
生成对抗网络(GANs)的训练效果很大程度上取决于其损失函数的选择。本研究首先介绍经典GAN损失函数的理论基础,随后使用PyTorch实现包括原始GAN、最小二乘GAN(LS-GAN)、Wasserstein GAN(WGAN)及带梯度惩罚的WGAN(WGAN-GP)在内的多种损失函数。
生成对抗网络(GANs)的工作原理堪比一场精妙的艺术创作过程——生成器(Generator)扮演创作者角色,不断生成作品;判别器(Discriminator)则如同严苛的评论家,持续提供改进建议。这种对抗学习机制促使两个网络在竞争中共同进步。判别器向生成器提供反馈的方式——即损失函数的设计——对整个网络的学习表现有着决定性影响。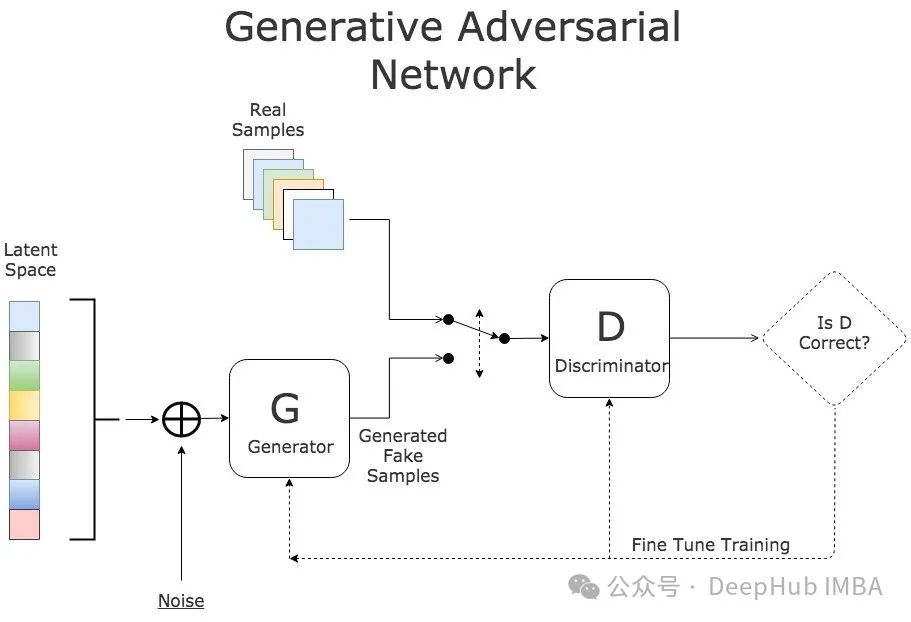
GAN的基本原理与经典损失函数
1、原始GAN
Goodfellow等人于2014年提出的原始GAN采用极小极大博弈(Minimax Game)框架,其损失函数可表述为: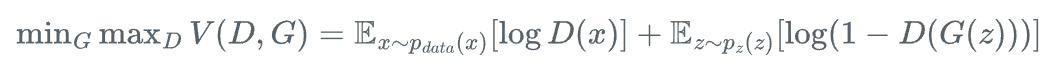
其中:
- D(x)表示判别器对输入x判定为真实样本的概率
- G(z)表示生成器将随机噪声z转换为合成图像的函数
- p_{data}(x)表示真实数据分布
- p_z(z)表示噪声先验分布,通常为标准正态分布
原始GAN在理论上试图最小化生成分布与真实分布之间的Jensen-Shannon散度(JS散度),但在实际训练中存在梯度消失、模式崩溃和训练不稳定等问题。这些局限性促使研究者开发了多种改进的损失函数。
PyTorch实现:
import torch
import torch.nn as nn
# 原始GAN损失函数实现
class OriginalGANLoss:
def __init__(self, device):
self.device = device
self.criterion = nn.BCELoss()
def discriminator_loss(self, real_output, fake_output):
# 真实样本的目标标签为1.0
real_labels = torch.ones_like(real_output, device=self.device)
# 生成样本的目标标签为0.0
fake_labels = torch.zeros_like(fake_output, device=self.device)
# 计算判别器对真实样本的损失
real_loss = self.criterion(real_output, real_labels)
# 计算判别器对生成样本的损失
fake_loss = self.criterion(fake_output, fake_labels)
# 总损失为两部分之和
d_loss = real_loss + fake_loss
return d_loss
def generator_loss(self, fake_output):
# 生成器希望判别器将生成样本判断为真实样本
target_labels = torch.ones_like(fake_output, device=self.device)
g_loss = self.criterion(fake_output, target_labels)
return g_loss
2、非饱和损失函数(Non-Saturating Loss)
为解决原始GAN中生成器梯度消失问题,Goodfellow提出了非饱和损失,将生成器的目标函数修改为: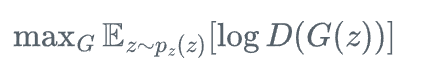
这种修改保持了相同的最优解,但提供了更强的梯度信号,特别是在训练初期生成样本质量较差时,有效改善了学习效率。非饱和损失通过直接最大化判别器对生成样本的预测概率,而不是最小化判别器正确分类的概率,从而避免了在生成器表现不佳时梯度趋近于零的问题。
PyTorch实现:
class NonSaturatingGANLoss:
def __init__(self, device):
self.device = device
self.criterion = nn.BCELoss()
def discriminator_loss(self, real_output, fake_output):
# 与原始GAN相同
real_labels = torch.ones_like(real_output, device=self.device)
fake_labels = torch.zeros_like(fake_output, device=self.device)
real_loss = self.criterion(real_output, real_labels)
fake_loss = self.criterion(fake_output, fake_labels)
d_loss = real_loss + fake_loss
