
介绍yolov7数据集格式之前,首先要了解mask rcnn使用的数据集格式。Mask rcnn采用数据集格式:

四个文件夹分别是:
** 掩码标签 label.png;**
** 从labelme产生的json文件转换的后的json文件;**
** labelme 标注后的json文件;**
** 图片。**
注意,mask rcnn是采用分割图作为标签,不使用源数据集提供的边界框坐标,而是从掩码中计算边界框。使用的数据是与yolov7不同。
想要复现Yolov7,并训练自己的数据,了解数据格式是必须的,以yolov7-main程序中使用的coco数据为例:
yolov7-main程序:https://github.com/WongKinYiu/yolov7
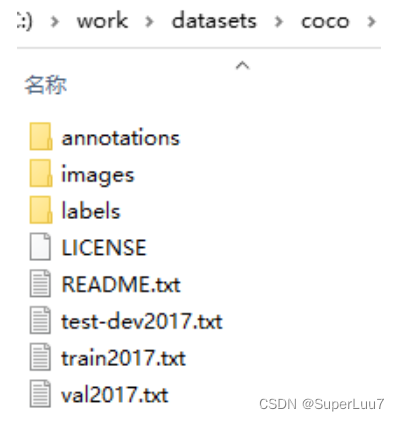
其中annotations中共一个instances_val2017.json文件,包含所有图像标注信息;
labels 是对应images的 .txt 文件,txt文件中是物体分割标注点。

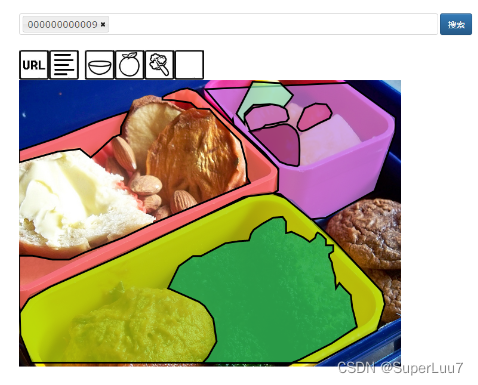
标注内容是:45是bowl,49是orange,50是broccoli
为了进一步对数据集有所了解,这里放上对应的图:查看coco数据集的标注情况可以看link:
http://cocodataset.org/#explore?id=402563
参考:https://github.com/matterport/Mask_RCNN/blob/master/samples/coco/inspect_data.ipynb
做自己的数据集用yolov7训练,可以用labelme等标注工具。这里放一张 形状识别和分割数据标注图像,和json文件截图:


*其中,标注类型包括矩形边界框和多边形mask标记等等。我用的是 polygon, rectangle两种格式,可以用于目标识别和实例分割。根据自己的需求可以选择其他的标注方式。*
每张图像标注完都会产生对应的一个 .json文件,记录了标记的点的坐标和类型等信息。
训练自己的数据集用来识别目标时,仅使用标注文件中的rectangle信息即可。将标注框转换为cls_num center_x center_y w h 格式的数据即可。每个图像对应一个txt文件,每个目标标注对应一行标注信息。训练自己的数据集实例分割和目标识别时,仅用polygon格式的标注信息即可。将多边形点转换为 cls_num x0 y0 x1 y1 ...xn yn 格式的数据即可。同理一个图像对应一个txt文件,一个多边形标注对应txt中的一行。
将labelme 工具产生的.json 文件中的rectangle 或者polygon格式的标注信息转换为txt文件的程序:
https://github.com/SuperLuu7/labelme2yolo
yolov7使用的数据集格式就是这样了,希望大家都能训练得到自己想要的结果。
版权归原作者 SuperLuu7 所有, 如有侵权,请联系我们删除。