Flink原理与代码实例讲解
Flink原理与代码实例讲解1.背景介绍1.1 什么是FlinkApache Flink是一个开源的分布式流处理和批处理框架,由Apache软件基金会开发。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可
labelme用AI模型时闪退(win10系统)
解决win10系统中实用labelme的ai标注闪退问题
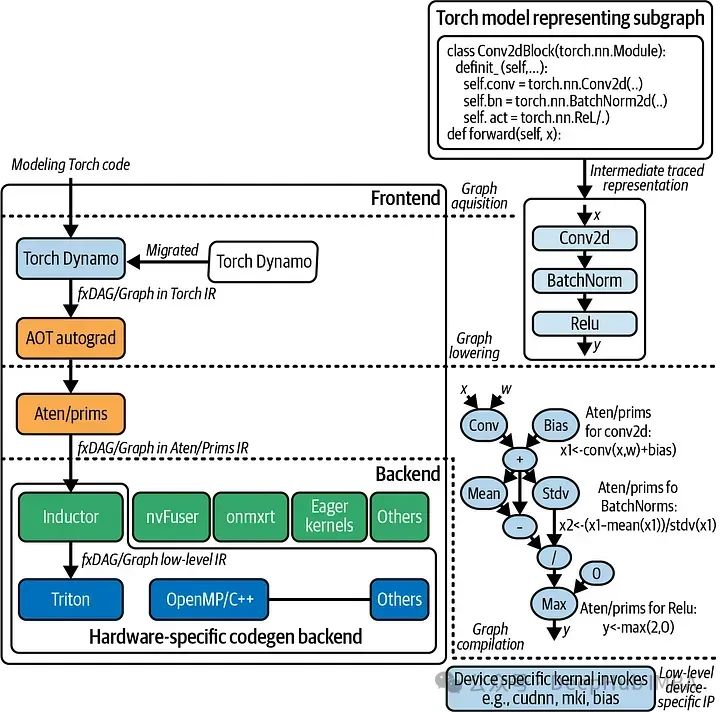
Pytorch的编译新特性TorchDynamo的工作原理和使用示例
TorchDynamo 是一个由 PyTorch 团队开发的编译器前端,它旨在自动优化 PyTorch 程序以提高运行效率。
【大模型应用开发 动手做AI Agent】思维树
【大模型应用开发 动手做AI Agent】思维树1. 背景介绍1.1 人工智能的发展历程1.1.1 早期的人工智能研究1
【人工智能】博弈搜索(极小极大值、α-β剪枝)
本文主要介绍了极小极大值算法与α-β算法的原理及实现。

注意力机制中三种掩码技术详解和Pytorch实现
在这篇文章中,我们将探索在注意力机制中使用的各种类型的掩码,并在PyTorch中实现它们。
IT入门知识第九部分《人工智能》(9/10)
人工智能,简称AI,是计算机科学的一个分支,它致力于创建能够执行通常需要人类智能的任务的系统。这些任务包括语言理解、学习、推理、规划、感知、运动和操作。人工智能(AI)是计算机科学的一个分支,它旨在创建能够执行通常需要人类智能的任务的系统。这些系统能够模仿人类的学习方式、决策过程和解决问题的能力。A
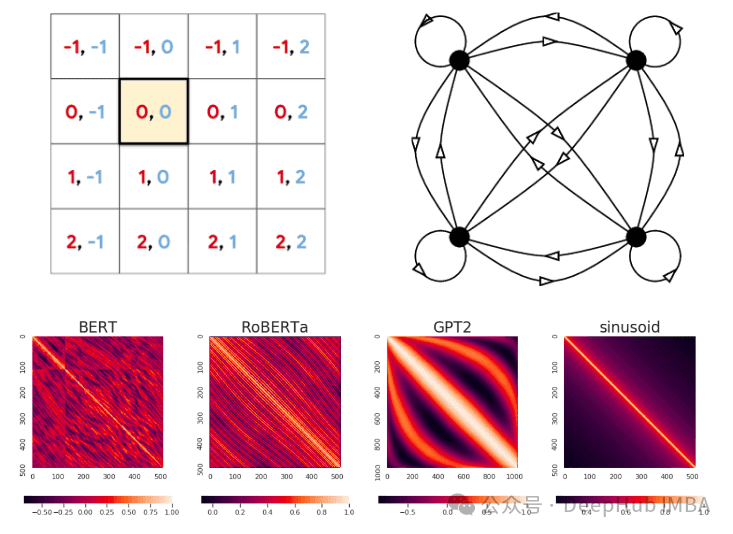
Transformer中高级位置编码的介绍和比较:Linear Rope、NTK、YaRN、CoPE
绝对和相对位置编码是最常见的两种位置编码方式,但是本文将要比较更高级的位置编码方法: 1、RoPE 位置编码及其变体 2、CoPE
人工智能演进之路:神经网络两落三起
本文我将以"人工智能演进之路:神经网络两落三起"为标题,撰写一篇详细的技术博客文章。这篇文章将深入探讨神经网络在人工智能发展历程中的起起落落,以及其对AI领域的深远影响。我会严格遵循您提供的约束条件和内容要求。下面是文章的正文内容:人工智能(AI)作为计算机科学的一个重要分支,自20世纪50年代诞生
人工智能|深度学习——PlotNeuralNet简单教程
是一个强大的开源Python库,它专为简化和美化神经网络图的绘制而设计。
基于 YOLOv5 的疲劳驾驶预警系统:保障行车安全的创新技术
python深度学习基于YOLOv5的疲劳驾驶预警系统(Python源码+疲劳检测数据集+远程部署安装)项目源码请私信,切记留下联系方式。免费预约部署项目在现代社会,汽车已成为人们日常出行和交通运输的重要工具。然而,随着车辆数量的不断增加和驾驶时间的延长,疲劳驾驶问题日益凸显,成为导致交通事故的重要
Flink原理与代码实例讲解
