

UNet的编解码结构一经提出以来,大有统一深度学习图像分割之势,后续基于UNet的改进方案也经久不衰,一些研究者也在从网络结构本身来思考UNet的有效性。比如说编解码网络应该取几层,跳跃连接是否能够有更多的变化以及什么样的结构训练起来更加有效等问题。UNet本身是针对医学图像分割任务而提出来的网络结构,该任务不像自然图像分割,对分割精度要求并不是十分严格。但对于医学图像而言,器官和病灶的分割则要求极高的精确性,因为很多时候分割效果的好坏直接关系到对应的临床诊断决策。出于上述两个方面的动机,即设计更好的UNet结构和提升医学图像分割的精度,相关研究者提出了一种嵌套的UNet结构(Nested UNet),也叫UNet++,提出UNet++的论文为UNet++: A Nested U-Net Architecture for Medical Image Segmentation,发表于2018年的医学图像计算和计算机辅助干预(Medical Image Computing and Computer Assisted Intervention,MICCAI)会议上。
UNet++取名为嵌套的UNet,就在于其整体编解码网络结构中还嵌套了编解码的子网络(sub-networks),在此基础上重新设计UNet中间的跳跃连接,并补充了深监督机制加速网络训练收敛。完整的UNet++结构如下图所示。
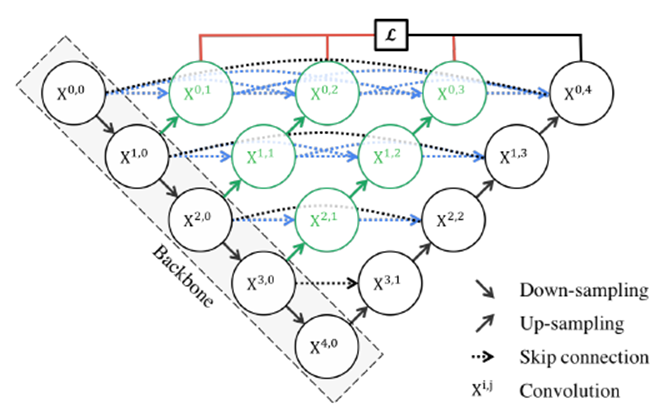
图中黑色部分为原始的UNet结构,包括编码器下采样、解码器上采样和黑色虚线的跳跃连接三个部分;绿色部分即嵌套的UNet子网络,包括卷积和上采样两部分,而蓝色虚线部分就是UNet++重新设计后的跳跃连接,这部分跟DenseNet的密集连接类似,这里是为子网络提供跳跃连接;最上面红黑连线则是UNet++补充的深监督机制,目的是为了网络能够顺利得到训练。
下面我们从结构设计的角度来对UNet++进行解读。关于UNet结构,最首要的问题就是网络应该有几层,原始的UNet结构用了4层下采样和4层上采样,那么是不是4层就足以满足所有的分割任务需要?答案是否定的。通过本节之前的网络结构分析,我们已经知道,浅层网络能够提取图像粗粒度特征,获取图像基本形态;深层网络能够提取图像的抽象特征,获取图像语义信息,总之浅有浅的侧重,深有深的好处。同之前RefineNet的观点一样,UNet++的作者认为,不管是浅层、深层还是中层,所有层次的特征对于最后的分割都是重要的。有的数据分割任务简单,图像信息单一,可能浅层网络就足以达到很好的效果,而有的数据任务复杂,图像信息丰富,可能需要更深层的网络结构才能达到不错的效果,之前的UNet结构设计很难同时照顾到这种普适性。而UNet++通过设计不同深度的嵌套UNet子网络来实现这种普适性,所以UNet的深度到这里就解决了。
第二个问题则是加入不同深度的嵌套网络后,跳跃连接部分该如何调整。在UNet中,跳跃连接由同层编码器直连到编码器上采样对应层。但加入嵌套子网络后,UNet中原先的长连接就不复存在了,取而代之的是各子网络中的短连接。UNet++的作者们认为,长连接在UNet中是有必要的,能够将图像中前后信息联系起来,对于下采样造成的信息损失有很好的补充作用。所以,UNet++又参考DenseNet的密集连接设计,给嵌套网络补充了长连接,如下图5所示。
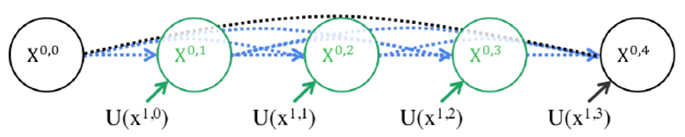
但是这样又带来了第三个问题:反向传播的时候中间部分可能会收不到由损失函数反传回来的梯度。所以见招拆招,UNet++又通过深监督的方法来强行加梯度,帮助网络正常进行训练。但深监督对于UNet++的好处绝不仅仅限于此,通过不同深监督损失函数,UNet++可以通过网络剪枝来实现可伸缩性。所以,总结来说UNet++相较于原始的UNet,有如下两个优势:
(1)通过嵌套子网络和长短连接来整合不同层次的图像特征,使得网络分割精度更高;
(2)灵活的网络结构配合深监督机制,让参数量巨大的深度网络在可接受的精度范围内能够大幅度的缩减参数量。
UNet++与UNet等网络分割效果对比如下图所示。

UNet++也进一步壮大了UNet家族网络,后续基于其的改进版本也有很多,比如Attention UNet++、UNet 3+等。下述代码给出了UNet++的一个实现参考。完整代码可参考:
https://github.com/4uiiurz1/pytorch-nested-unet/blob/master/archs.py
class NestedUNet(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
根据读者对于本系列的反馈,后续相关内容会逐步更新到深度学习语义分割与实战指南GitHub地址:
https://github.com/luwill/Semantic-Segmentation-Guide
往期精彩:
深度学习论文精读[1]:FCN全卷积网络
深度学习论文精读[2]:UNet网络
深度学习论文精读[3]:SegNet
深度学习论文精读[4]:RefineNet
深度学习论文精读[5]:Attention UNet
讲解视频来了!机器学习 公式推导与代码实现开录!
完结!《机器学习 公式推导与代码实现》全书1-26章PPT下载
版权归原作者 louwill12 所有, 如有侵权,请联系我们删除。