LLM:模型微调经验
样本数量一般1万左右的高质量样本即可达到良好效果。对于简单任务,100-300条数据足够;中等难度任务需1000条以上;高难度任务需3000条甚至更多,可能达到10万条。样本质量样本质量优先于数量,高质量样本更有效。需要重点关注样本的多样性和答案质量。继续预训练当领域任务数据与预训练数据集差异较大时
基于AIACC加速器快速实现LLaMA-7B指令微调
是Meta AI在2023年2月发布的开放使用预训练语言模型(Large Language Model, LLM),其参数量包含7B到65B的集合,并仅使用完全公开的数据集进行训练。LLM具有建模大量词语之间联系的能力,但是为了让其强大的建模能力向下游具体任务输出,需要进行指令微调,根据大量不同指令
万余字描述国内外主流车型智能驾驶测试评价体验
车企逐鹿城市 NOA,体验是提高功能渗透率的核心自动驾驶大势所趋,小鹏、蔚来、理想、小米等新势力,长安、赛力斯、江淮、北汽等华为系以及吉利、上汽、长城、广汽等传统车企纷纷入场,竞相推出自家城市 NOA 方案,城市 NOA 正从“0-1”步向“1-10”。提高城市 NOA 渗透率,关键是提高消费者
通义千问AI PPT初体验:一句话、万字文档、长文本一键生成PPT!
通义千问AI PPT初体验:一句话、万字文档、长文本一键生成PPT!
OpenAI 的 o1 与 GPT-4o:深入探究 AI 的推理革命
wp:image在不断发展的人工智能领域,OpenAI 再次凭借其最新产品突破界限:o1 模型和 GPT-4o。作为一名几十年来一直报道科技的人,我见过不少伪装成革命的增量更新。但这个?这不一样。让我们拨开炒作的迷雾,看看这些新模型到底带来了什么。
头歌——人工智能(机器学习 --- 决策树1)
决策树的相关概念:决策树是一种可以用于分类与回归的机器学习算法,但主要用于分类。用于分类的决策树是一种描述对实例进行分类的树形结构。决策树由结点和边组成,其中结点分为内部结点和叶子结点,内部结点表示一个特征或者属性,叶子结点表示标签(脑回路图中黄色的是内部结点,蓝色的是叶子结点)。决策树的一个非常大
Mobile-Agent项目部署与学习总结(DataWhale AI夏令营)
你好,我是GISer Liu,一名热爱AI技术的GIS开发者,本文是DataWhale 2024 AI夏令营的最后一期——赛道,这是作者的学习文档,这里总结一下,和作者一起学习这个多模态大模型新项目吧😀;
ConvGRU原理与开源代码
ConvGRU(卷积门控循环单元)是一种结合了卷积神经网络(CNN)和门控循环单元(GRU)的深度学习模型。与ConvLSTM类似,ConvGRU也主要用于处理时空数据,特别适用于需要考虑空间特征和时间依赖关系的任务,如视频分析、气象预测和交通流量预测等。
【面试】如何度量概率分布的相似度
衡量两个概率分布之间差异的非对称度量,常用于变分推断和信息论。KL散度的对称形式,适合度量两个分布的相似度,广泛应用于GANs。衡量两个分布之间的全局差异,特别适合形状匹配和最优传输问题。度量两个分布之间的最大绝对差异,常用于统计检验和概率模型评价。
大模型-基于大模型的数据标注
法来自于这篇论文:Can Generalist Foundation Models Outcompete Special-Purpose Tuning?
【机器学习】标签编码(Label Encoding)、独热编码(One-Hot Encoding)
字符特征转数值特征的两种编码方式
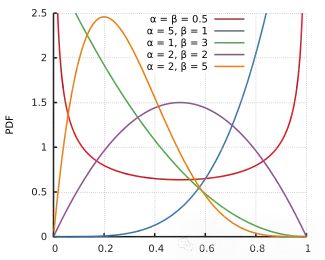
贝叶斯统计中常见先验分布选择方法总结
本文详细介绍了贝叶斯统计中三种常见的先验分布选择方法:经验贝叶斯方法、信息先验和无信息/弱信息先验。
人工智能之机器学习
在1956年众多科学家相聚一起共同探讨并展望未来的科技.首次提出"人工智能"这个专业名词,这一年也被称为人工智能元年......
【AI论文精读5】知识图谱与LLM结合的路线图-P2
该论文提出了一个将大型语言模型(LLMs)与知识图谱(KGs)相结合的路线图。这是我对论文第2部分的解读。
【动物识别系统】Python+卷积神经网络算法+人工智能+深度学习+机器学习+计算机课设项目+Django网页界面
动物识别系统。本项目以Python作为主要编程语言,并基于TensorFlow搭建ResNet50卷积神经网络算法模型,通过收集4种常见的动物图像数据集(猫、狗、鸡、马)然后进行模型训练,得到一个识别精度较高的模型文件,然后保存为本地格式的H5格式文件。再基于Django开发Web网页端操作界面,实
数据预处理:为 AI 准备 “优质食材” 的重要步骤
AI模型数据处理
LocalAI离线安装部署
LocalAI是免费的开源 OpenAI 替代品。LocalAI 可作为替代 REST API,与 OpenAI(Elevenlabs、Anthropic……)API 规范兼容,用于本地 AI 推理。它允许您在本地或使用消费级硬件运行 LLM、生成图像、音频(不止于此),支持多种模型系列。不需要 G
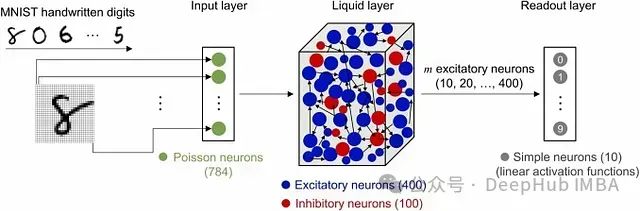
基于Liquid State Machine的时间序列预测:利用储备池计算实现高效建模
**Liquid State Machine (LSM)** 是一种 **脉冲神经网络 (Spiking Neural Network, SNN)** ,在计算神经科学和机器学习领域中得到广泛应用,特别适用于处理 **时变或动态数据**。
LLM Continue Pretrain(2024版)
deepseek的开源moe,也做得非常不错,应该是国内开源top了,他们的pretrain团队做得挺棒的 但算法为主的,做pretrain,往往就是洗数据了。尴尬的点是,预训练洗数据,因为数据量大,往往都是搞各种小模型+规则,很难说明你做的事情的技术含量,只能体现你对数据的认知很好。语言类的dom
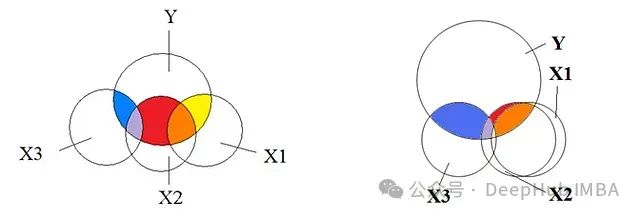
深入理解多重共线性:基本原理、影响、检验与修正策略
本文将深入探讨多重共线性的本质,阐述其重要性,并提供有效处理多重共线性的方法,同时避免数据科学家常犯的陷阱。