return d_loss
def generator_loss(self, fake_output):
# 非饱和损失:直接最大化log(D(G(z)))
target_labels = torch.ones_like(fake_output, device=self.device)
# 注意这里使用的是相同的BCE损失,但目标是让D将G(z)判断为真
g_loss = self.criterion(fake_output, target_labels)
return g_loss
GAN变体实现与原理分析
3、最小二乘GAN(LS-GAN)
LS-GAN通过用最小二乘损失替代标准GAN中的二元交叉熵损失,有效改善了训练过程: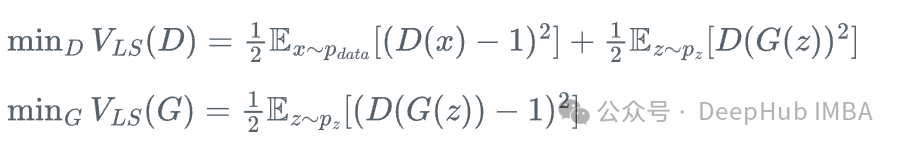
这一修改使得模型在训练过程中梯度变化更为平滑,显著降低了训练不稳定性。LS-GAN的主要优势在于能够有效减轻模式崩溃问题(即生成器仅产生有限类型样本的现象),同时促进学习过程的连续性与稳定性,使模型能够更加渐进地学习数据分布特征。理论上,LS-GAN试图最小化Pearson \chi^2 散度,这对于分布重叠较少的情况提供了更好的训练信号。
PyTorch实现:
class LSGANLoss:
def __init__(self, device):
self.device = device
# LS-GAN使用MSE损失而非BCE损失
self.criterion = nn.MSELoss()
def discriminator_loss(self, real_output, fake_output):
# 真实样本的目标值为1.0
real_labels = torch.ones_like(real_output, device=self.device)
# 生成样本的目标值为0.0
fake_labels = torch.zeros_like(fake_output, device=self.device)
# 计算真实样本的MSE损失
real_loss = self.criterion(real_output, real_labels)
# 计算生成样本的MSE损失
fake_loss = self.criterion(fake_output, fake_labels)
d_loss = real_loss + fake_loss
return d_loss
def generator_loss(self, fake_output):
# 生成器希望生成的样本被判别为真实样本
target_labels = torch.ones_like(fake_output, device=self.device)
g_loss = self.criterion(fake_output, target_labels)
return g_loss
4、Wasserstein GAN(WGAN)
WGAN通过引入Wasserstein距离(也称为地球移动者距离)作为分布差异度量,从根本上改变了GAN的训练机制: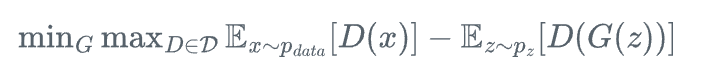
其中\mathcal{D}是所有满足1-Lipschitz约束的函数集合。与传统GAN关注样本真假二分类不同,WGAN评估的是生成分布与真实分布之间的距离,这一方法提供了更为连续且有意义的梯度信息。WGAN能够显著改善梯度传播问题,有效防止判别器过度主导训练过程,同时大幅减轻模式崩溃现象,提高生成样本的多样性。
原始WGAN通过权重裁剪(weight clipping)实现Lipschitz约束,具体做法是将判别器参数限制在某个固定范围内,如[-c, c],但这种方法可能会限制网络容量并导致病态行为。
PyTorch实现:
class WGANLoss:
def __init__(self, device, clip_value=0.01):
self.device = device
self.clip_value = clip_value
def discriminator_loss(self, real_output, fake_output):
# WGAN的判别器(称为critic)直接最大化真实样本和生成样本输出的差值
# 注意这里没有使用sigmoid激活
d_loss = -torch.mean(real_output) + torch.mean(fake_output)
return d_loss
def generator_loss(self, fake_output):
# 生成器希望最大化critic对生成样本的评分
g_loss = -torch.mean(fake_output)
return g_loss
def weight_clipping(self, critic):
# 权重裁剪,限制critic参数范围
for p in critic.parameters():
