
告别低效代码:用对这10个Pandas方法让数据分析效率翻倍
本文将介绍 10 个在数据处理中至关重要的 Pandas 技术模式。这些模式能够显著减少调试时间,提升代码的可维护性,并构建更加清晰的数据处理流水线。
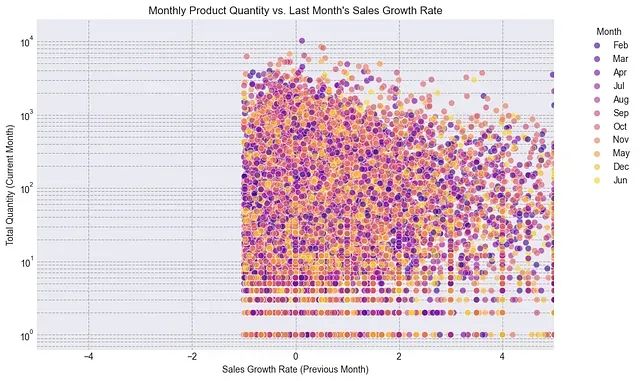
大数据集特征工程实践:将54万样本预测误差降低68%的技术路径与代码实现详解
本文通过实际案例演示特征工程在回归任务中的应用效果,重点分析包含数值型、分类型和时间序列特征的大规模表格数据集的处理方法。
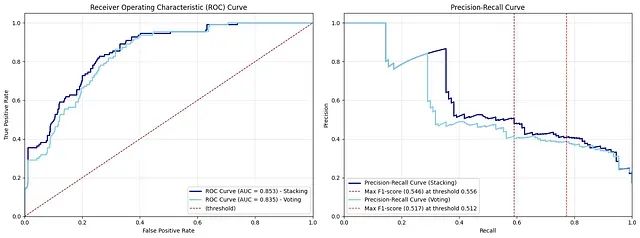
朴素贝叶斯处理混合数据类型,基于投票与堆叠集成的系统化方法理论基础与实践应用
本文深入探讨朴素贝叶斯算法的数学理论基础,并重点分析其在处理混合数据类型中的应用。
通过MongoDB Atlas 实现语义搜索与 RAG——迈向AI的搜索机制
MongoDB Atlas 的向量搜索功能为语义搜索和 RAG 提供了一个高效的数据库管理平台。在这个全新的应用场景下,Atlas 的向量检索能力支持开发者实现高效的知识检索和增强型生成应用,使其在智能客服、知识问答、个性化推荐等场景中大放异彩。结合生成式模型的 RAG 应用,MongoDB Atl
数据分析工具julius ai如何使用
虽然openai也支持生成图表,但是julius ai这类专门用于数据分析的工具,可以支持更加复制一些的数据处理功能,准确率也更高。但是这些软件也是基于llm+agent的模型,一款工具也不是万能的。大多数大模型只支持python语言,支持r语言的ai数据分析工具还不多。julius ai就支持py
【NVIDIA NIM 黑客松训练营】基于NVIDIA NIM 平台提供的免费GPU和AI大模型能力实现数据分析问答系统
NVIDIA提供了免费的GPU和AI算力,旨在向各大公司及开发者推广自己的AI能力,开发者首次体验会免费提供1000个Credits left和至少个大模型[“mistralai/mistral-7b-instruct-v0.2”, “meta/llama-3.1-405b-instruct”]。由
fastMNN|手把手教你理解和实现单细胞批次效应校正方法
fastMNN是MNN的升级版,主要改动是fastMNN采用PCA降维之后的低维空间计算细胞之间的距离,而MNN直接使用原始表达矩阵计算细胞之间的距离,因此分析速度会更快。MNN使用假设:(i)至少有一个细胞群同时存在于两个批次中,(ii)批次效应几乎与生物子空间正交,(iii)批次效应变化远小于不
人工智能在病理切片虚拟染色及染色标准化领域的系统进展分析|文献速递·24-07-07
这篇文章介绍了一个自动化的端到端深度学习框架,用于从未经染色的病理图像中进行分类和肿瘤定位。研究由Akram Bayat、Connor Anderson和Pratik Shah等人完成,并发表在2021年SPIE医学成像会议的图像处理卷中。背景与挑战:传统的组织病理学图像分析依赖于染色技术,但存在样
万字详解AI实践,零手写编码用AI完成开发 + 数据清洗 + 数据处理 的每日新闻推荐,带你快速成为AI大神
全程不需要自己写一行代码,我们就完成了前后端开发和数据处理、数据清洗。实际上这也是未来的趋势,在AI的加持下,我们每一个人的能力都会被无限放大,早日尝试并习惯高效使用AI才能帮助我们在新时代的变革中保持竞争力。
人工智能时代,程序员如何保持核心竞争力?
