起看。其中num_blocks是不同stage的block个数,注意其中不包含表2中的stage1和stage7、8,同时将stage4、5合并到了一起,因此列表只有4个元素。width_factor表示宽度即通道的缩放因子即表2中的 (\alpha)。num_conv_branches表示block中over-parameterization分支重复的个数,即表2中的 (k)。num_se_blocks表示每个stage的block中采用SE layer的个数。这4个列表的元素个数都是4,分别对应表2中的stage2,stage3,stage45,stage6。
arch_zoo = {
's0':
dict(
num_blocks=[2, 8, 10, 1],
width_factor=[0.75, 1.0, 1.0, 2.0],
num_conv_branches=[4, 4, 4, 4],
num_se_blocks=[0, 0, 0, 0]),
's1':
dict(
num_blocks=[2, 8, 10, 1],
width_factor=[1.5, 1.5, 2.0, 2.5],
num_conv_branches=[1, 1, 1, 1],
num_se_blocks=[0, 0, 0, 0]),
's2':
dict(
num_blocks=[2, 8, 10, 1],
width_factor=[1.5, 2.0, 2.5, 4.0],
num_conv_branches=[1, 1, 1, 1],
num_se_blocks=[0, 0, 0, 0]),
's3':
dict(
num_blocks=[2, 8, 10, 1],
width_factor=[2.0, 2.5, 3.0, 4.0],
num_conv_branches=[1, 1, 1, 1],
num_se_blocks=[0, 0, 0, 0]),
's4':
dict(
num_blocks=[2, 8, 10, 1],
width_factor=[3.0, 3.5, 3.5, 4.0],
num_conv_branches=[1, 1, 1, 1],
num_se_blocks=[0, 0, 5, 1])
}
MobileOneBlock的代码如下,注意如图3所示,一个完整的block包含一个3x3 depthwise的block和一个1x1 pointwise的block,而下面的实现只是一个单独block,因此要调用2次。
看其中的forward函数,self.branch_norm是BN分支,只有当stride=1且输入输出通道数相同时才有该分支。self.branch_scale是3x3 depthwise block中的1x1分支,1x1 pointwise block中没有该分支。self.branch_conv_list就是重复 (k) 次的over-parameterization分支,即3x3 depthwise conv或1x1 pointwise conv。
class MobileOneBlock(BaseModule):
"""MobileOne block for MobileOne backbone.
Args:
in_channels (int): The input channels of the block.
out_channels (int): The output channels of the block.
kernel_size (int): The kernel size of the convs in the block. If the
kernel size is large than 1, there will be a ``branch_scale`` in
the block.
num_convs (int): Number of the convolution branches in the block.
stride (int): Stride of convolution layers. Defaults to 1.
padding (int): Padding of the convolution layers. Defaults to 1.
dilation (int): Dilation of the convolution layers. Defaults to 1.
groups (int): Groups of the convolution layers. Defaults to 1.
se_cfg (None or dict): The configuration of the se module.
Defaults to None.
norm_cfg (dict): Configuration to construct and config norm layer.
Defaults to ``dict(type='BN')``.
act_cfg (dict): Config dict for activation layer.
Defaults to ``dict(type='ReLU')``.
deploy (bool): Whether the model structure is in the deployment mode.
Defaults to False.
init_cfg (dict or list[dict], optional): Initialization config dict.
Defaults to None.