p.data.clamp_(-self.clip_value, self.clip_value)
5、带梯度惩罚的WGAN(WGAN-GP)
WGAN-GP是对WGAN的进一步优化,通过引入梯度惩罚项来满足Lipschitz连续性约束: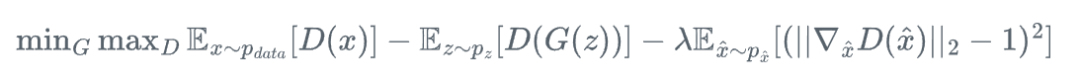
其中\hat{x}是真实样本和生成样本之间的随机插值点。这一改进避免了原始WGAN中权重裁剪可能带来的容量限制和训练不稳定问题。梯度惩罚使模型训练过程更加稳定,同时减少了生成图像中的伪影,提高了最终生成结果的质量与真实度。WGAN-GP已成为许多高质量图像生成任务的首选损失函数。
PyTorch实现:
class WGANGP:
def __init__(self, device, lambda_gp=10):
self.device = device
self.lambda_gp = lambda_gp
def discriminator_loss(self, real_output, fake_output, real_samples, fake_samples, discriminator):
# 基本的Wasserstein距离
d_loss = -torch.mean(real_output) + torch.mean(fake_output)
# 计算梯度惩罚
# 在真实和生成样本之间随机插值
alpha = torch.rand(real_samples.size(0), 1, 1, 1, device=self.device)
interpolates = alpha * real_samples + (1 - alpha) * fake_samples
interpolates.requires_grad_(True)
# 计算判别器对插值样本的输出
d_interpolates = discriminator(interpolates)
# 计算梯度
fake_outputs = torch.ones_like(d_interpolates, device=self.device, requires_grad=False)
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake_outputs,
create_graph=True,
retain_graph=True,
only_inputs=True
)[0]
# 计算梯度L2范数
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
# 添加梯度惩罚项
d_loss = d_loss + self.lambda_gp * gradient_penalty
return d_loss
def generator_loss(self, fake_output):
# 与WGAN相同
g_loss = -torch.mean(fake_output)
return g_loss
6、条件生成对抗网络(CGAN)
CGAN通过在生成器和判别器中引入条件信息y(如类别标签),实现对生成过程的控制: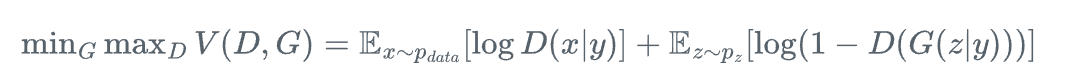
CGAN能够生成特定类别的样本,大大增强了模型的实用性,特别是在医学影像等需要精确控制生成内容的应用场景中。通过条件控制,CGAN可以引导生成过程,使得生成结果满足特定的语义或结构要求,为个性化内容生成提供了可靠技术支持。
PyTorch实现:
class CGANLoss:
def __init__(self, device):
self.device = device
self.criterion = nn.BCELoss()
def discriminator_loss(self, real_output, fake_output):
# 条件GAN的判别器损失与原始GAN相似,只是输入增加了条件信息
real_labels = torch.ones_like(real_output, device=self.device)
fake_labels = torch.zeros_like(fake_output, device=self.device)
real_loss = self.criterion(real_output, real_labels)
fake_loss = self.criterion(fake_output, fake_labels)
d_loss = real_loss + fake_loss
return d_loss
def generator_loss(self, fake_output):
# 与原始GAN相似
target_labels = torch.ones_like(fake_output, device=self.device)
