MicroPython 环境下使用 ESP32 连接百度 AI 大模型
本文详细介绍了如何在 MicroPython 环境下,利用 ESP32开发板连接百度AI大模型。初步从硬件准备(ESP32开发板)和软件配置(MicroPython固件和Thonny IDE)开始,指导读者设置一个适合连接百度AI大模型的开发环境。随后,文章通过实际的代码示例,展示了如何在ESP32
《人工智能》
人工智能的概念与定义人工智能的概念与定义。
AI创想家,AI足球(黄金可以打一打)
如果足球在机器人90-180度范围内,设置机器人速度vs为后退-0.8,转动方向hs为左转-0.3。# 如果足球在机器人180-270度范围内,设置机器人速度vs为后退-0.8,转动方向hs为右转0.3。# 如果足球在机器人270-360度范围内,设置机器人速度vs为前进0.8,转动方向hs为右转0
Python前沿技术,机器学习与人工智能的应用
Python,作为一种简洁、易读且功能强大的编程语言,凭借其丰富的库支持和广泛的应用场景,在AI领域占据了举足轻重的地位。本文旨在深入探讨Python在AI领域的前沿技术,包括数据预处理、机器学习算法、深度学习框架等,并通过具体代码案例展示Python在AI应用中的实际效果。
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
本文对transformers之pipeline的图像分类(image-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用计算机视觉中的图像分类(image-classifica
安装 qcloud-python-sts 失败 提示 gbk codecs decode byte 应该如何解决
安装 qcloud-python-sts 失败 提示 gbk codecs decode byte 应该如何解决。
【PyTorch】多对象分割项目
对象分割任务的目标是找到图像中目标对象的边界。实际应用例如自动驾驶汽车和医学成像分析。这里将使用PyTorch开发一个深度学习模型来完成多对象分割任务。多对象分割的主要目标是自动勾勒出图像中多个目标对象的边界。对象的边界通常由与图像大小相同的分割掩码定义,在分割掩码中属于目标对象的所有像素基于预定义
「测试线排查的一些经验-上篇」&& 后端工程师
后端工程师在工作中遇到的一些测试线排查问题与经验总结
蓝桥杯 Python 研究生组-2023-省赛-工作时长
蓝桥账户中心蓝桥账户中心。
arkhamintelligence 请求头加密 X-Payload 完整逆向分析+自动化解决方案
逆向是爬虫工程师进阶必备技能,当我们遇到一个问题时可能会有多种解决途径,而如何做出最高效的抉择又需要经验的积累。本期文章将以实战的方式,带你详细地逆向分析 arkhamintelligence 请求头加密字段 X-Payload 的构造逻辑,包括如何逆向分析、如何准确地找到加密入口、如何模拟执行JS
Python开发: 飞机大战 小游戏
python开发的飞机大战小游戏。
python map
在 Python 中,通常使用字典(dictionary)来实现键值对映射,可以通过.items()方法遍历键值对,或者分别使用.keys()和.values()方法遍历键或值。如果你有其他特定的数据结构或需求,请提供更多信息,我可以进一步帮助你。
【小沐学AI】Python实现语音识别(whisper+HuggingFace)
Whisper 是一种通用语音识别模型。它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。Transformer 序列到序列模型针对各种语音处理任务进行训练,包括多语言语音识别、语音翻译、口语识别和语音活动检测。这些任务共同表示为解码器要预测的一系列
开始认识人工智能(一)
1、什么是张量张量,英文为Tensor,是机器学习的基本构建模块,是以数字方式表示数据的形式。PyTorch就是将数据封装成张量(Tensor)来进行运算的。PyTorch中的张量就是元素为同一种数据类型的多维数组。在PyTorch中,张量以"类"的形式封装起来,对张量的一些运算、处理的方法被封装在
【OpenVoice】AI语音大模型,录制声音即可定制音色
openvoice音色可定制
人工智能之数据科学库sklearn
sklearn,全称scikit-learn,是python中的机器学习库,建立在numpy、scipy、matplotlib等数据科学包的基础之上,涵盖了机器学习中的样例数据、数据预处理、模型验证、特征选择、分类、回归、聚类、降维等几乎所有环节,功能十分强大
如何用Python调用智谱AI的API
智谱AI大模型以GLM(General Language Model)系列为核心,由清华大学、北京智源人工智能研究院等顶尖机构联合研发。这些模型通过自回归填空任务进行预训练,并采用Transformer架构,能够在各种自然语言理解和生成任务上进行微调,展现出强大的语言处理能力。其中,GLM-130B
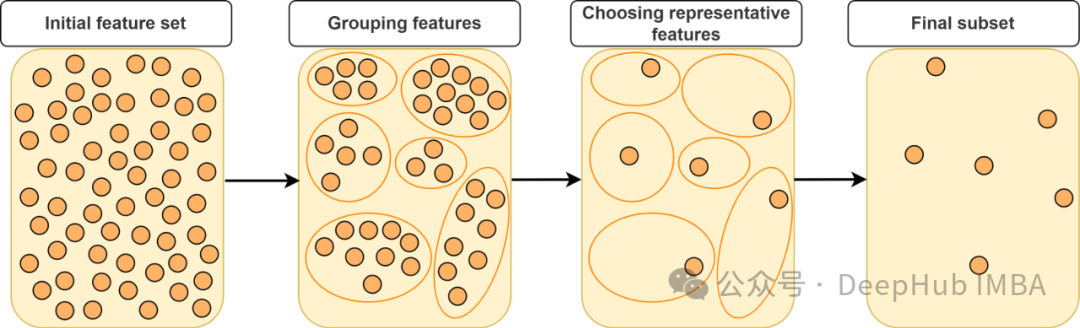
精简模型,提升效能:线性回归中的特征选择技巧
在本文中,我们将探讨各种特征选择方法和技术,用以在保持模型评分可接受的情况下减少特征数量。通过减少噪声和冗余信息,模型可以更快地处理,并减少复杂性。

贝叶斯分析与决策理论:用于确定分类问题决策点的应用
在分类问题中,一个常见的难题是决定输出为数字时各类别之间的切分点。



