
1. 前言
源码:GitHub - ultralytics/yolov5 at v5.0

由于YOLO v5 代码库在持续更新,如上图,有多个版本,每个版本的网络结构不尽相同。以下内容以 v5.0 为准,网络结构选用 yolov5s。
2.修改过程
为了方便画图和理解网络结构,选用可视化工具: Netron 网页版 进行可视化, 然后使用PPT作图。
在 Releases · ultralytics/yolov5 · GitHub 找到 v5.0 中的** Assets **中的 yolov5s.pt 并下载该权重。
下图为直接选用 Netron 对 pytorch 的 yolov5s.pt 部分可视化的结果,显然该图细节不足。该图显然与 yolov5-5.0/models/yolov5s.yaml 是对应的。

为了看到更多细节,使用Netron 对 yolov5s.onnx 可视化:
python models/export.py --weights ./weights/yolov5s.pt
那么:yolov5s.pt -> yolov5s.onnx
可视化结果为下图左:
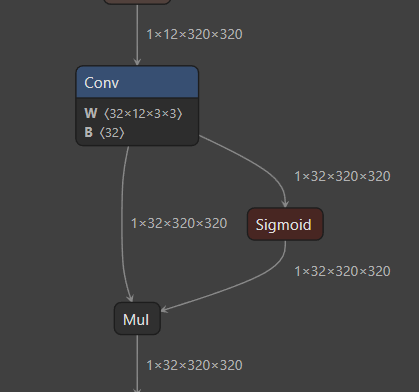
显然该图没有显示输出输出的尺寸,为此我们修改 export.py 代码,并重新导出onnx,显示为上图右。
from onnx import shape_inference
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.save(shape_inference.infer_shapes(onnx_model), f)
# # Checks
# onnx_model = onnx.load(f) # load onnx model
参考:pytorch模型结构可视化,可显示每层的尺寸 - 知乎
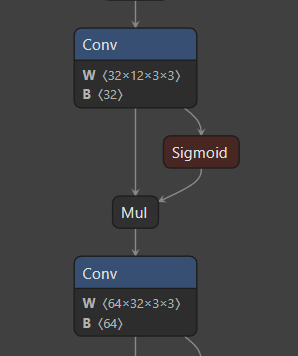
问题1:上图中 Conv 中的 B是什么?
B其实就是 bias,但是 Conv2d + BN + SiLU 中 conv 是没有 bias的,那这个bias 怎么来的?其实这是因为在 fuse_conv_and_bn(conv, bn) 函数中:
# prepare spatial bias
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
在 conv 和 bn 融合中,对 bais进行了 替换。所以这里的 B 并不是 单纯的 bn,而是代码中的fusedconv.bias。这里待填坑...
问题2:在网络中明明使用的是 Conv2d + BN + SiLU 为什么是上图右边那个样子?Silu是啥?
在YOLOv5-4.0版本中,使用 nn.SiLU() activations 替换了先前版本中使用的 nn.LeakyReLU(0.1) and nn.Hardswish() activations。PyTorch 1.7.0 版本中 nn.SiLU() 被引入 (SiLU — PyTorch 1.11.0 documentation)。目的是为了:简化架构,使用一种激活函数,而不是以前的两种。
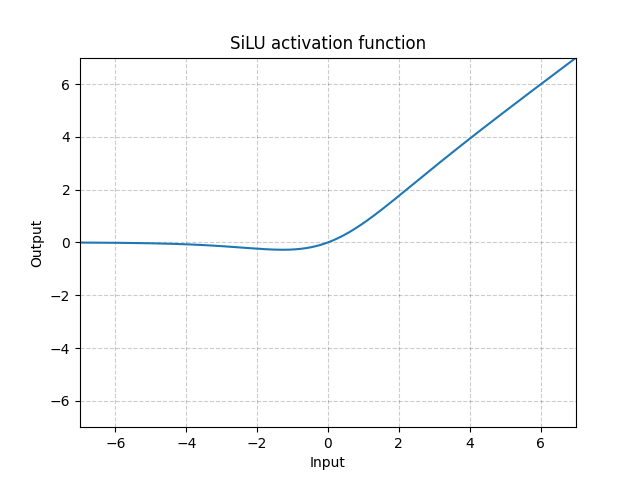
所以为上图中的 两条分支。
问题3:网络中 Conv2d + BN + SiLU 的 BN怎么没了?