g_loss = self.criterion(fake_output, target_labels)
return g_loss
# CGAN的网络结构示例
class ConditionalGenerator(nn.Module):
def __init__(self, latent_dim, n_classes, img_shape):
super(ConditionalGenerator, self).__init__()
self.img_shape = img_shape
self.label_emb = nn.Embedding(n_classes, n_classes)
self.model = nn.Sequential(
# 输入是噪声向量与条件拼接后的向量
nn.Linear(latent_dim + n_classes, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z, labels):
# 条件嵌入
c = self.label_emb(labels)
# 拼接噪声和条件
x = torch.cat([z, c], 1)
# 生成图像
img = self.model(x)
img = img.view(img.size(0), *self.img_shape)
return img
7、信息最大化GAN(InfoGAN)
InfoGAN在无监督学习框架下实现了对生成样本特定属性的控制,其核心思想是最大化潜在编码c与生成样本G(z,c)之间的互信息: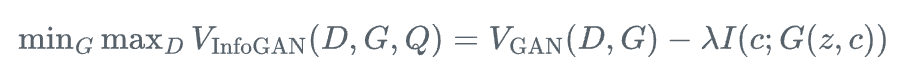
其中Q是一个辅助网络,用于近似后验分布P(c|x),而I(c;G(z,c))表示互信息。InfoGAN能够在无监督的情况下学习数据的解耦表示,对于医学图像分析中的特征提取和异常检测具有潜在价值。
PyTorch实现:
class InfoGANLoss:
def __init__(self, device, lambda_info=1.0):
self.device = device
self.criterion = nn.BCELoss()
self.lambda_info = lambda_info
# 对于离散潜变量使用交叉熵损失
self.discrete_criterion = nn.CrossEntropyLoss()
# 对于连续潜变量使用高斯分布负对数似然
self.continuous_criterion = nn.MSELoss()
def discriminator_loss(self, real_output, fake_output):
# 判别器损失与原始GAN相同
real_labels = torch.ones_like(real_output, device=self.device)
fake_labels = torch.zeros_like(fake_output, device=self.device)
real_loss = self.criterion(real_output, real_labels)
fake_loss = self.criterion(fake_output, fake_labels)
d_loss = real_loss + fake_loss
return d_loss
def generator_info_loss(self, fake_output, q_discrete, q_continuous, c_discrete, c_continuous):
# 生成器损失部分(欺骗判别器)
target_labels = torch.ones_like(fake_output, device=self.device)
g_loss = self.criterion(fake_output, target_labels)
# 互信息损失部分
# 离散潜变量的互信息损失
info_disc_loss = self.discrete_criterion(q_discrete, c_discrete)
# 连续潜变量的互信息损失
info_cont_loss = self.continuous_criterion(q_continuous, c_continuous)
# 总损失
total_loss = g_loss + self.lambda_info * (info_disc_loss + info_cont_loss)
return total_loss, info_disc_loss, info_cont_loss
8、能量基础GAN(EBGAN)
EBGAN将判别器视为能量函数,而非传统的概率函数,其损失函数为: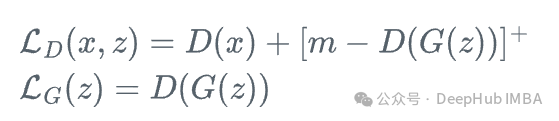
其中[·]^+表示\max(0,·),m是边界参数。EBGAN通过能量视角重新诠释GAN训练过程,为模型设计提供了新的思路,尤其适合处理具有复杂分布的医学数据。EBGAN的判别器不再输出概率值,而是输出能量分数,真实样本的能量应当低于生成样本。