Flink原理与代码实例讲解1. 背景介绍1.1 大数据处理的挑战在当今大数据时代,海量数据的实时处理和分析已成为企业的迫切需求。传统的批处理框架如Hadoop MapReduce难以满足实时性要求,而Storm等流处理框架虽然实时性较
开源模型应用落地-chatglm3-6b-gradio-入门篇(七)
使用gradio搭建AI交互界面
【人工智能】深度学习:神经网络模型
神经网络(Neural Network)是一种模拟人脑神经元连接方式的计算模型。其基本组成部分是神经元(Neurons),通过加权连接和激活函数构成复杂的网络结构。神经网络广泛应用于模式识别、分类和回归等领域。
毕业设计选题:基于深度学习狗狗品种识别系统 人工智能 机器学习 python 目标检测
毕业设计选题-基于深度学习的犬类识别系统。融合深度学习和计算机视觉技术,能准确识别和分类犬类图像。通过大规模犬类图像数据的训练和优化,系统能够高精度地识别不同品种的犬类。。对即将毕业的计算机专业学生来说,提供了有意义的研究课题。不论你对深度学习、机器学习、算法或人工智能感兴趣,该设计为你提供了丰富的
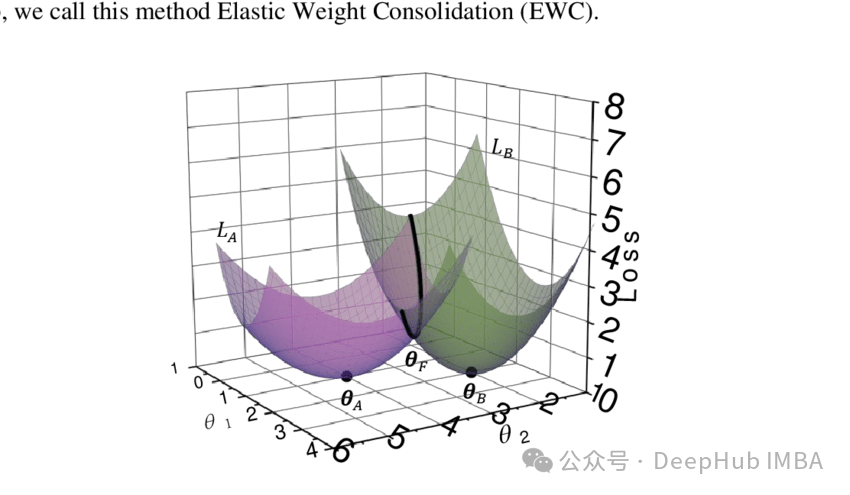
持续学习中避免灾难性遗忘的Elastic Weight Consolidation Loss数学原理及代码实现
Elastic Weight Consolidation。EWC提供了一种很有前途的方法来减轻灾难性遗忘,使神经网络在获得新技能的同时保留先前学习任务的知识。
Kafka的化学物质与环境数据分析
在当今工业化的社会背景下,人类活动对自然环境产生了深远的影响。污染已成为全球关注的重大问题之一。特别是空气和水体污染,不仅威胁着生态平衡,也直接影响了人类健康。为了有效监测并管理这些污染物,科学家们开发了一系列先进的技术和方法,其中一种引人瞩目的方式是利用Kafka作为数据收集和传输的核心组件。本文
Windows和Linux系统上的Mamba_ssm环境配置
DockHub仓库地址:https://hub.docker.com/repository/docker/kom4cr0/cuda11.7-pytorch1.13-mamba1.1.1/general。最直接的安装,可以利用网友配置好的Docker环境 -> 直接使用Mamba基础环境docker镜
Kafka未来趋势:云原生与边缘计算
Kafka未来趋势:云原生与边缘计算1. 背景介绍在数据驱动的时代,Apache Kafka已经成为企业中数据流动的关键组件。作为一个分布式流处理平台,Kafka允许实时数据的收集、存储、处理和分析。随着云计算和边缘计算的兴起,Kafka的应用场景和架构也在不断演进。云原生的概念推
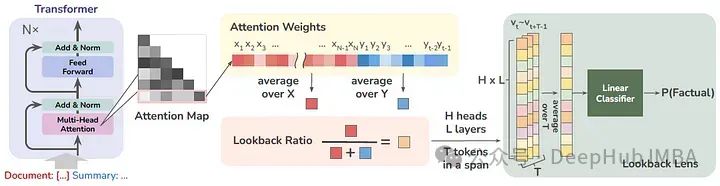
Lookback Lens:用注意力图检测和减轻llm的幻觉
这篇论文的作者提出了一个简单的幻觉检测模型,其输入特征由上下文的注意力权重与新生成的令牌(每个注意头)的比例给出。



