
SWEET-RL(Step-WisE Evaluation from Training-time information,基于训练时信息的逐步评估)是多轮大型语言模型(LLM)代理强化学习领域的重要技术进展。该算法相较于现有最先进的方法,成功率提升了6%,使Llama-3.1-8B等小型开源模型能够达到甚至超越GPT-4O等大型专有模型的性能水平。本文将深入分析SWEET-RL如何改进AI代理在复杂协作任务中的训练方法。
LLM代理与多轮交互机制
LLM代理是经过特定任务微调的大型语言模型,能够作为决策实体与环境或人类进行交互以完成预定目标。多轮交互过程本质上是一系列连续的信息交换,类似于结构化对话,每个交互步骤都朝着最终解决方案递进。这种交互模式可类比于协作规划过程:例如在共同规划旅行时,一方提出目的地建议,另一方提出问题或顾虑,然后初始建议被逐步完善直至形成完整计划。在此类情境中,代理需要学习如何有效贡献,而反馈往往仅在整个交互序列结束时才能获得,这显著增加了训练的复杂性。
强化学习在此情境中发挥关键作用,它使代理能够通过试错方法进行学习,以最大化累积奖励。然而,多轮交互环境中的传统强化学习面临信用分配问题——即难以准确判定长期序列中哪些特定行动导致了最终的成功或失败。对于已经通过大规模文本数据预训练的LLM而言,这一挑战尤为明显,因为它们需要在保持通用泛化能力的同时适应特定任务的要求。
ColBench:协作推理任务的评估基准
ColBench是专为验证LLM代理在协作产物创建过程中的多轮强化学习算法而设计的基准。该基准主要关注后端编程和前端设计两个关键领域,遵循以下核心原则:
ColBench确保任务具有足够的复杂性,要求代理具备推理和泛化能力,从而真实反映实际应用场景。同时,它采用LLM作为人类模拟器和功能评估器,实现了低开销的快速原型设计。
在后端编程任务中,代理最多可与人类模拟器进行10轮交互,从高级需求描述和函数签名开始,最终通过通过全部10个单元测试(二元奖励制:0或1)评估性能。该数据集包含10,000个训练任务和1,000个测试任务,以及来自Llama-3.1-8B/70B-Instruct的15,000个离线交互轨迹。前端设计任务则要求代理设计网页界面,通过计算与参考设计的余弦相似度评估效果,包含10,000个训练任务和500个测试任务,以及来自Llama-3.1-8B和Qwen2-VL-72B的6,000个交互轨迹。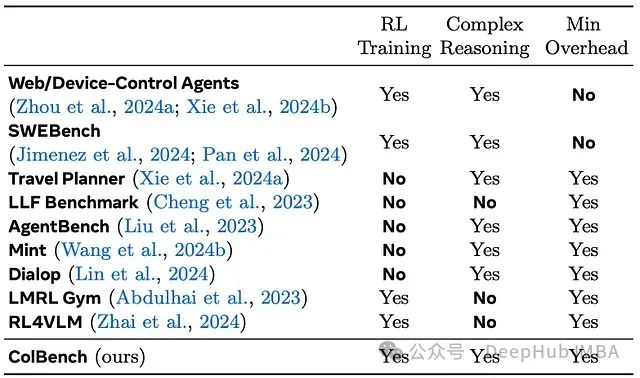
通过与现有多轮LLM代理基准的比较可知,ColBench是唯一同时满足三个关键标准的评估框架:1)具备充分的任务多样性,确保强化学习训练不会过度拟合;2)拥有足够的任务复杂性,能够挑战代理的推理和泛化能力;3)工程开销最小化,适合快速研究原型开发。
多轮LLM代理面临的核心挑战
在当前快速发展的AI技术生态中,构建高效多轮LLM代理是最具挑战性的前沿研究领域之一。这类代理必须能够参与持续的交互过程,做出连贯一致的决策序列,同时保持对长期目标的导向性。传统强化学习方法在应对此类复杂性时面临诸多困难,主要体现在三个方面:跨回合的信用分配问题、对不同任务的泛化能力,以及如何高效利用有限训练数据。
SWEET-RL作为一种创新解决方案,通过根本性改变LLM代理在协作推理任务中的训练方法,有效应对了上述挑战。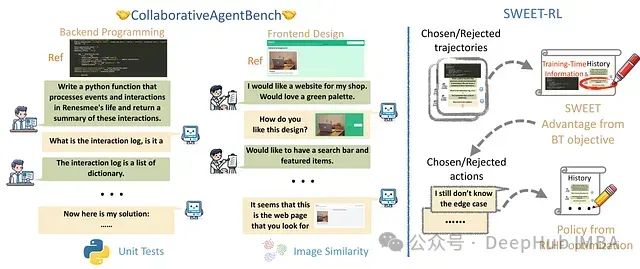
图左展示了ColBench框架概览,包括后端编程和前端设计两个评估任务,支持在真实环境中对代理多轮强化学习算法进行低成本且可靠的评估。图右阐述了SWEET-RL的核心理念,即利用额外的训练时信息结合适当的Bradley-Terry(BT)目标函数实现有效的信用分配。
SWEET-RL的技术创新:核心组件与架构
非对称Actor-Critic结构
SWEET-RL的核心创新在于其非对称actor-critic架构,该架构从根本上改变了代理从经验中学习的方式:
Critic(评估器)可以访问额外的训练时信息,从而提供更精确的行动评估,实现更有效的跨回合信用分配。而Actor(策略网络)则在有限观察条件下运作,根据交互历史做出决策,保持在实际应用场景中的泛化能力。
这种非对称设计使SWEET-RL能够同时获得两种优势:Critic在训练阶段的全面深入理解能力,以及Actor在实际部署中的适用性。
