
本篇文章是在做图像分割任务,关于损失函数的一些内容。
这里需要的损失函数是:BCEWithLogitsLoss() 就是:sigmoid + BCELoss
1. sigmoid + BCELoss
接下来通过例子来讲解,例如图像分割的时候,网络输出的预测图像是2*2 的矩阵,这里是input

这里先用sigmoid 将输出压缩到0-1之间
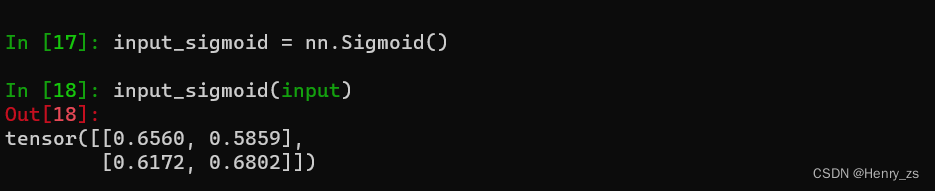
这里要计算 predict 和 label 的损失之,假如这里label是下面的形式。label是一个二阶的单位阵,其中1为前景,0为背景 
根据BCELoss 的损失值计算公式:
- 其中 y 为真实值 , y(hat)为预测值
因此,首先计算 a11(左上角) 的值:1 * ln 0.6560 + (1-1)* ln(1-0.6560) = -0.4216
然后 a12 (右上角)的值:0 * ln 0.5859 + (1-0)*ln(1-0.5859) = -0.8816
a13 (左下角):0 * ln 0.6172 + (1-0)*ln(1-0.6172) = -0.9602
a14 (右下角):1 * ln 0.6802 + (1-1)*ln(1-0.6802) = -0.3854
将四个结果求均值,然后加个负号的结果为:(0.4216+0.8816+0.9602+0.3854)/ 4 = 0.6622
同 BCELoss 计算的损失值一样

2. BCEWithLogitsLoss
BCEWithLogitsLoss 就是 sigmoid + BCELoss 的结合,如果直接用 BCEWithLogitsLoss 可以得到相同的结果

3. gossip
损失函数是计算网络预测的值和真实值的偏差程度,所以我们希望损失值越小越好,这样才能保证predict 和 label 足够的接近
首先说一下二元分类数学表达式:

这里用的是数理统计的内容----极大似然估计,也就是网络预测的内容和真实值在什么情况下最大的相似,或者说这个参数的神经网络对图像分割准确的概率最大。
而求取似然函数的方法就是取对数,所以上面的二元分类会存在 log 函数,而似然函数是求取最大相似的概率。而在深度学习中,我们希望loss 越小越好,所以前面加一个负号
回到图像分割的内容,最后的神经网络需要将输出的图像变成二值图像,所以需要进行阈值判断。
例如下面这样

也就是将神经网络输出的图像矩阵,大于等于零的映射为前景,小于0的映射为背景。
有时候,会将预测的结果经过sigmiod ,然后在 0.5 的左右进行映射判断是一个意思
这里之前本人产生过很多误区,如果预测的时候不让他经过sigmoid,那么为什么计算loss的时候,让神经网络经过sigmoid呢?或者在预测的时候,就让预测值也变成二值图像,和label计算损失?
之前尝试这个想法,最后损失值出现了负数,原因如下:
因为 log 函数在 0-1 上是取的负值,这样才能保证每次计算BCELoss 的时候,才不会出现正数的原因。那么将这些负值累加,求平均,最后加个负号得到的就是需要的损失值。所以,这也是为什么在计算BCELoss 之前需要经过sigmoid 函数了
其次就是 log 函数的定义域是 0-正无穷 ,如果不用 sigmoid限制的话,那么很有可能会出现无法计算的情况。而经过sigmoid之后,值会被限制到 0-1之间,或者说0和1都是取不到的,因为是数学上的极限值。
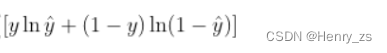
这也就是为什么ln 里面的是 预测值 或者 1-预测值,才能保证计算始终可以进行下去
如果预测不经过sigmoid的话,假如神经网络有一个输出是-1的话,那么就没法进行 ln -1 的计算
如果将预测变成二值图像的话,那么 ln 0 就无法计算
版权归原作者 十七的太阳 所有, 如有侵权,请联系我们删除。