PyTorch实现:
class EBGANLoss:
def __init__(self, device, margin=10.0):
self.device = device
self.margin = margin
def discriminator_loss(self, real_energy, fake_energy):
# 判别器的目标是降低真实样本的能量,提高生成样本的能量(直到边界值)
# 对生成样本的损失使用hinge loss
hinge_loss = torch.mean(torch.clamp(self.margin - fake_energy, min=0))
# 总损失
d_loss = torch.mean(real_energy) + hinge_loss
return d_loss
def generator_loss(self, fake_energy):
# 生成器的目标是降低生成样本的能量
g_loss = torch.mean(fake_energy)
return g_loss
9、f-GAN
f-GAN是一种基于f-散度的GAN框架,可以统一多种GAN变体: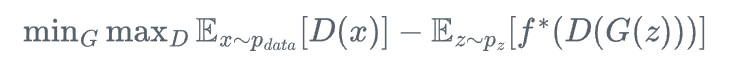
其中f^*是凸函数f的Fenchel共轭。通过选择不同的f函数,f-GAN可以实现对不同散度的优化,如KL散度、JS散度、Hellinger距离等,为特定应用场景提供了更灵活的选择。f-GAN为GAN提供了一个统一的理论框架,使研究者能够根据具体任务需求设计最适合的散度度量。
PyTorch实现:
class FGANLoss:
def __init__(self, device, divergence_type='kl'):
self.device = device
self.divergence_type = divergence_type
def activation_function(self, x):
# 不同散度对应的激活函数
if self.divergence_type == 'kl': # KL散度
return x
elif self.divergence_type == 'js': # JS散度
return torch.log(1 + torch.exp(x))
elif self.divergence_type == 'hellinger': # Hellinger距离
return 1 - torch.exp(-x)
elif self.divergence_type == 'total_variation': # 总变差距离
return 0.5 * torch.tanh(x)
else:
return x # 默认为KL散度
def conjugate_function(self, x):
# 不同散度的Fenchel共轭
if self.divergence_type == 'kl':
return torch.exp(x - 1)
elif self.divergence_type == 'js':
return -torch.log(2 - torch.exp(x))
elif self.divergence_type == 'hellinger':
return x / (1 - x)
elif self.divergence_type == 'total_variation':
return x
else:
return torch.exp(x - 1) # 默认为KL散度
def discriminator_loss(self, real_output, fake_output):
# 判别器损失
# 注意:在f-GAN中,通常D的输出需要经过激活函数处理
activated_real = self.activation_function(real_output)
d_loss = -torch.mean(activated_real) + torch.mean(self.conjugate_function(fake_output))
return d_loss
def generator_loss(self, fake_output):
# 生成器损失
activated_fake = self.activation_function(fake_output)
g_loss = -torch.mean(activated_fake)
return g_loss
总结
本文通过详细分析GAN的经典损失函数及其多种变体,揭示了不同类型损失函数各自的优势:LS-GAN训练稳定性好,WGAN-GP生成图像清晰度高,而条件类GAN如CGAN则在可控性方面表现突出。
这介绍代码对于相关领域的GAN应用具有重要参考价值。未来研究可进一步探索损失函数组合优化策略,以及针对特定图像模态的自适应损失函数设计。