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: int,
num_convs: int,
stride: int = 1,
padding: int = 1,
dilation: int = 1,
groups: int = 1,
se_cfg: Optional[dict] = None,
conv_cfg: Optional[dict] = None,
norm_cfg: Optional[dict] = dict(type='BN'),
act_cfg: Optional[dict] = dict(type='ReLU'),
deploy: bool = False,
init_cfg: Optional[dict] = None):
super(MobileOneBlock, self).__init__(init_cfg)
assert se_cfg is None or isinstance(se_cfg, dict)
if se_cfg is not None:
self.se = SELayer(channels=out_channels, **se_cfg)
else:
self.se = nn.Identity()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.num_conv_branches = num_convs
self.stride = stride
self.padding = padding
self.se_cfg = se_cfg
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
self.deploy = deploy
self.groups = groups
self.dilation = dilation
if deploy:
self.branch_reparam = build_conv_layer(
conv_cfg,
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
groups=self.groups,
stride=stride,
padding=padding,
dilation=dilation,
bias=True)
else:
# judge if input shape and output shape are the same.
# If true, add a normalized identity shortcut.
if out_channels == in_channels and stride == 1:
self.branch_norm = build_norm_layer(norm_cfg, in_channels)[1]
else:
self.branch_norm = None
self.branch_scale = None
if kernel_size > 1:
self.branch_scale = self.create_conv_bn(kernel_size=1)
self.branch_conv_list = ModuleList()
for _ in range(num_convs):
self.branch_conv_list.append(
self.create_conv_bn(
kernel_size=kernel_size,
padding=padding,
dilation=dilation))
self.act = build_activation_layer(act_cfg)
def create_conv_bn(self, kernel_size, dilation=1, padding=0):
"""cearte a (conv + bn) Sequential layer."""
conv_bn = Sequential()
conv_bn.add_module(
'conv',
build_conv_layer(
self.conv_cfg,
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=kernel_size,
groups=self.groups,
stride=self.stride,
dilation=dilation,
padding=padding,
bias=False))
conv_bn.add_module(
'norm',
build_norm_layer(self.norm_cfg, num_features=self.out_channels)[1])
return conv_bn
def forward(self, x):
def _inner_forward(inputs):
if self.deploy:
return self.branch_reparam(inputs)
inner_out = 0
if self.branch_norm is not None:
inner_out = self.branch_norm(inputs)
if self.branch_scale is not None:
inner_out += self.branch_scale(inputs)
for branch_conv in self.branch_conv_list:
inner_out += branch_conv(inputs)
return inner_out
return self.act(self.se(_inner_forward(x)))
def switch_to_deploy(self):
"""Switch the model structure from training mode to deployment mode."""
if self.deploy:
return
assert self.norm_cfg['type'] == 'BN', \
"Switch is not allowed when norm_cfg['type'] != 'BN'."
reparam_weight, reparam_bias = self.reparameterize()
self.branch_reparam = build_conv_layer(
self.conv_cfg,
self.in_channels,
self.out_channels,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups,
bias=True)
self.branch_reparam.weight.data = reparam_weight
self.branch_reparam.bias.data = reparam_bias
for param in self.parameters():
param.detach_()
delattr(self, 'branch_conv_list')
if hasattr(self, 'branch_scale'):
delattr(self, 'branch_scale')
delattr(self, 'branch_norm')
self.deploy = True
def reparameterize(self):
"""Fuse all the parameters of all branches.
Returns:
tuple[torch.Tensor, torch.Tensor]: Parameters after fusion of all
branches. the first element is the weights and the second is
the bias.
"""
weight_conv, bias_conv = 0, 0
for branch_conv in self.branch_conv_list:
weight, bias = self._fuse_conv_bn(branch_conv)
weight_conv += weight
bias_conv += bias
weight_scale, bias_scale = 0, 0
if self.branch_scale is not None:
weight_scale, bias_scale = self._fuse_conv_bn(self.branch_scale)
# Pad scale branch kernel to match conv branch kernel size.
pad = self.kernel_size // 2
weight_scale = F.pad(weight_scale, [pad, pad, pad, pad])
weight_norm, bias_norm = 0, 0
if self.branch_norm:
tmp_conv_bn = self._norm_to_conv(self.branch_norm)
weight_norm, bias_norm = self._fuse_conv_bn(tmp_conv_bn)
return (weight_conv + weight_scale + weight_norm,
bias_conv + bias_scale + bias_norm)
def _fuse_conv_bn(self, branch):
"""Fuse the parameters in a branch with a conv and bn.