人工智能时代,程序员保持核心竞争力的三大杀器
全新神经网络架构KAN回归分析:PDP(部分依赖图)、ICE(个体条件期望)解释教程
这里创建一个KAN:8D输入(自变量),1D输出(因变量),2个隐藏的神经元,三次样条 (k=3),3个网格间隔 (grid=3),读者可以利用网格细化来最大限度地提高 KAN 的拟合功能能力,修改网格间隔得到更细粒度的KAN,以及修改其它参数来增加模型拟合度,这里就不去展示如何去进行模型调参,接下
IJCAI 2024 | 时空数据(Spatial-Temporal)论文总结
2024 IJCAI(International Joint Conference on Artificial Intelligence, 国际人工智能联合会议)在2024年8月3日-9日在举行。本文总结了IJCAI2024有关的相关论文,如有疏漏,欢迎大家补充。:时空(交通)预测,气象预测,轨迹
2024年值得收藏的AI数据分析工具
人工智能(AI)数据分析工具正变得越来越重要,通过自然语言处理、机器学习和高级数据可视化技术,使数据探索、分析和决策过程变得更加高效和直观。
【干货】5款超强大的AI数据分析工具,建议收藏
它和其他Excel的AI公式生成不一样,它会直接执行命令,无需你获取公式后再复制操作,这对于不会用Excel或是Excel公式不熟练的小伙伴相当友好!也是一款在线 AI Excel 编辑器工具,无需学习Excel繁琐的操作和公式,只需输入简单的提示语,自动进行数据操作或编写公式,非常方便地提高效率!
【好货分享】开源AI平台Dify,一站式litGPT,一行代码数据分析ydata
其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产。erdantic 是一个简单的工具,用于绘制实体关系图 (ERD),以显示数据模型类是如何连接的。YData-profiling 是数据科学工作流程中数据理解步骤中的领先工具,是开创性的
5本又快又水的sci期刊丨sci期刊推荐
值得注意的是:学术界近期动荡比较大,又快又水的sci被踢出的风险非常大,各自的出版商大都在积极地应对和调整,导致水刊的发表难度有所提升。同时,发表sci水刊的风险较大,也建议作者不要盲目的冒险,否则就成了能不能毕业的问题了。PLoS One是综合性开源SCI期刊,对稿件创新性或研究重要性的要求比较低
似不相关回归模型及 Stata 具体操作步骤
似不相关回归(Seemingly Unrelated Regression,SUR)模型在处理多个相关方程的回归分析中具有重要作用。它能够更有效地利用方程之间的相关性,从而提供更精确的估计结果。
基于ResNet50实现垃圾分类
ResNet50是Residual Networks(残差网络)的一种变体,由Kaiming He等人在2015年提出。ResNet50包含50个深度层,通过引入残差模块,有效地解决了深层网络的退化问题。残差模块通过引入短连接(skip connections)使得网络在训练时更容易优化。下图在下文
什么是自回归模型
自回归模型(Autoregressive Model, AR模型)是时间序列分析中的一种基本模型,其核心思想是当前观测值可以通过其过去的若干个观测值的加权和来预测,其中的权重参数由数据自身决定。数学上,一个自回归模型可以表示为:Xtcϕ1Xt−1ϕ2Xt−2⋯ϕpXt−pϵtXtcϕ1Xt−1
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
本文对transformers之pipeline的文本生成(text-generation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用NLP中的文本生成(text-generation)模型。