创新的优势函数参数化
SWEET-RL引入了一种新型优势函数参数化方法,显著区别于传统强化学习方法。该方法直接建模优势函数,与LLM预训练目标保持一致,提高了训练稳定性和泛化能力,同时增强了信用分配效率。
两阶段训练流程
该算法实现了精心设计的两阶段训练过程:
第一阶段:回合式Critic训练 - 使用Bradley-Terry目标函数训练Critic,利用训练时信息进行准确评估,根据偏好对优势函数进行优化。
第二阶段:策略改进 - 利用训练好的Critic指导策略更新,实施直接偏好优化的变体算法,确保学习过程稳定高效。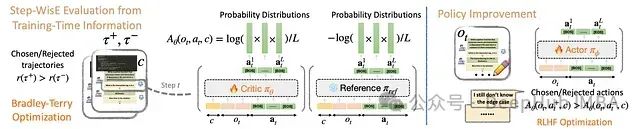
SWEET-RL训练流程概述。在宏观层面,我们首先应用Bradley-Terry目标函数直接训练一个能够访问额外训练时信息的逐步优势函数。优势函数训练完成后,通过将其作为每个回合的奖励模型执行策略改进。
实验性能与应用效果
后端编程任务性能
SWEET-RL在后端编程任务中展现出卓越性能,达到了40.4%的成功率,而多轮DPO方法仅为34.4%;单元测试通过率达到56.8%,显著高于竞争方法的48.0%。
前端设计任务性能
在前端设计场景中,SWEET-RL同样取得了显著进步,与参考解决方案的余弦相似度达到77.7%,对基线方法的胜率为48.2%。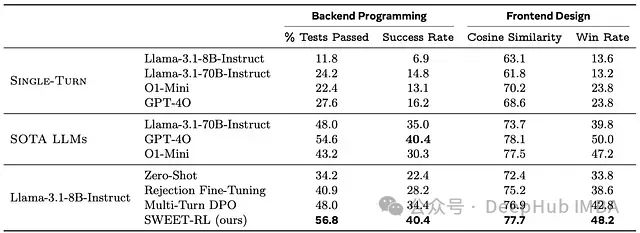
ColBench基准上不同LLM和多轮强化学习算法的性能比较。SWEET-RL相较于其他多轮强化学习算法实现了超过6%的性能提升,使Llama-3.1-8B-Instruct模型能够达到与更大规模专有模型相当的性能水平。
技术优势与创新特点
增强的信用分配机制
SWEET-RL的创新信用分配方法解决了多轮强化学习中最具挑战性的问题之一,通过有效利用训练时信息,提供准确的回合级奖励信号,减少学习信号的方差。
优化的泛化能力
该算法通过与LLM预训练目标保持一致性,展现出卓越的泛化能力,在未见过的任务上表现强劲,并能随训练数据增加而有效扩展。
计算效率优化
SWEET-RL在实现性能提升的同时保持了较高的计算效率,通过直接优势函数建模、稳定的训练动态以及有效利用训练数据实现这一目标。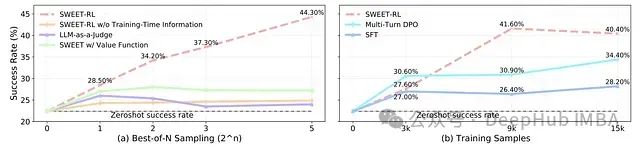
性能比较图表:(a)展示了不同步进奖励模型在后端编程任务上Best-of-N采样的扩展曲线。结果表明SWEET能够在回合基础上最优判断高质量行动,从而实现Best-of-N采样的最佳扩展性能。需注意,此曲线区别于测试时扩展曲线,因为SWEET利用了额外的训练时信息。(b)展示了不同多轮强化学习算法在后端编程任务上随微调数据量增加的性能扩展情况。尽管SWEET-RL初期需要更多数据以学习可靠的Critic,但它能迅速赶上并最终实现更优的收敛性能。
实验表明,利用训练时信息显著增强了信用分配能力,这一点从SWEET-RL与不使用训练时信息的SWEET-RL之间的性能差距得到证实。虽然相对于固定的LLM-as-a-Judge的Best-of-N采样可在零样本成功率上带来一定改进,但这种改进有限。从质性分析看,固定的LLM评判器容易被响应的长度和格式影响,而未能真正关注其对任务成功的实际效用。最后,尽管在深度强化学习文献中较为常见,但价值函数的使用与SWEET-RL相比未能实现相当的扩展性能,这凸显了SWEET-RL在强化学习算法选择上的精心设计,同时表明训练价值函数的常规做法可能在未见过任务上泛化能力较差。
总结
SWEET-RL代表了多轮LLM代理训练技术的重大进展。其在信用分配、优势函数参数化和非对称actor-critic结构方面的创新为该领域确立了新的基准。该算法使小型模型能够实现与大型专有模型相当的性能,成为AI能力民主化进程中的关键一步。
展望未来,SWEET-RL的影响可能超越其当前应用范围,影响更复杂AI系统的开发,特别是需要复杂推理和协作能力的系统。其成功证明了强化学习的持续发展价值及其在构建更强大、更高效AI代理中的重要性。
SWEET-RL通过技术创新、实用性和卓越性能的结合,成为人工智能领域的关键发展,可能深刻影响未来多轮LLM代理和强化学习的研究与发展方向。
代码
https://github.com/FacebookResearch/sweet_rl
作者:Jenray