Args:
branch (mmcv.runner.Sequential): A branch with conv and bn.
Returns:
tuple[torch.Tensor, torch.Tensor]: The parameters obtained after
fusing the parameters of conv and bn in one branch.
The first element is the weight and the second is the bias.
"""
if branch is None:
return 0, 0
kernel = branch.conv.weight
running_mean = branch.norm.running_mean
running_var = branch.norm.running_var
gamma = branch.norm.weight
beta = branch.norm.bias
eps = branch.norm.eps
std = (running_var + eps).sqrt()
fused_weight = (gamma / std).reshape(-1, 1, 1, 1) * kernel
fused_bias = beta - running_mean * gamma / std
return fused_weight, fused_bias
def _norm_to_conv(self, branch_nrom):
"""Convert a norm layer to a conv-bn sequence towards
``self.kernel_size``.
Args:
branch (nn.BatchNorm2d): A branch only with bn in the block.
Returns:
(mmcv.runner.Sequential): a sequential with conv and bn.
"""
input_dim = self.in_channels // self.groups
conv_weight = torch.zeros(
(self.in_channels, input_dim, self.kernel_size, self.kernel_size),
dtype=branch_nrom.weight.dtype)
for i in range(self.in_channels):
conv_weight[i, i % input_dim, self.kernel_size // 2,
self.kernel_size // 2] = 1
conv_weight = conv_weight.to(branch_nrom.weight.device)
tmp_conv = self.create_conv_bn(kernel_size=self.kernel_size)
tmp_conv.conv.weight.data = conv_weight
tmp_conv.norm = branch_nrom
return tmp_conv
表2中的stage1的代码如下,注意stage1只有1个block,且只有3x3 depthwise block没有后面的1x1 pointwise block。
self.stage0 = MobileOneBlock(
self.in_channels,
channels,
stride=2,
kernel_size=3,
num_convs=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
deploy=deploy)
接下里就是按照arch_zoo中指定的版本参数,遍历stage2~stage6。
self.stages = []
for i, num_blocks in enumerate(self.arch['num_blocks']):
planes = int(base_channels[i] * self.arch['width_factor'][i])
stage = self._make_stage(planes, num_blocks,
arch['num_se_blocks'][i],
arch['num_conv_branches'][i])
stage_name = f'stage{i + 1}'
self.add_module(stage_name, stage)
self.stages.append(stage_name)
其中self._make_stage就是构建每个stage,代码如下。可以看到和stage1不一样,这里每个block包含一个depthwise block和一个pointwise block。当stride=2时,在每个stage的第一个block中的depthwise block中进行下采样。
def _make_stage(self, planes, num_blocks, num_se, num_conv_branches):
strides = [2] + [1] * (num_blocks - 1)
if num_se > num_blocks:
raise ValueError('Number of SE blocks cannot '
'exceed number of layers.')
blocks = []
for i in range(num_blocks):
use_se = False
if i >= (num_blocks - num_se):
use_se = True
blocks.append(
# Depthwise conv
MobileOneBlock(
in_channels=self.in_planes,
out_channels=self.in_planes,
kernel_size=3,
num_convs=num_conv_branches,
stride=strides[i],
padding=1,
groups=self.in_planes,
se_cfg=self.se_cfg if use_se else None,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
deploy=self.deploy))
blocks.append(
# Pointwise conv
MobileOneBlock(
in_channels=self.in_planes,
out_channels=planes,
kernel_size=1,
num_convs=num_conv_branches,
stride=1,
padding=0,
se_cfg=self.se_cfg if use_se else None,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
deploy=self.deploy))
self.in_planes = planes
return Sequential(*blocks)
版权归原作者 00000cj 所有, 如有侵权,请联系我们删除。