政安晨:【完全零基础】认知人工智能(二)【超级简单】的【机器学习神经网络】—— 底层算法
神经元是神经网络的基本组成单元,其底层算法主要包括输入加权和激活函数两个部分。每个神经元都与其前后层的每个神经元相互连接的三层神经元,看起来让人相当惊奇。但是,计算信号如何经过一层一层的神经元,从输入变成输出,这个过程似乎有点令人生畏,这好像是一种非常艰苦的工作。即使此后,我们将使用计算机做这些工作
【毕业设计选题】基于深度学习的健身动作(俯卧撑 深蹲 仰卧起坐)识别计数系统 YOLO 人工智能 算法
毕业设计-基于深度学习的健身动作识别系统的毕业设计。该系统可以识别俯卧撑、深蹲和仰卧起坐等健身动作。介绍了一项基于深度学习的健身动作识别系统的毕业设计。该系统能够准确识别俯卧撑、深蹲和仰卧起坐等常见健身动作,为用户提供实时反馈和指导。通过深度学习算法的应用,该系统具备高度的准确性和稳定性,为健身爱好
《穿越神经网络的奇妙世界:探索人工智能的未来之路》
随着数据的爆炸性增长和计算能力的提升,神经网络算法在过去几年中取得了巨大的进步。从最早的感知机到如今的深度神经网络,神经网络算法已经成为解决复杂问题的强大工具。神经网络算法作为人工智能的核心技术之一,其在各个领域的应用前景广阔。未来,随着技术的不断进步和创新,我们将迎来人工智能的黄金时代。让我们一起
AI一键自动生成论文神器|如何3小时快速搞定论文?超全ChatGPT论文技巧【建议收藏】
AIPaperPass是AI原创论文写作平台,免费千字大纲,5分钟生成3万字初稿,提供答辩汇报ppt、开题报告、任务书等,40篇真实中英文知网参考文献,重复率超过10%包退费。AIPaperPass是AI原创论文写作平台,免费千字大纲,5分钟生成3万字初稿,提供答辩汇报ppt、开题报告、任务书等,4
AI辅写疑似度检测:使用PaperPass的七个要点
通过了解检测原理与算法、选择合适的比对资源库、灵活调整比对参数、关注高疑似度区域、尊重版权与学术诚信、与专业人士交流与合作以及持续关注技术动态与更新,你可以更好地应对原创性挑战,提高自己的写作水平和竞争力。在使用神码论文进行AI辅写疑似度检测之前,你需要了解其检测原理和算法。为了应对不断变化的检测环
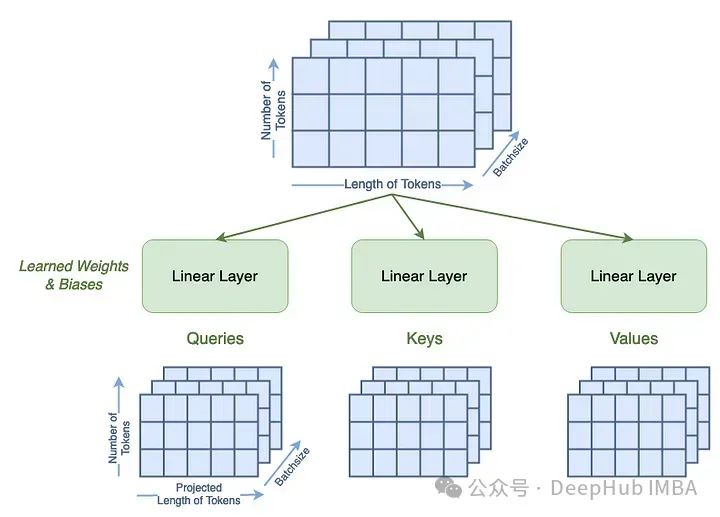
Vision Transformers的注意力层概念解释和代码实现
本文将深入探讨注意力层在计算机视觉环境中的工作原理。我们将讨论单头注意力和多头注意力。它包括注意力层的代码,以及基础数学的概念解释。
ai免费写论文工具有哪些?论文免费自动生成器
在各种文本、数学、编码和推理基准测试中,包括 MMLU、GSM8K、MATH、Big-Bench Hard、HumanEval、Natural2Code、DROP 和 WMT23,Gemini 的表现均超越了其他所有模型,并改善了最新的最先进成果。AI大模型赛道也卷的飞起,打造像Gemini这样的巨
毕业设计:基于深度学习的全景图像拼接系统 人工智能 算法
毕业设计:基于深度学习的全景图像拼接系统采用深度学习算法对多张图像进行特征提取和匹配,实现了全景图像的自动拼接。通过训练深度神经网络模型,系统能够学习到图像之间的空间关系和变换参数,从而精确地将图像拼接在一起。该系统可广泛应用于各种场景的全景图像拼接任务,有效提升了拼接的准确性和效率。为计算机毕业设
【计算机视觉】Vision Transformer (ViT)详细解析
【计算机视觉】Vision Transformer (ViT)详细解析

使用TensorRT-LLM进行生产环境的部署指南
