
对于 Python 数据处理的初学者而言,早期的 Pandas 代码往往充斥着基础的
.head()
、
.dropna()
调用以及大量的在线搜索。然而,掌握一些核心的处理模式后,Pandas 将展现出其快速、表达力强且优雅的特性。
本文将介绍 10 个在数据处理中至关重要的 Pandas 技术模式。这些模式能够显著减少调试时间,提升代码的可维护性,并构建更加清晰的数据处理流水线。
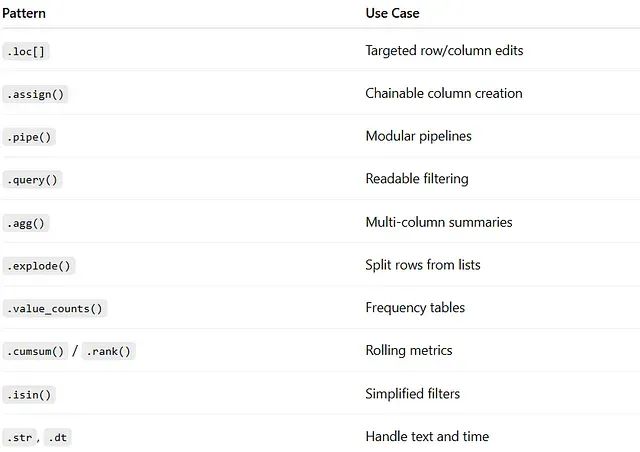
使用 .loc[]`进行精确的行列操作
df.loc[df["status"] =="active", "score"] =100
.loc[]
提供了行过滤与列赋值的统一接口,是进行条件性数据修改的标准方法。相比链式索引操作(如
df[df["x"] > 0]["y"] = ...
),使用
.loc[]
能够避免 SettingWithCopyWarning 警告以及潜在的数据一致性问题。
使用 .assign()实现链式列创建
df=df.assign(conversion_rate=df["sales"] /df["visits"])
.assign()
方法支持在方法链中动态添加新列,这种方式特别适合函数式编程风格的数据处理流水线。与直接赋值相比,该方法返回 DataFrame 的副本,确保了数据处理的不可变性。
使用 .pipe()构建可复用的处理流水线
(df
.pipe(clean_column_names)
.pipe(drop_null_revenue)
.pipe(convert_types)
)
.pipe()
方法允许将自定义函数无缝集成到方法链中,这种模式促进了代码的模块化和可重用性。通过将复杂的数据处理逻辑封装在独立的函数中,代码结构变得更加清晰和易于维护。
使用 .query()提升过滤操作的可读性
df.query("region == 'APAC' and revenue > 5000")
.query()
方法使用字符串表达式进行数据过滤,其语法接近自然语言,特别适合复杂的多条件过滤场景。相比传统的布尔索引,该方法在处理多重条件时具有更好的可读性和编写效率。
使用 .agg() 进行多维度数据聚合
df.groupby("region").agg(
total_sales=("sales", "sum"),
avg_price=("price", "mean")
)
结合
groupby()
和
.agg()
可以实现对多个列的不同聚合操作,并为结果指定清晰的列名。这种方式比使用多个单独的聚合操作更加高效,同时提供了更好的结果可读性。
使用 .explode()处理嵌套数据结构
df["tags"] =df["tags"].str.split(", ")
df=df.explode("tags")
.explode()
方法专门用于处理包含列表或数组的单元格,将其转换为多行数据。这种转换在处理标签、分类或其他多值字段时非常有用,是规范化数据结构的重要技术。
使用 value_counts()进行快速频率分析
df["browser"].value_counts(normalize=True)
value_counts()
是进行分类数据频率分析的标准方法,支持归一化选项以获得相对频率。该方法在数据探索和分类变量分析中发挥着重要作用。
使用累积和排名函数生成衍生指标
df["running_total"] =df["sales"].cumsum()
df["rank"] =df["score"].rank(ascending=False)
.cumsum()
和
.rank()
等窗口函数能够基于现有数据生成动态的衍生指标。累积函数在时间序列分析中特别有用,而排名函数则常用于评分和排序场景。
使用 .isin()优化成员资格检查
df[df["country"].isin(["USA", "UK", "Canada"])]
.isin()
方法提供了高效的成员资格检查功能,相比使用多个逻辑或条件的组合,该方法具有更好的性能和可扩展性,特别适合处理大量候选值的过滤场景。
利用 .str 和 .dt访问器处理专门数据类型
df["email_domain"] =df["email"].str.split("@").str[-1]
df["month"] =df["signup_date"].dt.month
.str
访问器提供了丰富的字符串处理功能,而
.dt
访问器则专门用于日期时间数据的操作。这些专门的访问器使得复杂的数据类型处理变得简洁而高效。
综合应用:构建完整的数据处理流水线
将上述技术模式结合使用,可以构建出清晰、高效的数据处理流水线:
(df
.assign(month=df["date"].dt.to_period("M"))
.query("status == 'active'")
.groupby("month")
.agg(avg_sales=("sales", "mean"))
.reset_index()
)
这种方法链式调用的风格不仅提高了代码的可读性,还增强了数据处理流程的可重用性和可维护性。
总结
掌握这些核心的 Pandas 技术模式将显著提升数据处理的效率和代码质量。通过合理运用这些模式,可以构建出更加专业、可维护的数据分析解决方案。
作者:Nikulsinh Rajput