这是因为代码中使用 fuse_conv_and_bn函数合并了Conv2d层和BatchNorm2d层。
在模型训练完成后,代码在推理阶段和导出模型时,将卷积层和BN层进行融合。
为了可视化画图,我们选择关闭 models/yolo.py -- fuse()
关闭方法参考:https://github.com/ultralytics/yolov5/issues/658
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
# for m in self.model.modules():
# if type(m) is Conv and hasattr(m, 'bn'):
# m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
# delattr(m, 'bn') # remove batchnorm
# m.forward = m.fuseforward # update forward
# self.info()
return self
然后,Netron 对 onnx 文件默认是 将 conv和BN 合并的,所以不显示 BN。解决:models/export.py 中修改导出代码,增加 *training=torch.onnx.TrainingMode.TRAINING,*:
此处参考:deep learning - Why is it that when viewing the architecture in Netron, the normalization layer that goes right after the convolutional layer is not shown? - Stack Overflow
torch.onnx.export(model, img, f, verbose=False, opset_version=12,
training=torch.onnx.TrainingMode.TRAINING,
input_names=['images'],
output_names=['classes', 'boxes'] if y is None else ['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # size(1,3,640,640)
'output': {0: 'batch', 2: 'y', 3: 'x'}} if opt.dynamic else None)
然后重新导出,即可获得结果。如下图:
当我们把 Conv 和BN 分离后,显然 带 BN的 Conv 就没有 bias 了。
当然,除了以上方式,当我们关闭fuse()后,也可以直接使用 Netron 对 导出的 weights/yolov5s.torchscript.pt 可视化,一样可以看到 BN。
以下是以 yolov5s.onnx 画图。
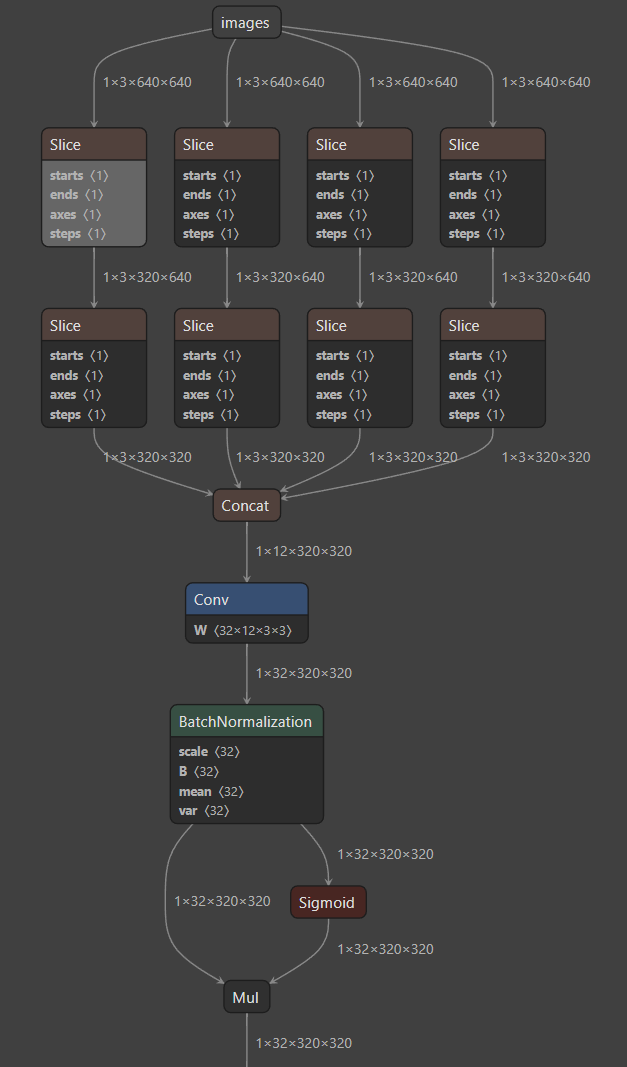
图中 Resize为上采样操作,对应 models/yolov5s.yaml 中的 nn.Upsample, [None, 2, 'nearest']],显然使用的是 最近邻插值(nearest 插值)。
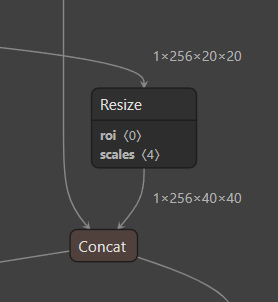
出现下图中的原因是:
- 对于任何用到shape、size返回值的参数时,例如:tensor.view(tensor.size(0), -1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换,tensor.view(int(tensor.size(0)), -1)。为了避免pytorch导出 onnx时候,对size 进行跟踪,跟踪时候会生成gather、shape的节点。
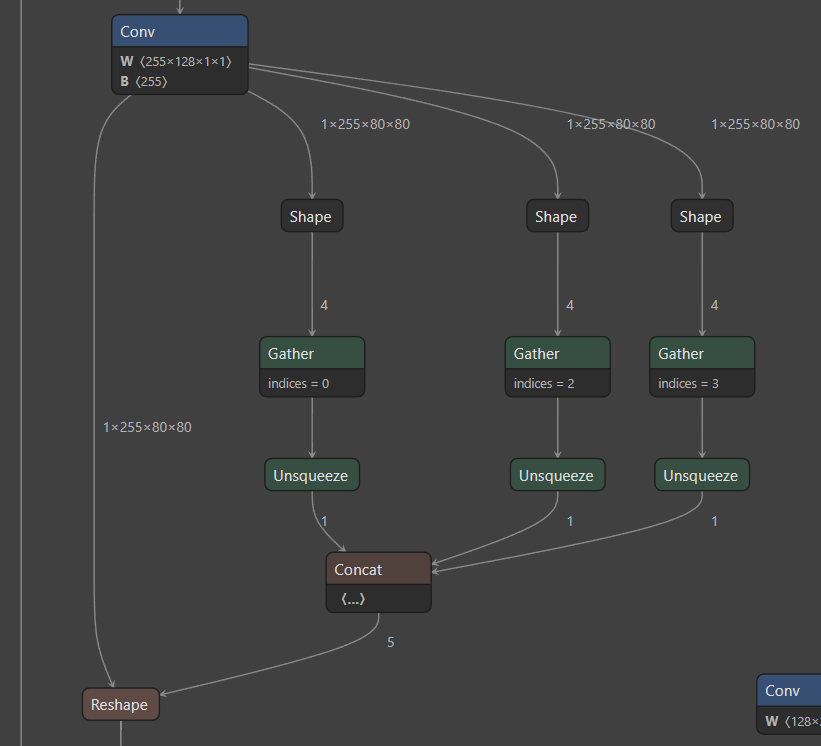
因此修改代码:models/yolo.py
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs, _, ny, nx = map(int, x[i].shape)
重新导出 onnx,如下图,看起来清爽多了。
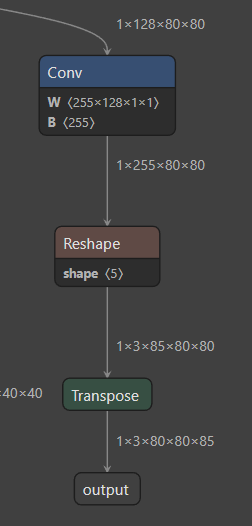
3. 最终成图
使用PPT作图:
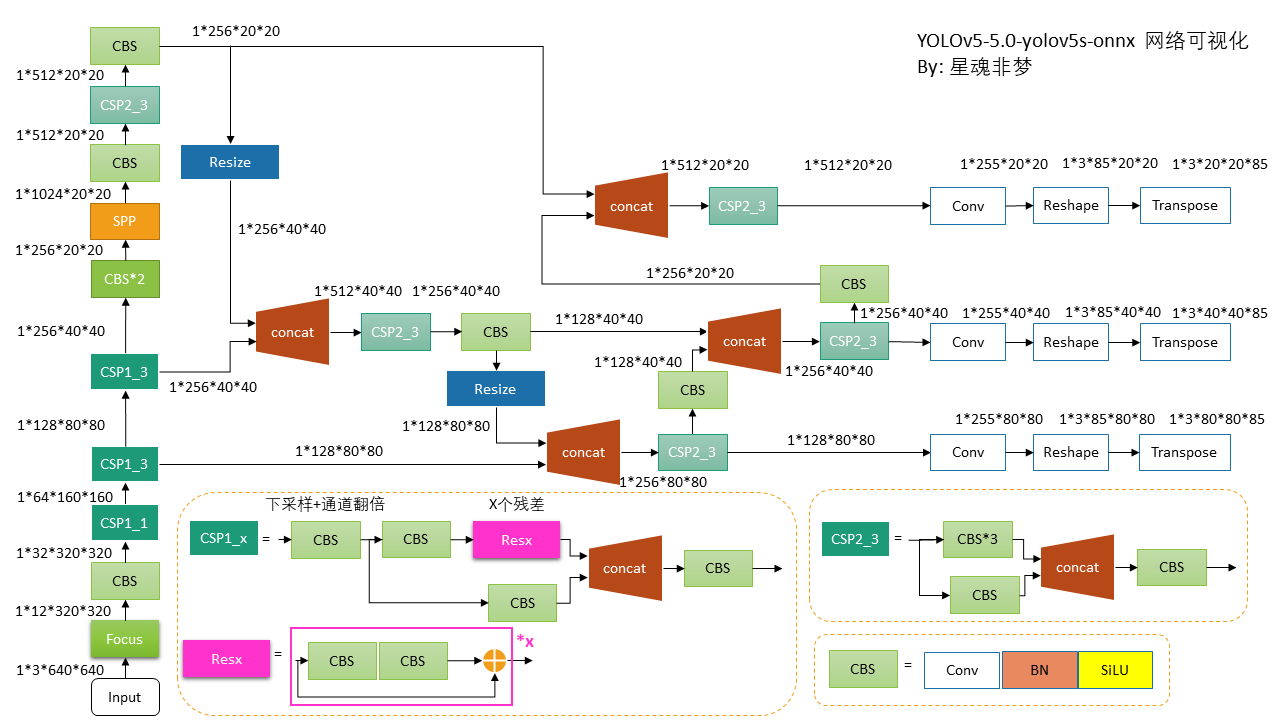
注意:在代码中
- 图中 Resize 为 nn.Upsample_nearest
- Reshape 为 view,Transpose 为 permute
- 以上所有的带 BN的 conv 都是没有 bias的, 只有最后的Conv 带 bias
版权归原作者 理心炼丹 所有, 如有侵权,请联系我们删除。