TensorRT-LLM是一个由Nvidia设计的开源框架,用于在生产环境中提高大型语言模型的性能。
Chatgpt与机器学习如何影响未来AI发展
毫无疑问的,随着gpt的发展,必然会取代掉一些工作岗位,但是长期来看,我并不认为这一定是一件坏事(呜呜别取代我啊),正如工业革命对于当时手工业者的影响类似,这样反而倒逼人们向更有创造力,更能为社会生产力进步的行业去努力,当然,短期的阵痛肯定是难以避免的,关于这个问题,就不仅仅是学科方面需要解决的了,
特斯拉FSD的神经网络(Tesla 2022 AI Day)
特斯拉FSD的神经网络关于注意力机制在视觉中的使用分析和特斯拉语言模型分割拓扑网络的技术分析解读
AI:145-智能监控系统下的行人安全预警与法律合规分析
AI:145-智能监控系统下的行人安全预警与法律合规分析随着人工智能技术的不断发展,智能监控系统在社会生活中得到了广泛的应用。其中,行人安全预警是一个备受关注的领域,涉及到了公共安全和法律合规等多个方面。本文将探讨在智能监控系统下实现行人安全预警的技术实现,并分析相应的法律合规问题。
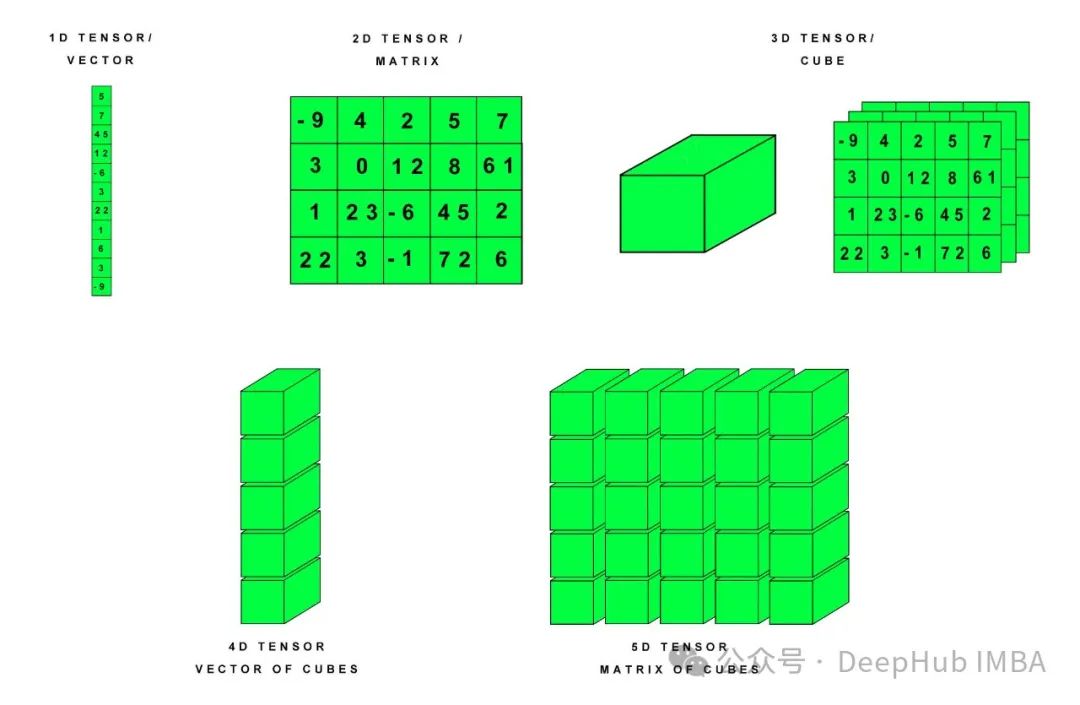
Pytorch中张量的高级选择操作
在某些情况下,我们需要用Pytorch做一些高级的索引/选择,所以在这篇文章中,我们将介绍这类任务的三种最常见的方法:torch.index_select, torch.gather and torch.take
今日arXiv最热NLP大模型论文:无需提示也能推理!Google DeepMind新研究揭示AI内在推理能力
1. CoT-decoding的发现和意义研究表明,通过改变解码过程,即使没有显式提示,预训练的大语言模型(LLM)也能自然地产生链式思考(CoT)推理路径。这种方法被称为CoT-decoding,它通过考虑解码过程中的顶部-k个代替令牌,揭示了CoT路径通常是这些序列中的固有部分。CoT-deco
AI:146-基于图像特征的法庭口供真实性分析
AI:146-基于图像特征的法庭口供真实性分析随着人工智能技术的迅猛发展,其在各个领域的应用逐渐深入,其中包括司法系统。法庭口供真实性分析一直是司法领域的关键问题之一。传统的口供真实性判断主要依赖于人工审查,然而,这种方法可能受到主观因素的影响,而人工智能技术能够通过客观的图像特征分析提供更加科学和
AI:134-基于深度学习的社交媒体图像内容分析
AI:134-基于深度学习的社交媒体图像内容分析在当今数字化社会中,社交媒体已经成为人们分享信息、互动交流的重要平台。随着用户生成的内容不断增加,社交媒体平台上的图像数量呈爆炸式增长,这为人工智能技术在图像内容分析领域提供了广阔的发展空间。本文将重点讨论基于深度学习的方法在社交媒体图像内容分析中的应
AI辅写疑似度高风险?七个方法助你化解
通过深入理解AI辅写的原理与局限、注重个人风格与观点的融入、调整AI工具的参数与设置、进行深度定制与整合、注重语言规范与技巧、合理引用与参考文献以及寻求专业人士的意见与指导我们可以有效地降低疑似度提高论文的原创性和可信度同时我们也要关注学术道德与规范确保我们的论文是合法和合规的。在写作过程中,注重发
可视化FAISS矢量空间并调整RAG参数提高结果精度
在本文中,我们将使用可视化库renumics-spotlight在2-D中可视化FAISS向量空间的多维嵌入,并通过改变某些关键的矢量化参数来寻找提高RAG响应精度的可能性。

谷歌Gemma介绍、微调、量化和推理
这篇文章我们将介绍Gemma模型,然后展示如何使用Gemma模型,包括使用QLoRA、推理和量化微调。



